Maschinelles Sehen
"Azure Maschinelles Sehen" bietet Entwicklern erweiterte Algorithmen, die Bilder verarbeiten und Informationen zurückgeben. Um ein Bild zu analysieren, können Sie entweder ein Bild hochladen oder eine Bild-URL angeben. Die Verarbeitungsalgorithmen können den Inhalt von Bildern auf unterschiedliche Weise analysieren, abhängig von verschiedenen visuellen Merkmalen. Beispielsweise kann "Maschinelles Sehen" alle menschlichen Gesichter in einem Bild suchen. Weitere Informationen finden Sie auf der Azure-Website unter Maschinelles Sehen.
Verwenden Sie die Aktion Maschinelles Sehen, um ein Bild zu analysieren, ein Bild nach Domäne zu analysieren, ein Bild zu beschreiben und Erkenntnisse über die visuellen Merkmale und Eigenschaften eines Bildes zu gewinnen und bereitzustellen.
Stellen Sie sicher, dass Ihr Bild die folgenden Anforderungen erfüllt:
• JPEG-, PNG-, GIF- oder BMP-Format.
• Die Dateigröße ist kleiner als 4 MB.
• Die Bemaßungen liegen zwischen 50 x 50 Pixel und 4200 x 4200 Pixel.
• Die Größe beträgt maximal 10 Megapixel.
Führen Sie die folgenden Schritte aus, um die Aktion Maschinelles Sehen in Ihrem Workflow zu verwenden:
1. Ziehen Sie die Aktion Maschinelles Sehen unter Azure in den Zeichenbereich, zeigen Sie mit der Maus auf die Aktion, und klicken Sie dann auf  . Oder: Doppelklicken Sie auf die Aktion. Das Fenster "Maschinelles Sehen" wird geöffnet.
. Oder: Doppelklicken Sie auf die Aktion. Das Fenster "Maschinelles Sehen" wird geöffnet.
. Oder: Doppelklicken Sie auf die Aktion. Das Fenster "Maschinelles Sehen" wird geöffnet.2. Bearbeiten Sie bei Bedarf die Beschriftung. Standardmäßig ist der Beschriftungsname mit dem Aktionsnamen identisch.
3. Informationen zum Hinzufügen eines Azure-Konnektortyps finden Sie unter Unterstützte Azure-Konnektortypen.
Wenn Sie zuvor einen Konnektortyp hinzugefügt haben, wählen Sie den entsprechenden Konnektortyp aus, und wählen Sie unter Konnektor-Name den Konnektor aus.
4. Klicken Sie auf TESTEN, um den Konnektor zu validieren.
5. Klicken Sie auf KONNEKTOR ZUORDNEN, um die Aktion mit einem anderen Konnektor auszuführen als dem, den Sie zum Füllen der Eingabefelder verwenden. Geben Sie im Feld Laufzeit-Konnektor einen gültigen Azure-Konnektor-Namen an. Weitere Informationen zu KONNEKTOR ZUORDNEN finden Sie unter Using Map Connector.
Wenn Sie für Konnektortyp die Option Kein ausgewählt haben, ist die Option KONNEKTOR ZUORDNEN nicht verfügbar.
6. Wählen Sie in der Liste Ressourcengruppe die entsprechende Ressourcengruppe aus, die unter Ihrem Azure-Abonnement definiert ist.
7. Wählen Sie im Feld Maschinelles Sehen-Konto das entsprechende Maschinelles-Sehen-Konto aus.
8. Wählen Sie in der Liste Bild bereitstellen via eine der folgenden Optionen aus, und gehen Sie wie folgt vor:
◦ Wählen Sie URL aus, und geben Sie im Feld Bild-URL eine öffentlich zugängliche Bild-URL an.
◦ Wählen Sie Datei hochladen aus, und ordnen Sie im Feld Bilddateipfad die Ausgabe einer vorherigen Aktion zu, um den Pfad zu einem Bild anzugeben.
9. Wählen Sie in der Liste Bestimmten Dienst auswählen je nach Art der Bildanalyse, die Sie ausführen möchten, einen der folgenden Maschinelles Sehen-Dienste aus, und führen Sie die entsprechende Aufgabe durch:
Dienst | Aufgabe |
|---|---|
Bild analysieren – Extrahiert einen umfangreichen Satz visueller Merkmale aus dem Bild. | a. Wählen Sie in der Liste Visuelle Merkmale die für die Bildanalyse zu verwendenden Merkmale aus: ◦ Kategorien – Kategorisiert den Bildinhalt gemäß der Kategorietaxonomie. ◦ Beschreibung – Beschreibt den Bildinhalt mit einem vollständigen Satz. ◦ Farbe – Bestimmt, ob das Bild schwarz und weiß oder farbig ist, und erkennt bei farbigen Bildern die dominierenden und Akzentfarben. ◦ Tags – Kennzeichnet das Bild mit einer detaillierten Liste von Wörtern, die sich auf den Bildinhalt beziehen. ◦ Gesichter – Erkennt, ob Gesichter im Bild vorhanden sind. ◦ Bildtyp – Erkennt, ob ein Bild eine ClipArt-Grafik oder eine Strichzeichnung ist. ◦ Jugendgefährdend – Erkennt, ob das Bild pornografischer Natur ist oder sexuell anzügliche Inhalte darstellt. ◦ Objekte – Erkennt verschiedene Objekte im Bild. Klicken Sie auf Hinzufügen, um mehrere visuelle Merkmale hinzuzufügen. Klicken Sie auf  , um hinzugefügte visuelle Merkmale zu löschen. , um hinzugefügte visuelle Merkmale zu löschen.b. Klicken Sie unter Details auf Hinzufügen, und wählen Sie dann eines der folgenden domänenspezifischen Details aus, das Sie einschließen möchten: ◦ Prominente – Identifiziert Prominente, sofern diese im Bild erkannt wurden. ◦ Sehenswürdigkeiten – Identifiziert markante Sehenswürdigkeiten im Bild. Klicken Sie auf Hinzufügen, um mehrere Details hinzuzufügen. Klicken Sie auf , um hinzugefügte Details zu löschen. |
Bild nach Domäne analysieren – Erkennt Inhalt aus einem Bild, indem ein domänenspezifisches Modell angewendet wird. | a. Geben Sie im Feld Modell das domänenspezifische Modell an, das zum Analysieren des Bildes verwendet werden muss. b. Wählen Sie im Feld Sprache die Sprache aus, in der Sie die Ausgabe generieren möchten. Standardmäßig ist Englisch ausgewählt. |
Bild beschreiben – Beschreibt den Inhalt des Bildes in lesbaren vollständigen Sätzen. | a. Geben Sie im Feld Max. Kandidaten die maximale Anzahl von Kandidatenbeschreibungen ein, die der Dienst zurückgeben muss. b. Wählen Sie in der Liste Sprache die Sprache aus, in der Sie die Ausgabe generieren möchten. Standardmäßig ist Englisch ausgewählt. |
Objekte erkennen – Führt eine Objekterkennung für das Bild durch. | Keine Maßnahme erforderlich. |
Miniaturansicht generieren – Erzeugt eine Miniaturansicht des angegebenen Bildes. | a. Geben Sie im Feld Breite die Breite der Miniaturansicht zwischen 1 und 1.024 Pixel an. Es wird empfohlen, einen Wert von mindestens 50 anzugeben. b. Geben Sie im Feld Höhe die Höhe der Miniaturansicht zwischen 1 und 1.024 Pixel an. Es wird empfohlen, einen Wert von mindestens 50 anzugeben. c. Wählen Sie wahr in der Liste Intelligentes Zuschneiden aus, um das intelligente Zuschneiden zu aktivieren. Wählen Sie falsch aus, wenn Sie das intelligente Zuschneiden nicht aktivieren möchten. |
Gedruckten Text extrahieren (OCR) – Erkennt Text in einem Bild und extrahiert die erkannten Zeichen in einen maschinenlesbaren Zeichen-Stream. | a. Wählen Sie in der Liste Sprache die Sprache des Textes im Bild aus. Standardmäßig ist Unbekannt ausgewählt. b. Wählen Sie in der Liste Ausrichtung erkennen die Option wahr aus, um die Textausrichtung im Bild zu erkennen und vor der weiteren Verarbeitung zu korrigieren. Wählen Sie falsch aus, wenn der Dienst die Textausrichtung im Bild nicht erkennen soll. |
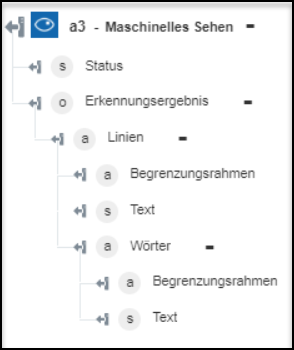
Handschriftlichen Text extrahieren – Extrahiert handschriftlichen Text aus einem Bild. | Keine Maßnahme erforderlich. |
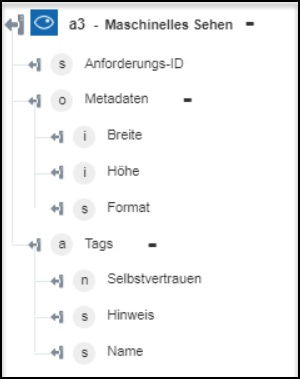
Bild-Tag – Generiert eine Liste von Tags, die für den Inhalt des Bildes relevant sind. | Wählen Sie in der Liste Sprache die Sprache aus, in der Sie die Ausgabe generieren möchten. Standardmäßig ist Englisch ausgewählt. |
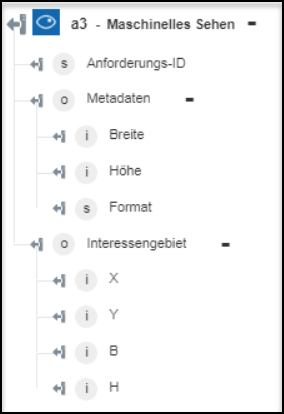
Interessengebiet abrufen – Gibt einen Begrenzungsrahmen um den wichtigsten Bereich des Bildes zurück. | Keine Maßnahme erforderlich. |
10. Klicken Sie auf Fertig.
Ausgabeschema
Jeder Maschinelles Sehen-Dienst verfügt über ein eigenes Ausgabeschema.
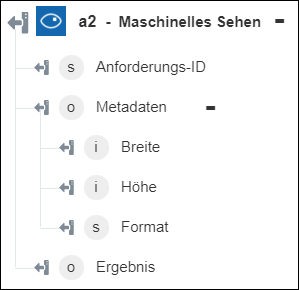
◦ Bild analysieren – Gibt die ausgewählten visuellen Merkmale zurück.
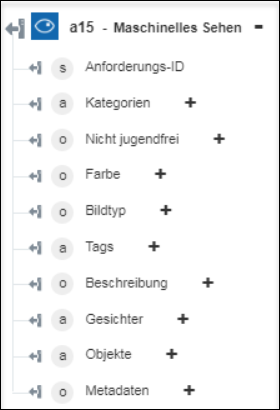
◦ Bild nach Domäne analysieren – Gibt den erkannten Inhalt im Bild zurück.
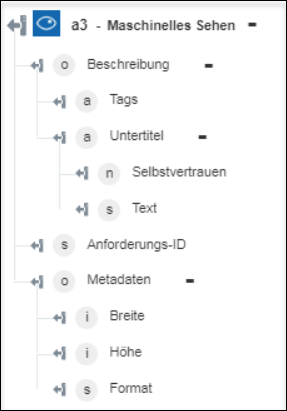
◦ Bild beschreiben – Gibt die Beschreibung des Bildes zurück.
◦ Objekte erkennen – Gibt die Objekte und ihre Koordinaten zurück.
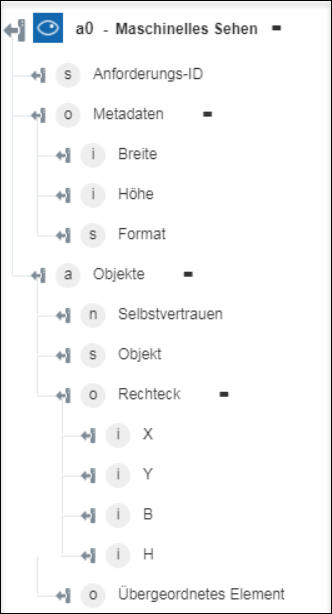
◦ Miniaturansicht generieren – Gibt das Miniaturansicht-Bild zurück.

◦ Gedruckten Text extrahieren (OCR) – Gibt den extrahierten Text aus dem Bild zurück.
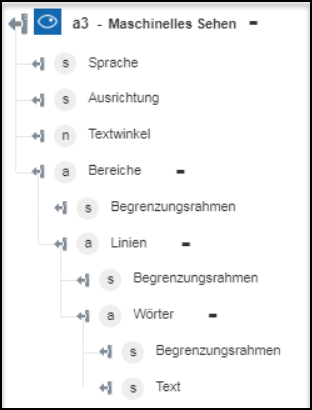
◦ Handschriftlichen Text extrahieren – Gibt den handschriftlichen Text aus dem Bild zurück.
◦ Bild-Tag – Gibt die erkannten Tags für das Bild zurück.
◦ Interessengebiet abrufen – Gibt die Koordinaten um den wichtigsten Bereich des Bildes zurück.