Datenspeicheroptionen
PTC unterstützt die folgenden Speicheroptionen:
• Modellanbieter
• Datenanbieter
|
|
Ab Version 8.5.0 von ThingWorx Platform wird DataStax Enterprise nicht mehr verkauft und in einer zukünftigen Version nicht unterstützt. Weitere Informationen finden Sie im Artikel
ThingWorx persistence provider SAP-HANA notification for End-of-Sale (EOS).
|
H2
H2 ist eine relationale Open Source-Datenbank mit einem niedrigen Festplatten-Footprint. Sie ist in Java geschrieben und kann in Java-Anwendungen eingebettet oder im Client-Server-Modus ausgeführt werden und stellt eine JDBC-API zur Verfügung. H2 erfüllt sowohl die Modell- als auch die Datenanbieter-Anforderungen für ThingWorx. ThingWorx öffnet eine persistente H2-Datenbank (im Gegensatz zu einer In-Memory-Datenbank) im eingebetteten Modus. Dies ist der schnellste und einfachste Verbindungsmodus, die Datenbank ist jedoch nur in der derselben JVM wie Tomcat mit der JDBC verwendenden ThingWorx Web-Anwendung geöffnet. (Externe Prozesse können keine Verbindung zu dieser Datenbankinstanz herstellen oder diese verwenden.) Da es sich um eine persistente Datenbank handelt, werden die Daten auf die lokale Festplatte (im Ordner database in ThingworxStorage) geschrieben und nach dem ThingWorx Neustart beibehalten.
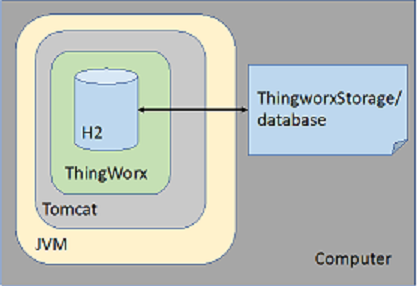
Typische Anwendungsfälle
• Testversionen, Entwicklersysteme, Proof of Concepts, Near-Edge-Geräte
• Für Einzelserver-Bereitstellungen
Beschränkungen
H2 wird aufgrund seiner eingebetteten Natur nicht für die Verwendung in der Produktion empfohlen:
• Begrenzte Skalierbarkeit, da Ressourcen (CPU, Speicher, Festplatte usw.) mit der Anwendung geteilt werden
• Beeinträchtigung der Stabilität der gesamten Anwendung Beispiel: Stürzt Tomcat ab oder wird der Tomcat-Prozess beendet, so werden auch die Datenbankprozesse beendet, was zu Datenbeschädigung führen kann.
• Es ist schwieriger, Leistungsprobleme durch Isolieren von Engpässen im Anwendungscode oder in der Datenbank zu beheben.
• Aus Sicht der allgemeinen Operationen sowie der Verwaltung können die Visualisierung von Daten, Sicherungen und Notfallwiederherstellung schwieriger zu verwalten sein.
Informationen zur Verwendung von H2 als Persistenzanbieter für ThingWorx finden Sie unter
H2 als Persistenzanbieter verwenden.
PostgreSQL
PostgreSQL ist ein objektrelationales Datenbankverwaltungssystem (ORDBMS) unter Open Source-Lizenz mit Schwerpunkt auf Erweiterbarkeit und Einhaltung von Normen. Als Datenbankserver besteht seine Hauptfunktion darin, Daten sicher zu speichern und diese abzurufen, wenn sie von anderen Software-Anwendungen angefordert werden. PostgreSQL kann Arbeitslasten von kleinen Anwendungen mit nur einem Rechner bis hin zu großen das Internet nutzende Anwendungen mit vielen gleichzeitigen Benutzern bewältigen. PostgreSQL bietet Hochverfügbarkeitsfunktionen auf Datenbankebene. Eine Einrichtung mit einem Master und mehreren Slave-Knoten in derselben oder unterschiedlichen Verfügbarkeitszonen ist möglich.
Weitere Informationen zu ThingWorx und PostgreSQL-Bereitstellungen finden Sie hier:
•
Hochverfügbarkeit mit ThingWorx (ThingWorx 8 Administratorhandbuch zu Hochverfügbarkeit)
Weitere Informationen zu PostgreSQL finden Sie unter
https://www.postgresql.org/.
Typische Anwendungsfälle
Die Datenbank kann für kleine, mittlere und große Implementierungen bis zu 15.000 Eigenschaftsschreibvorgänge pro Sekunde (wps) skaliert werden und bietet Hochverfügbarkeitsfunktionalität.
Microsoft SQL Server (MSSQL)
Microsoft SQL Server (MSSQL) ist ein Verwaltungssystem für relationale Datenbanken, das von Microsoft entwickelt wurde. Als Datenbankserver ist Microsoft SQL Server ein Software-Produkt mit der Hauptfunktion, Daten zu speichern und abzurufen, wenn diese von anderen Software-Anwendungen angefordert werden, die entweder auf demselben Computer oder einem anderen Computer in einem Netzwerk (einschließlich Internet) ausgeführt werden. Weitere Informationen zu ThingWorx und Microsoft SQL Server-Bereitstellungen finden Sie unter
Microsoft SQL Server als Persistenzanbieter verwenden .
Sie können zwischen mehreren SQL Server-Editionen wählen, um die für Sie am besten geeignete Datenlösung zu finden. Diese Editionen haben eine maximale relationale Datenbankgröße, die von 10 GB (klein) bis 524 Millionen GB (extrem groß) reicht. Um eine hohe Verfügbarkeit zu erreichen, sollte die Enterprise Edition verwendet werden.
MSSQL unterstützt über seinen Persistenzanbieter sowohl Modell- als auch Datenanbieter.
Weitere Informationen zu Microsoft SQL Server finden Sie unter
https://www.microsoft.com/de-de/sql-server/sql-server-2016.
Typische Anwendungsfälle
Der SQL Server kann für kleine und große IoT-Implementierungen verwendet werden. Die Verwendung empfiehlt sich jedoch vor allem dann, wenn Microsoft SQL/Azure bereits in Ihrem IT-Stapel vorhanden ist und Ihre Mitarbeiter mit der Implementierung der MSSQL Server-Hochverfügbarkeitslösung gemäß
SQL Server 2017-Szenarios, die Verfügbarkeitsfunktionen verwenden vertraut sind.
Azure SQL-Datenbank
Die Azure SQL-Datenbank ist eine relationale Datenbank-as-a-Service (DBaaS), die in Azure Cloud gehostet wird. Sie ist eine vollständig verwaltbare Platform-as-a-Service(PaaS)-Datenbank-Engine. Die Azure SQL-Datenbank-Engine basiert auf der Enterprise Edition von SQL Server. Die Azure-Plattform verwaltet vollständig jede Azure SQL-Datenbank und garantiert null Datenverlust bei hoher Datenverfügbarkeit. Die Azure SQL-Datenbank wird mit integrierter hoher Verfügbarkeit, Notfallwiederherstellung und Upgrade für die Datenbank bereitgestellt.
Weitere Informationen zu der Azure SQL-Datenbank und ihren Funktionen finden Sie auf
https://docs.microsoft.com/de-de/azure/sql-database/sql-database-paas. Informationen zur Verwendung von Azure SQL Database als ThingWorx Persistenzanbieter finden Sie unter
Azure SQL-Datenbank als Persistenzanbieter verwenden.
DataStax Enterprise (DSE)
Ab Version 8.5.0 von ThingWorx Platform wird DataStax Enterprise nicht mehr verkauft und in einer zukünftigen Version nicht unterstützt. Weitere Informationen finden Sie im Artikel
ThingWorx persistence provider SAP-HANA notification for End-of-Sale (EOS). |
ThingWorx verwendet auch einen Laufzeit-Datenspeicher-Anbieter für hohe Datenvolumen, DataStax Enterprise (DSE) unterstützt von Apache Cassandra. DSE ermöglicht es Ihnen, Daten mit einer höheren Geschwindigkeit zu erfassen, als deren Assets generiert werden. Außerdem ist eine nahtlose Skalierung möglich, wenn zusätzliche Geräte (oder andere Arbeitslasten) hinzugefügt werden. Die Verwendung von DSE als Laufzeitdatenspeicher liefert eine Datenbankplattform, die für die Leistungs- und Verfügbarkeitsansprüche von IoT, Web und mobilen Anwendungen konstruiert ist.
Die meisten relationalen Datenbanken können nicht horizontal skalieren und in einem Master-/Slave-Modus ausgeführt werden. Die Peer-to-Peer-Cluster-Architektur ohne Master von Cassandra ermöglicht jedoch Linearität und hohe Skalierbarkeit.
DSE bietet eine vollständig getestete und validierte Cassandra-Bereitstellung mit erweiterten Verwaltungs- und Überwachungstools, integrierter Integration mit Solr für die Indexierung und Suche und einen Mechanismus für Unterstützung und Patches. Dies korrespondiert mit dem austauschbaren Datenspeichermodell, das mehrere Daten-Repositories für die Speicherung von Konfigurations- und Modelldaten sowie von hohen Datenvolumen ermöglicht. Sie können wählen, welches Daten-Repository Ihren Anforderungen für eine bestimmte Funktion am besten entspricht.
DSE ist ein integriertes, immer aktiviertes, Multi-Modell-Datenbanksystem mit Echtzeit- und Batch-Analysen unter Verwendung von Apache Spark, In-Memory-Technologie, kontinuierlich verfügbarer Suche und Diagrammdatenbank-Berechnung. DSE bietet erweiterte Tools für Entwicklungs- und Produktionssystem-Operationen, flexible Funktionen wie mehrstufige Speicher, um kurz- und langzeitigen Datenzugriff zu gewährleisten, Mehrinstanzfähigkeit, um mehrere Datenbank-Cluster im selben System auszuführen, sowie erweiterte Sicherheit, um Unternehmensanforderungen zu erfüllen.
Die in DSE integrierte Suchkomponente (Apache Solr) des DSE-Stacks ist erforderlich, damit ThingWorx ausgeführt werden kann. Aus diesem Grund kann ThingWorx nicht mit Open-Source-Installationen von Apache Cassandra ausgeführt werden, da Apache Solr in diesen nicht integriert ist. |
DSE bietet die folgenden Vorteile für ThingWorx Plattformen, die einen Datenspeicher für höhere Datenvolumina und Geschwindigkeitsdaten erfordern als die derzeit mit H2 oder PostgreSQL verfügbaren:
• Höhere Datenerfassungsrate
• Unterstützung von mehr als einem Daten-Repository für Laufzeitdaten (Verwaltung von Modelldaten in H2 oder PostgreSQL und Verwendung von DSE für hohe Stream-Datenvolumen)
• Unterstützung elastischer Skalierungseigenschaften. Sie können einem DSE-Ring mehr Knoten für höhere Transaktionsraten hinzufügen.
• Trennung der Datenprozesse von Plattformprozessen
• Unterstützung Cloud-freundlicher Architektur
Weitere Informationen finden Sie unter
Getting Started with DataStax Enterprise and ThingWorx (Erste Schritte mit DataStax Enterprise und ThingWorx) und
DataStax Enterprise (DSE).
Typischer Anwendungsfall
Ein typischer Anwendungsfall ist das Vorhandensein großer Mengen (über 15.000 wps) von Transaktionsdaten (Laufzeit) über eine verteilte Last.
InfluxDB
Sie benötigen ThingWorx 8.4 oder höher, um InfluxDB zu verwenden. Wenn Sie in Ihrem System intensiv mit Zeitreihendaten arbeiten und sich Ihre Implementierung für Persistenz/Datenabrufe stark auf Wert-Streams oder Streams stützt, empfehlen wir die Verwendung von InfluxDB als Persistenzanbieter in ThingWorx. InfluxDB ist ein hochleistungsfähiger Datenspeicher, der speziell für Zeitreihendaten entwickelt wurde. Er ermöglicht Datenaufnahme mit hohem Durchsatz sowie Komprimierung und Echtzeitabfragen der erfassten Daten. InfluxDB kommt in allen Anwendungsfällen als Datenspeicher zum Einsatz, bei denen große Mengen von Daten mit Zeitstempel verarbeitet werden, beispielsweise DevOps-Überwachungsdaten, Protokolldaten, Anwendungsmetriken, Daten von IoT-Sensoren oder Echtzeitanalysedaten. Der Datenspeicher stellt auch andere Funktionen bereit, unter anderem Datenaufbewahrungsrichtlinien. InfluxDB Enterprise bietet Hochverfügbarkeit sowie eine hochgradig skalierbare Clustering-Lösung für Anwendungsfälle mit Zeitreihendaten.
InfluxPersistenceProviderPackage steht in ThingWorx zur Verwendung mit Persistenzanbietern zur Verfügung, im Rahmen der Standardinstallation von PostgreSQL oder MSSQL.
• Der InfluxDB-Datenanbieter unterstützt derzeit ausschließlich Wert-Streams und Streams. Unterstützung für Datentabellen, Wikis und Blogs ist nicht verfügbar.
• Der InfluxDB-Datenanbieter unterstützt derzeit keine Exportfunktionen.
• InfluxDB wird derzeit nicht als Eigenschaftsanbieter unterstützt.
Wenn Sie eine mit dem InfluxDB-Persistenzanbieter-Paket erstellte Persistenzanbieter-Instanz als standardmäßigen Persistenzanbieter verwenden, können Sie die Konfigurationseinstellungen für Stream- und Wert-Stream-Warteschlangen bearbeiten. Diese Einstellungen werden auf alle Streams und Wert-Streams angewendet. Sie können diese Einstellungen für einen bestimmten Stream oder Wert-Stream nicht ändern.
Informationen zur Verwendung von InfluxDB als Persistenzanbieter finden Sie unter
InfluxDB als Persistenzanbieter verwenden.