Hochverfügbarkeit mit ThingWorx
Übersicht über Hochverfügbarkeit mit ThingWorx
Um die Dauer von Ausfällen für kritische IoT-Systeme zu reduzieren, können Sie ThingWorx für den Betrieb in einer Hochverfügbarkeitsumgebung konfigurieren. In diesem Handbuch werden die für ein ThingWorx System erforderlichen Überlegungen zur Hochverfügbarkeit (High Availability, HA) und die Komponenten, die eine solche ThingWorx HA-Bereitstellung umfasst, erläutert.
Alle HA-Bereitstellungen erfordern zusätzliche Ressourcen, wenn Sie mit einer Bereitstellung verglichen werden, die nur den Anforderungen an Funktionalität und Skalierung entsprechen soll. Diese zusätzlichen Ressourcen sind hardwarebasiert (wie Server, Datenträger, Lastenausgleichsmodule usw.) und softwarebasiert (wie Synchronisierungsdienste und Lastenausgleichsmodule). Die zusätzlichen Ressourcen werden konfiguriert, um sicherzustellen, dass innerhalb der HA-Bereitstellung keine einzelnen Fehlerstellen vorhanden sind.
Alle HA-Bereitstellungen sollten auf einer Dienstleistungsvereinbarung (Service Level Agreement, SLA) basieren, in der Sie die Betriebszeitanforderungen der Anwendung für Ihre Bereitstellung analysiert haben. Wie viele Stunden pro Monat kann das System beispielsweise offline sein? Ist das die zulässige Ausfallzeit für Systemausfälle, Anwendungs-Upgrades oder beides? Die Anzahl der zusätzlichen Ressourcen, die für ein HA-System erforderlich sind, hängt vom SLA ab, die es einhalten soll. Wenn der Umfang des SLA zunimmt, steigt in der Regel auch das Erfordernis, dass Ressourcen diese einhalten.
Definitionen
• Hochverfügbarkeit
Systeme oder Komponenten, die für einen möglichst langen Zeitraum kontinuierlich in Betrieb sind.
• aktiv/aktiv
Instanzen derselben Anwendung, die gleichzeitig funktionieren.
• aktiv/passiv
Instanz einer Anwendung, die jeweils funktioniert. Weitere Instanzen sind verfügbar und können den Dienst nach Bedarf übernehmen.
• Leader oder Master
Aktiver Server in einer aktiv/passiv-HA-Konfiguration, an den der gesamte Datenverkehr geleitet wird.
• Standby
Server in einer aktiv/passiv-HA-Konfiguration, der bereit ist, den Dienst zu übernehmen, falls der aktuelle Leader ausfällt.
• virtuelle IP-Adresse
IP-Adresse, die für eine Anwendung steht. Clients, die die virtuelle IP verwenden, werden normalerweise an ein Lastenausgleichsmodul weitergeleitet, das die Anforderung dann an den Server weiterleitet, auf dem die Anwendung ausgeführt wird.
• Lastenausgleichsmodul
Gerät, das Netzwerkverkehr empfängt und an die Anwendung weiterleitet, die bereit ist, diesen anzunehmen. Bei einer aktiv/passiv-HA-Konfiguration leitet das Lastenausgleichsmodul den Datenverkehr an den aktuellen Leader weiter. Bei einer aktiv/aktiv-HA-Konfiguration leitet das Lastenausgleichsmodul den Datenverkehr an eine von vielen Anwendungen weiter.
• Failover
Backup-Betriebsmodus, in dem die Funktionen einer Systemkomponente (wie Prozessor, Server, Netzwerk oder Datenbank) von sekundären Systemkomponenten übernommen werden, wenn die primäre Komponente aufgrund eines Fehlers oder einer geplanten Ausfallzeit nicht verfügbar ist.
ThingWorx Referenzarchitektur für Hochverfügbarkeit
Die folgende Abbildung zeigt ThingWorx in einer Konfiguration mit hoher Verfügbarkeit.
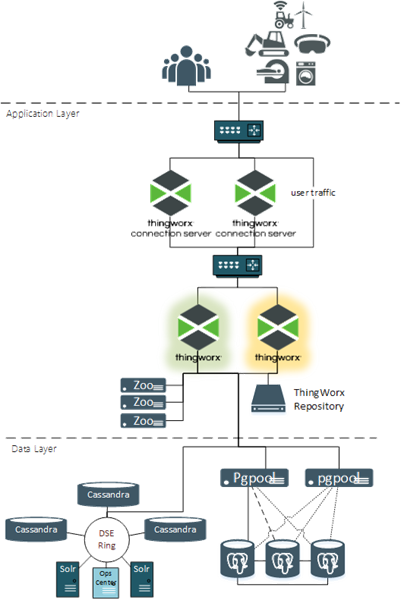
Nachfolgend sind die Komponenten in dieser Konfiguration und ihre Rolle in einer HA-Bereitstellung aufgeführt:
• Benutzer und Geräte – Keine Rolle bei der HA-Funktionalität. Aus ihrer Perspektive ändert sich nichts. Sie verwenden immer dieselben URLs und dieselbe IP-Adresse, auch wenn sich der primäre ThingWorx Server geändert hat.
• Firewalls – Keine HA-Funktion und als optional anzusehen. Firewalls werden häufig platziert, um Sicherheitsanforderungen zu implementieren.
• Lastenausgleichsmodule – Lastenausgleichsmodule verwalten eine virtuelle IP-Adresse für die Anwendung, die sie unterstützen. Der gesamte Datenverkehr, der an diese virtuelle IP-Adresse weitergeleitet wird, wird an die aktive Anwendung geleitet, die ihn empfangen kann.
• ThingWorx Connection Servers – Empfängt Web Socket-Verkehr von Assets und leitet ihn an ThingWorx Platform weiter. Die Connection Servers können in einer aktiv/aktiv-Konfiguration ausgeführt werden. Sobald ein Asset an einen bestimmten Connection Server weitergeleitet wird, sollte es immer denselben Connection Server verwenden. Wenn dieser Server offline geschaltet wird, sollte das Asset zu einem anderen verfügbaren Connection Server umgeleitet werden.
• ThingWorx Foundation – Empfängt den gesamten Benutzer- und Asset-Datenverkehr. ThingWorx Foundation arbeitet in einer aktiv/passiv-Konfiguration mit einem Leader-Server und einem oder mehreren Standby-Servern. Der Leader-Server ist online und empfängt Datenverkehr. Die Standby-Server werden in aufgewärmtem Zustand ausgeführt, wenn die Anwendung ausgeführt wird, haben aber keine aktiven Verbindungen zur Datenbank und empfangen keinen Datenverkehr. Ein Lastenausgleichsmodul leitet den gesamten Datenverkehr an den Leader weiter. Wenn der Leader offline geschaltet wird, wird der Standby-Server zum Leader heraufgestuft, und der Datenverkehr wird an ihn weitergeleitet.
• ThingWorx Repositories – Dies sind erforderliche Speicherorte wie ThingworxPlatform, ThingworxStorage und ThingworxBackupStorage sowie zusätzliche Speicherorte, die zur Unterstützung Ihrer Implementierung hinzugefügt wurden. Für eine HA-Umgebung müssen ThingWorx Repositories an einem gemeinsamen Speicherort vorhanden sein, an dem alle ThingWorx Server (Leader und Standby-Server) gleichermaßen auf sie zugreifen können.
• Apache ZooKeeper – ZooKeeper ist ein zentralisierter Koordinationsdienst, der von ThingWorx verwendet wird, um einen der ThingWorx Server zu einem bestimmten Zeitpunkt als Leader zu wählen. Ein ZooKeeper-Client wird in jeden ThingWorx Server eingebettet, um einen Heartbeat beizubehalten und auf Änderungen in der Konfiguration zu reagieren, wie z.B. einen Ausfall des aktuellen ThingWorx Leaders.
• PostgreSQL – Für eine HA-Konfiguration arbeitet PostgreSQL über zwei oder mehr Serverknoten in einer Hot-Standby-Konfiguration. Ein Knoten empfängt den gesamten Schreibdatenverkehr, und einer der anderen Knoten kann den gesamten Lesedatenverkehr empfangen. Die Streaming-Replikation wird zwischen allen Knoten aktiviert, damit jeder Knoten stets auf dem neuesten Stand ist.
• pgpool-II – Wird nur in PostgreSQL-HA-Konfigurationen verwendet. pgpool-II-Knoten empfangen die ThingWorx Anfragen (Lese- und Schreibvorgänge) und leiten sie an den entsprechenden PostgreSQL-Knoten weiter. Sie überwachen auch die Integrität jedes PostgreSQL-Knotens und können Failover-Aufgaben und Neuzuweisungen initiieren, wenn einer der Knoten offline geht.
• Microsoft SQL Server (nicht abgebildet) – Microsoft Failover wird verwendet, um sicherzustellen, dass mindestens ein MS SQL Server online und verfügbar ist.
• DataStax Enterprise (DSE) – Eine DSE-Implementierung ist für eine ThingWorx HA-Konfiguration nicht erforderlich. Wenn sie erforderlich ist, um die Erfassungsanforderungen der Implementierung zu erfüllen, stellen Sie sicher, dass sie für HA konfiguriert ist. Die typische DSE-Implementierung erfüllt die meisten HA-Anforderungen. Sie besitzt mehrere Cassandra-Knoten, die Inhalt erfassen, und mindestens zwei Solr-Knoten. Die DSE-Konstruktion repliziert den gesamten Inhalt auf mindestens einen anderen Knoten.
Ab Version 8.5.0 von ThingWorx Platform wird DataStax Enterprise nicht mehr verkauft und in einer zukünftigen Version nicht unterstützt. Weitere Informationen finden Sie im Artikel
ThingWorx persistence provider SAP-HANA notification for End-of-Sale (EOS). |
Anforderungen vor der Installation
Hinweise und Warnungen:
• Die Schritte·in diesem HA-Prozess·sollten·von·einem·Datenbankadministrator·(DBA)·mit·Erfahrung in Bezug auf·relationale·Datenbanken·in·der·Konfiguration·für·Hochverfügbarkeit (High Availability, HA) (PostgreSQL, Microsoft SQL Server und DataStax Enterprise) verwendet werden. Zu den erforderlichen Kenntnissen zählen Installation, Optimierung und Hochverfügbarkeits-Clustering.
• Die hier bereitgestellten Anweisungen dienen zum Bereitstellen von HA-Umgebungen. Möglicherweise ist eine zusätzliche Leistungsoptimierung in einer Produktionsumgebung erforderlich. Dies wird jedoch nicht hier behandelt.
• Detaillierte Schritte sind Beispiele zur Referenz und nur für eine QA- oder Sandbox-Umgebung vorgesehen. Installateure müssen möglicherweise die Befehle und Einstellungen bearbeiten, um eine optimale Leistung in einer Produktionsumgebung zu erzielen.
• Alle Failover-Konfigurationen müssen vollständig getestet und validiert werden, bevor sie in der Produktion eingesetzt werden.
• Die Schritte in diesem Prozess erörtern keine Failback-Szenarios, bei denen ein ausgefallener Leader korrigiert und dann wieder zum Leader gemacht wird. Es wird davon ausgegangen, dass die fehlgeschlagene Komponente korrigiert und als Nicht-Leader-Komponente wieder in Betrieb genommen wird.
Unterstützte Betriebssysteme
Allgemeine HA-Anforderungen
Virtuelle IP-Adressen
• Benutzer und Assets zu Connection Servers (wenn Connection Servers verwendet werden)
• Connection Servers zu ThingWorx Foundation
• ThingWorx Foundation zu PostgreSQL HA (wenn PostgreSQL verwendet wird)
• ThingWorx Foundation zu Microsoft SQL Server HA (wenn Microsoft SQL Server verwendet wird)
Hardware-Anforderungen
Die hier bereitgestellten Schritte gehen davon aus, dass die vollständige Hardwareredundanz in einer ThingWorx HA-Konfiguration verwendet wird.
• Jede Instanz einer Anwendung sollte auf einer separaten Hardware ausgeführt werden, um Single Points of Failure auf Hardwareebene zu vermeiden. Beispielsweise sollten ThingWorx Server, ob physisch, virtuell oder Cloud-basiert, nicht auf derselben physischen Hardware ausgeführt werden.
• Diese Anforderung wird für alle Anwendungen in der ThingWorx HA-Konfiguration (ThingWorx, PostgreSQL, DataStax Enterprise, ZooKeeper usw.) erwartet, um das Risiko von Hardwarefehlern zu minimieren.
• Redundante Router, Switches, Netzteile usw. werden durch den hier bereitgestellten Prozess angenommen.
Eigenschaften von ThingWorx in einer HA-Konfiguration
ThingWorx Eigenschaften sollten auf persistent festgelegt werden, um Datenverlust im Falle eines Failovers zu verhindern. Wenn sie nicht persistent sind, werden durch ein Failover von primären zu sekundären Servern die Werte im Arbeitsspeicher gelöscht.
PostgreSQL-Anforderungen
• Pgpool-II und PostgreSQL DB sind in RHEL- oder Ubuntu-Umgebungen installiert.
• Mindestens zwei DB-Host-Server, auf denen eine unterstützte Version von PostgreSQL ausgeführt wird. Drei werden empfohlen.
• Zwei Server, auf denen pgpool-II 3.7.<neueste> mit konfiguriertem Watchdog ausgeführt wird, sind typisch. Dieses Beispiel wird hier verwendet, jedoch sind auch andere HA-Konfigurationen möglich, die Pgpool-II nicht verwenden.
Microsoft SQL Server-Anforderungen
• Mindestens zwei DB-Host-Server, auf denen eine unterstützte Version von Microsoft SQL Server ausgeführt wird.
• Microsoft SQL Server ist so konfiguriert, dass es über eine der folgenden HA-Methoden von Microsoft ausgeführt wird:
◦ Always On-Failover-Cluster-Instanzen
◦ Always On-Verfügbarkeitsgruppen
DataStax Enterprise-Anforderungen
• Mindestens fünf Knoten für einen DataStax Enterprise-Cluster:
◦ Drei Cassandra-Knoten
◦ Zwei Solr-Knoten
◦ (optional) Ein DSE-OpsCenter-Knoten für administrative Arbeit, da OpsCenter für den Betrieb nicht kritisch ist und keine Konfiguration mit Hochverfügbarkeit erfordert.
InfluxDB-Anforderungen
• Mindestens zwei Metaknoten, für die meisten Anwendungsfälle werden drei empfohlen
• Mindestens zwei Datenknoten, empfohlen wird eine gerade Anzahl von Datenknoten
• Eine typische Bereitstellung sollte drei Metaknoten und eine gerade Zahl von Datenknoten haben.