DataStax Enterprise als Persistenzanbieter verwenden
Übersicht
|
|
Ab Version 8.5.0 von ThingWorx Platform wird DSE nicht mehr verkauft und in einer zukünftigen Version nicht unterstützt. Weitere Informationen finden Sie im Artikel
ThingWorx persistence provider SAP-HANA notification for End-of-Sale (EOS).
|
Wenn das Modell Big Data-Skalierbarkeit erfordert, können Sie DataStax Enterprise (DSE) als
Persistenzanbieter über einen Erweiterungsimport in ThingWorx verwenden. Die Erweiterung DsePersistenceProviderPackage.zip verwendet die DataStax Enterprise Edition Cassandra (nicht die Open Source/Community Edition), die die Solr-Suchmaschine als integrierte Lösung bietet. DSE ist eine Big Data-Plattform, die auf Apache Cassandra aufsetzt und Echtzeit-, Analyse- und globale Suchdaten verwaltet.
Cassandra ist eine skalierbare NoSQL-Datenbank (Open Source), die große Datenmengen über mehrere Rechenzentren und die Cloud hinweg verwalten kann. Cassandra stellt fortlaufende Verfügbarkeit, lineare Skalierbarkeit und operationale Einfachheit auf vielen Standardservern ohne einzelne Fehlerstelle bereit, zusammen mit einem leistungsfähigen Datenmodell, das für maximale Flexibilität und schnelle Antwortzeiten entworfen wurde.
|
|
Die ersten Schritte mit DSE erfordern das Registrieren, Installieren und Konfigurieren von DSE. Der Großteil dieses Prozesses wird unabhängig von ThingWorx durchgeführt und ist hier dokumentiert.
|
Bei der Planung der DataStax Enterprise-Bereitstellung müssen Sie zunächst die Architektur und insbesondere die Unterschiede zu regulären relationalen Datenbanken verstehen. Wenn Sie bisher noch nicht mit Cassandra gearbeitet haben, sind die von DataStax Academy angebotenen kostenlosen Online-Kurse ein guter Ausgangspunkt. Insbesondere gilt:
Im folgenden Abschnitt werden einige Besonderheiten erklärt:
•
http://datastax.com/documentation/cassandra/2.0/cassandra/architecture/architecturePlanningAbout_c.html
DSE und ThingWorx – Ausgangslandschaft
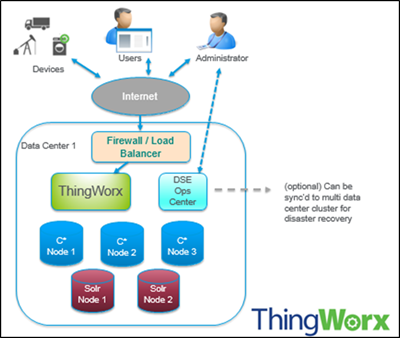
Die folgenden Begriffe werden in dieser Dokumentation verwendet, wenn auf die Konfiguration für DSE Bezug genommen wird:
• Knoten – Speicherort für Ihre Daten. Dies ist die grundlegende Infrastrukturkomponente von Cassandra.
• Rechenzentrum – eine Sammlung zugehöriger Knoten. Ein Rechenzentrum kann ein physisches Rechenzentrum oder ein virtuelles Rechenzentrum sein. Für unterschiedliche Arbeitslasten sollten unabhängige Rechenzentren (entweder physische oder virtuelle) verwendet werden. Die Replikation wird vom Rechenzentrum festgelegt. Die Verwendung unabhängiger Rechenzentren verhindert, dass Cassandra-Transaktionen von anderen Arbeitslasten beeinflusst werden, und hält Anforderungen nahe beieinander, um für niedrige Latenz zu sorgen. Je nach Replikationsfaktor können Daten in mehrere Rechenzentren geschrieben werden. Rechenzentren sollten sich jedoch nie über mehrere physische Standorte erstrecken.
• Cluster – Ein Cluster enthält ein oder mehrere Rechenzentren. Es kann sich über mehrere physische Standorte erstrecken.
Allgemeiner Prozess der DSE-Implementierung in ThingWorx
1. Bestimmen Sie, ob DSE die richtige Lösung für Ihre Daten ist. Referenzieren Sie die Dimensionierungs- und Planungsabschnitte für zusätzliche Informationen.
2. Registrieren und installieren Sie DSE.
Dieser Prozess wird unabhängig von ThingWorx durchgeführt. Ein Bereitstellungsbeispiel ist verfügbar.
3. Importieren Sie die DSE-Persistenzanbieter-Erweiterung in ThingWorx.
4. Erstellen Sie eine Persistenzanbieter-Instanz in ThingWorx, die den DSE-Datenspeicher verbindet.
5. Konfigurieren Sie die Einstellungen für den Persistenzanbieter in ThingWorx. Details zu den Einstellungen finden Sie in der Tabelle unten.
Für Streams, Wert-Streams und Datentabellen können Sie Bucket-Einstellungen konfigurieren. Diese Einstellungen überschreiben die DSE-Persistenzanbieterinstanz-Konfiguration. |
Name | Standardwert | Beschreibung | ||
|---|---|---|---|---|
Verbindungsinformationen | ||||
Cassandra Cluster-Hosts | 192.168.234.136,192.168.234.136 | IP-Adresse(n) für Cassandra-Cluster. Dies sind die IP-Adressen oder Host-Namen, die während des DSE-Setups konfiguriert werden, um den Cassandra-Cluster zu installieren. | ||
Cassandra Cluster-Port | 9042 | Port für den Cassandra-Cluster, der während des DSE-Setups konfiguriert wird, um den Cassandra-Cluster zu installieren. | ||
Cassandra Benutzername | N/A | Optional, es sei denn, Sie möchten Authentifizierung auf einem Cluster aktivieren. In diesem Fall ist dieses Feld ein erforderliches Feld.
| ||
Cassandra Passwort | N/A | Optional, es sei denn, Sie möchten die Authentifizierung auf einem Cluster aktivieren; in diesem Fall ist dieses Feld ein erforderliches Feld. (Siehe oben). | ||
Cassandra Keyspace-Name | thingworxnd | Ort, auf den ThingWorx Daten verweisen. Ähnlich wie ein Schema in einer relationalen Datenbank.
| ||
Solr-Cluster-URL | http://localhost | Wenn Datentabellen verwendet werden, stellen Sie die IP oder den vollständig qualifizierten Host-Namen bereit, einschließlich der Domäne oder IP, die während des DSE-Setups konfiguriert wurde, um den Cassandra-Cluster zu installieren. | ||
Solr-Cluster-Port | 8983 | Wenn Datentabellen verwendet werden, stellen Sie den Port bereit, der während des DSE-Setups konfiguriert wurde, um den Cassandra-Cluster zu installieren. | ||
Cassandra Keyspace-Einstellungen | replication = {'class':'NetworkTopologyStrategy', 'Cassandra':1, 'Solr':1} | Wird abhängig von Ihrer Cassandra-Cluster-Konfiguration während des DSE-Setups erstellt. Definiert hauptsächlich die verwendeten Rechenzentren und die zugeordneten Replikationsfaktoren (siehe
http://datastax.com/documentation/cql/3.1/cql/cql_reference/create_keyspace_r.html für Details). Wenn die Administratoren den Keyspace manuell erstellt haben, sollten diese Einstellungen den manuell erstellten Keyspace-Einstellungen entsprechen. | ||
Cassandra Konsistenzebenen | {'Cluster' : { 'read' : 'ONE', 'write' : 'ONE' }} | Konsistenzebenen für Lese- und Schreibvorgänge für die Anzahl von Knoten.
| ||
Ergebnisgrenze für CQL-Abfrage | 5000 | "Ergebnisgrenze für CQL-Abfrage" gibt die Anzahl der zurückgegebenen Zeilen bei der Abfrage der Daten an. Dies erhöht die Stabilität von ThingWorx, da große Ergebnissätze, die zu Leistungsbeeinträchtigungen in der zurückzugebenden Plattform führen würden, nicht zulässig sind. | ||
Verbindung aufrecht erhalten | true | Erhält die Verbindungen zum Cassandra-Cluster aufrecht, insbesondere durch Firewalls, wo inaktive Verbindungen gelöscht werden könnten.
| ||
Verbindungs-Timeout (Millisek.) | 30000 | Anfängliches Verbindungs-Timeout in Millisekunden. Hängt von der Netzwerklatenz zwischen ThingWorx und dem Cassandra-Cluster ab. | ||
Komprimierungsalgorithmus | keiner | Wenn ThingWorx Daten an einen Cluster sendet, gibt es drei Möglichkeiten: • Lz4-Komprimierung • Snappy-Komprimierung • Keine Komprimierung Wenn die Netzwerkbandbreite zwischen ThingWorx und dem Cassandra-Cluster niedrig ist, erhöht Komprimierung den Durchsatz.
| ||
Maximale Abfragewiederholungen | 3 | Maximale Anzahl der Wiederholungen, die für Abfragen aktiviert sind. Die Standardeinstellung beträgt 3. | ||
Lokale Kernverbindungen | 4 | Mindestanzahl von Verbindungen, die Daten lesen/schreiben können. | ||
Maximale lokale Verbindungen | 16 | Maximale Anzahl von Verbindungen, die Daten lesen/schreiben können. | ||
Remote-Kernverbindungen | 2 | Mindestanzahl von Remote-Verbindungen, die Daten lesen/schreiben können. | ||
Maximale Remote-Verbindungen | 16 | Maximale Anzahl von Remote-Verbindungen, die Daten lesen/schreiben können. | ||
Ablaufverfolgung aktivieren | false | Protokollierung. Kann für das Debuggen aktiviert werden. | ||
Maximale asynchrone Anforderungen | 1000 | |||
Einstellungen für klassischen Stream | ||||
Cache-Anfangsgröße | 10000 | Anfängliche Cache-Größe. Dies ist von der Anzahl an Quellen abhängig.
| ||
Maximale Cache-Größe | 100000 | Max. Cache-Größe. Steuert Arbeitsspeicherverwendung. | ||
Cache-Parallelität | 24 | Anzahl der Threads, auf die Sie gleichzeitig zugreifen können. Der Minimalwert sollte den Wert für "Maximale Remote-Verbindungen" widerspiegeln. | ||
Standards für klassischen Stream | ||||
Quell-Bucket-Anzahl | 1000 | Quellen können in Buckets eingefügt werden. Die Anzahl von Quellen entspricht der Anzahl von Abfragen, die ausgeführt werden müssen. Wenn Sie beispielsweise 100.000 Quellen haben, bestimmt dieses Feld, wie viele Buckets verwendet werden.
| ||
Zeit-Bucket-Größe (Stunden) | 24 | Zeit (in Stunden), um Buckets zu erstellen. Abhängig von der Quell-Bucket-Größe. Wenn die Zeit-Bucket-Größe auf 24 eingestellt wird, werden Buckets alle 24 Stunden erstellt. Das Ziel ist es, zu versuchen, 2 Millionen Datenpunkte nicht zu überschreiten. Abhängig von der Datenaufnahmerate (R pro Sekunde) pro Wert-Stream oder klassischem Stream: Zeit-Bucket-Größe = 2 mil / (R * 60 * 60)
| ||
Standards für Datentabelle | ||||
Datentabellen-Bucket-Anzahl | 3 | Eine Datentabelle kann in Buckets aufgeteilt werden. Dies ermöglicht das Verteilen einer Datentabelle auf DSE-Knoten. Ein Wert höher als die Anzahl von Knoten im Cluster wird empfohlen, um Daten zu verbreiten, wenn die Anzahl von Knoten abhängig von der Last zunimmt. Der andere zu beachtende Faktor ist die Anzahl der Zeilen, die in der Datentabelle erwartet wird. Ziehen Sie eine Begrenzung auf 200.000 Zeilen pro Bucket in Betracht. Die Einstellung hier ist der Standard. Die Bucket-Anzahl kann pro Datentabelle angegeben werden.
| ||
Einstellungen für Wert-Stream | ||||
Cache-Anfangsgröße | 10000 | Anfängliche Cache-Größe. Dies ist von der Anzahl der Quellen multipliziert mit der Anzahl der Eigenschaften pro Quelle abhängig. | ||
Maximale Cache-Größe | 100000 | Maximale Cache-Größe. Steuert Arbeitsspeicherverwendung. | ||
Cache-Parallelität | 24 | Anzahl der Threads, auf die Sie gleichzeitig zugreifen können. | ||
Standards für Wert-Stream | ||||
Quell-Bucket-Anzahl | 1000 | Quellen können in Buckets eingefügt werden. Die Anzahl von Quellen entspricht der Anzahl von Abfragen, die ausgeführt werden müssen. Wenn Sie beispielsweise 100.000 Quellen haben, bestimmt dieses Feld, wie viele Buckets verwendet werden.
| ||
Eigenschaften-Bucket-Anzahl | 1000 | Die Anzahl der Buckets hängt von der Anzahl der Eigenschaften pro Wert-Stream und dem Abfragemuster ab. Falls es Abfragen für verschiedene Eigenschaften gibt, bietet eine kleinere Bucket-Größe die optimale Leistung. | ||
Zeit-Bucket-Größe (Stunden) | 24 | Größe der Buckets. Abhängig von der Quell-Bucket-Größe. Wenn die Zeit-Bucket-Größe auf 24 eingestellt wird, werden Buckets alle 24 Stunden erstellt.
| ||
6. Migrieren Sie Entitäten und Daten ggf.
7. Überwachen und verwalten Sie Ihre DSE-Implementierung. Die optimalen Vorgehensweisen für die Erstellung eines erfolgreichen Wartungsplans werden hier beschrieben.