Vision par ordinateur
Le service Vision par ordinateur d'Azure fournit aux développeurs des algorithmes avancés qui traitent les images et renvoient des informations. Pour analyser une image, vous pouvez soit la charger, soit spécifier une URL d'image. Les algorithmes de traitement peuvent analyser le contenu des images de différentes manières, en fonction de différents composants visuels. Par exemple, Vision par ordinateur peut identifier tous les visages humains présents sur une image. Pour plus d'informations, reportez-vous à la page sur le service Vision par ordinateur Azure.
Utilisez l'action Vision par ordinateur pour analyser une image, analyser une image par domaine, décrire une image, et détecter et fournir des informations sur les composants visuels et les caractéristiques d'une image.
Assurez-vous que votre image répond aux exigences suivantes :
• Format JPEG, PNG, GIF ou BMP.
• Taille de fichier inférieure à 4 Mo.
• Dimensions comprises entre 50 x 50 pixels et 4 200 x 4 200 pixels.
• Taille non supérieure à 10 mégapixels.
Procédez comme suit pour utiliser l'action Vision par ordinateur dans votre processus :
1. Faites glisser l'action Vision par ordinateur sous Azure jusqu'au canevas, placez le pointeur sur l'action, puis cliquez sur  ou double-cliquez sur l'action. La fenêtre Vision par ordinateur s'ouvre.
ou double-cliquez sur l'action. La fenêtre Vision par ordinateur s'ouvre.
ou double-cliquez sur l'action. La fenêtre Vision par ordinateur s'ouvre.2. Modifiez le champ Etiquette, si nécessaire. Par défaut, le nom de l'étiquette est identique à celui de l'action.
3. Pour ajouter un type de connecteur Azure, consultez la rubrique Types de connecteur Azure pris en charge.
Si vous avez déjà précédemment ajouté un type de connecteur approprié, sélectionnez-le dans Type de connecteur, puis, sous Nom du connecteur, sélectionnez le connecteur voulu.
4. Cliquez sur TESTER pour valider le connecteur.
5. Cliquez sur MAPPER CONNECTEUR pour exécuter l'action à l'aide d'un connecteur différent de celui que vous utilisez pour renseigner les champs d'entrée. Dans le champ Connecteur d'exécution, spécifiez un nom de connecteur Azure valide. Pour plus d'informations sur la commande MAPPER CONNECTEUR, consultez la section détaillant l'utilisation d'un mappage de connecteur.
Si vous avez sélectionné Aucun dans Type de connecteur, l'option MAPPER CONNECTEUR n'est pas disponible.
6. Dans la liste Groupe de ressources, sélectionnez le groupe de ressources approprié défini dans votre abonnement Azure.
7. Dans le champ Compte Vision par ordinateur, sélectionnez le compte Vision par ordinateur approprié.
8. Dans la liste Fournir image par, sélectionnez l'une des options suivantes, puis procédez comme suit :
◦ Sélectionnez URL, puis, dans le champ URL image, spécifiez une URL d'image publiquement accessible.
◦ Sélectionnez Charger un fichier, puis, dans le champ Chemin fichier image, mappez la sortie d'une action précédente pour spécifier le chemin d'accès à une image.
9. Dans la liste Sélectionner service spécifique, en fonction du type d'analyse d'image que vous souhaitez effectuer, sélectionnez l'un des services Computer Vision suivants et menez à bien la tâche correspondante :
Service | Tâche |
|---|---|
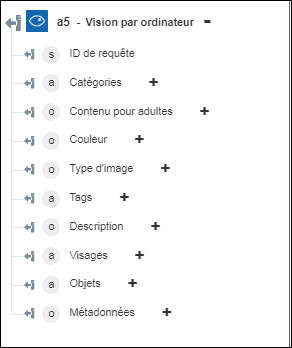
Analyser l'image : Extrait du contenu de l'image un riche ensemble de composants visuels. | a. Dans la liste Composants visuels, sélectionnez les composants voulus pour l'analyse de l'image : ◦ Catégories : catégorise le contenu de l'image selon la taxonomie des catégories. ◦ Description : décrit le contenu de l'image au moyen d'une phrase complète en anglais. ◦ Couleur : détermine si l'image est en noir et blanc ou en couleur, et pour les images en couleur, détecte les couleurs dominantes et les accents de couleur. ◦ Tags : balise l'image au moyen d'une liste détaillée de mots associés au contenu de l'image. ◦ Visages : détecte la présence de visages dans l'image. ◦ Type d'image : détecte si une image est une image clipart ou un dessin au trait. ◦ Contenu pour adultes : détecte si l'image présente un caractère pornographique ou si elle représente un contenu sexuel. ◦ Objets : détecte différents objets dans l'image. Pour ajouter plusieurs composants visuels, cliquez sur Ajouter. Pour supprimer les composants visuels que vous avez ajoutés, cliquez sur  . .b. Sous Détails, cliquez sur Ajouter, puis sélectionnez l'un des types de détails spécifiques au domaine que vous souhaitez inclure : ◦ Célébrités : identifie les célébrités détectées dans l'image. ◦ Repères : identifie les monuments célèbres dans l'image. Pour ajouter d'autres types de détails, cliquez sur Ajouter. Pour supprimer les détails que vous avez ajoutés, cliquez sur . |
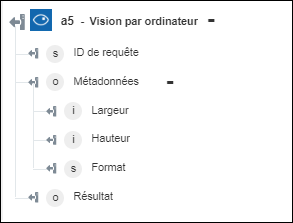
Analyser l'image par domaine : Reconnaît le contenu d'une image en appliquant un modèle spécifique à un domaine. | a. Dans le champ Modèle, spécifiez le modèle spécifique au domaine à utiliser pour analyser l'image. b. Dans le champ Langue, sélectionnez la langue dans laquelle vous souhaitez générer la sortie. Par défaut, la langue sélectionnée est l'Anglais. |
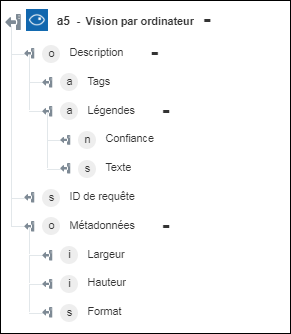
Décrire l'image : Décrit le contenu de l'image au moyen de phrases complètes lisibles par l'utilisateur. | a. Dans le champ Nombre max. de candidats, spécifiez le nombre maximal de descriptions de candidat que le service doit renvoyer. b. Dans la liste Langue, sélectionnez la langue dans laquelle vous souhaitez générer la sortie. Par défaut, la langue sélectionnée est l'Anglais. |
Détecter les objets : Réalise une détection des objets présents dans l'image. | Aucune action requise. |
Générer une miniature : Génère une image miniature de l'image spécifiée. | a. Dans le champ Largeur, spécifiez la largeur de la miniature entre 1 et 1024 pixels. Il est recommandé de spécifier une valeur d'au moins 50. b. Dans le champ Hauteur, spécifiez la hauteur de la miniature entre 1 et 1024 pixels. Il est recommandé de spécifier une valeur d'au moins 50. c. Dans la liste Rognage intelligent, sélectionnez vrai pour activer le rognage intelligent. Sélectionnez faux si vous ne souhaitez pas activer le rognage intelligent. |
Extraire le texte imprimé (OCR) : Détecte le texte présent dans une image et extrait les caractères reconnus dans un flux de caractères lisible par une machine. | a. Dans la liste Langue, sélectionnez la langue du texte de l'image. L'option sélectionnée par défaut est Inconnu. b. Dans la liste Détecter l'orientation, sélectionnez vrai pour détecter l'orientation du texte dans l'image et la corriger avant le traitement. Sélectionnez faux si vous ne souhaitez pas que le service détecte l'orientation du texte dans l'image. |
Extraire le texte manuscrit : Extrait le texte manuscrit d'une image. | Aucune action requise. |
Identifier l'image par tags : Génère une liste de tags pertinents pour le contenu de l'image. | Dans la liste Langue, sélectionnez la langue dans laquelle vous souhaitez générer la sortie. Par défaut, la langue sélectionnée est l'Anglais. |
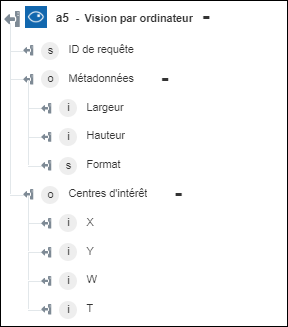
Obtenir les centres d'intérêt : Renvoie une boîte englobante localisant la zone la plus importante de l'image. | Aucune action requise. |
10. Cliquez sur Terminé.
Schéma de sortie
Chaque service Vision par ordinateur possède son propre schéma de sortie.
◦ Analyser l'image : renvoie les composants visuels sélectionnés.
◦ Analyser l'image par domaine : renvoie le contenu reconnu dans l'image.
◦ Décrire l'image : renvoie la description de l'image.
◦ Détecter les objets : renvoie les objets et leurs coordonnées.
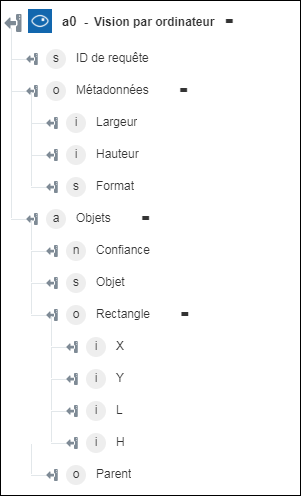
◦ Générer une miniature : renvoie la miniature de l'image.

◦ Extraire le texte imprimé (OCR) : renvoie le texte extrait de l'image.
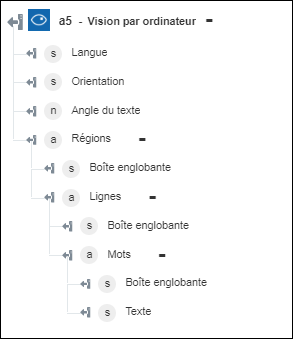
◦ Extraire le texte manuscrit : renvoie le texte manuscrit de l'image.
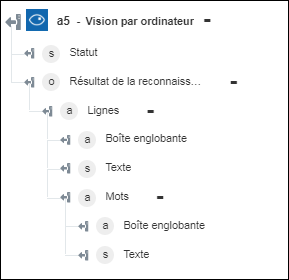
◦ Identifier l'image par tags : renvoie les tags détectés pour l'image.
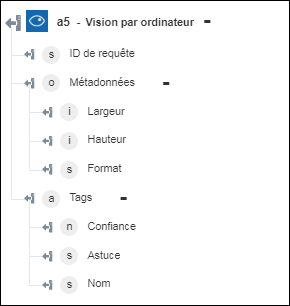
◦ Obtenir les centres d'intérêt renvoie les coordonnées localisant la zone la plus importante de l'image.