Computer Vision
Azure Computer Vision proporciona a los desarrolladores algoritmos avanzados que procesan imágenes y devuelven información. Para analizar una imagen, se puede cargar una imagen o especificar un URL de imagen. Los algoritmos de procesamiento pueden analizar el contenido de imágenes de diferentes maneras, en función de las distintas funciones visuales. Por ejemplo, Computer Vision puede encontrar todas las caras humanas de una imagen. Para obtener más información, consulte Azure Computer Vision.
Utilice la acción Computer Vision para analizar una imagen, analizar una imagen por dominio, describir una imagen y detectar y proporcionar información sobre las funciones y características visuales de una imagen.
Asegúrese de que la imagen cumpla los siguientes requisitos:
• Formato JPEG, PNG, GIF o BMP.
• El tamaño del fichero es inferior a 4 MB.
• Las cotas se encuentran entre 50 x 50 píxeles y 4200 x 4200 píxeles.
• El tamaño no es mayor que 10 megapíxeles.
Complete los siguientes pasos para utilizar la acción Computer Vision en el flujo de trabajo:
1. Arrastre la acción Computer Vision de Azure al lienzo, coloque el puntero sobre la acción y, a continuación, pulse en  o pulse dos veces en la acción. Se abre la ventana Computer Vision.
o pulse dos veces en la acción. Se abre la ventana Computer Vision.
o pulse dos veces en la acción. Se abre la ventana Computer Vision.2. Si fuera necesario, modifique el valor de Rótulo. Por defecto, el nombre de rótulo es igual que el nombre de acción.
3. Para añadir un tipo de conector de Azure, consulte Tipos de conector de Azure soportados.
Si se ha añadido previamente un tipo de conector, seleccione el valor de Tipo de conector apropiado y, en Nombre de conector, seleccione el conector.
4. Pulse en Probar para validar el conector.
5. Pulse en Asignar conector para ejecutar la acción mediante un conector que sea diferente del que se utiliza para rellenar los campos de entrada. En el campo Conector de tiempo de ejecución, proporcione un nombre de conector de Azure válido. Para obtener más información sobre la opción Asignar conector, consulte el tema sobre el uso de la asignación del conector.
Si el valor de Tipo de conector seleccionado es Ninguno, la opción Asignar conector no está disponible.
6. En la lista Grupo de recursos, seleccione el grupo de recursos adecuado que se define en la suscripción de Azure.
7. En el campo Cuenta de Computer Vision, seleccione la cuenta de Computer Vision adecuada.
8. En la lista Proporcionar imagen por, seleccione una de las siguientes opciones y realice lo siguiente:
◦ Seleccione URL y, en el campo URL de imagen, especifique un URL de imagen de acceso público.
◦ Seleccione Cargar fichero y, en el campo Ruta del fichero de imagen, asigne la salida de una acción anterior para proporcionar la ruta a una imagen.
9. En la lista Seleccionar servicio específico, en función del tipo de análisis de imagen que desee realizar, seleccione uno de los siguientes servicios de Custom Vision y realice su tarea correspondiente:
Servicio | Tarea |
|---|---|
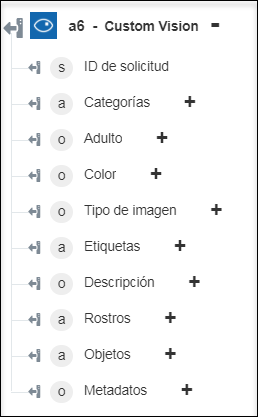
Analizar imagen: permite extraer un conjunto enriquecido de funciones visuales de la imagen. | a. En la lista Características visuales, seleccione las funciones que se deben utilizar para el análisis de la imagen: ◦ Categorías: permite categorizar el contenido de la imagen según la taxonomía de la categoría. ◦ Descripción: permite describir el contenido de la imagen con una frase completa en inglés. ◦ Color: permite determinar si la imagen está en blanco y negro o en color y, en el caso de las imágenes en color, se detectan los colores dominante y de acento. ◦ Etiquetas: permite etiquetar la imagen con una lista detallada de palabras relacionadas con el contenido de la imagen. ◦ Rostros: permite detectar si hay caras presentes en la imagen. ◦ Tipo de imagen: permite detectar si una imagen es una imagen prediseñada o un diseño de líneas. ◦ Adulto: permite detectar si la imagen es de naturaleza pornográfica o si representa contenido sexual. ◦ Objetos: permite detectar varios objetos de la imagen. Pulse en Añadir para añadir varias funciones visuales. Pulse en  para borrar cualquier característica visual que se haya añadido. para borrar cualquier característica visual que se haya añadido.b. En Detalles, pulse en Añadir y, a continuación, seleccione uno de los siguientes detalles específicos del dominio que desea incluir: ◦ Celebridades: permite identificar celebridades detectadas en la imagen. ◦ Puntos de referencia: permite identificar puntos de referencia significativos en la imagen. Pulse en Añadir para añadir varios detalles. Pulse en para borrar los detalles que se hayan añadido. |
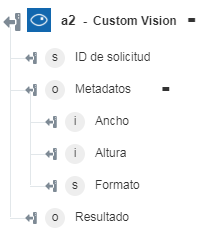
Analizar imagen por dominio: permite reconocer el contenido de una imagen mediante la aplicación de un modelo específico del dominio. | a. En el campo Modelo, especifique el modelo específico del dominio que se debe utilizar para analizar la imagen. b. En el campo Idioma, seleccione el idioma en el que desea generar la salida. Por defecto, se selecciona Inglés. |
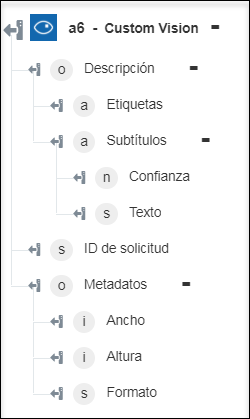
Describir imagen: permite describir el contenido de la imagen en oraciones completas legibles para el hombre. | a. En el campo Máx. de candidatos, introduzca el número máximo de descripciones de candidatos que el servicio debe devolver. b. En la lista Idioma, seleccione el idioma en el que desea generar la salida. Por defecto, se selecciona Inglés. |
Detectar objetos: permite realizar la detección de objetos en la imagen. | No se requiere ninguna acción. |
Generar imagen reducida: permite generar una imagen reducida de la imagen especificada. | a. En el campo Ancho, especifique el ancho de la imagen reducida entre 1 y 1024 píxeles. Se recomienda especificar un valor de al menos 50. b. En el campo Altura, especifique la altura de la imagen reducida entre 1 y 1024 píxeles. Se recomienda especificar un valor de al menos 50. c. En la lista Recorte inteligente, seleccione verdadero para activar el recorte inteligente. Seleccione falso si no desea activar el recorte inteligente. |
Extraer texto impreso (OCR): permite detectar el texto de una imagen y extraer los caracteres reconocidos en un flujo de caracteres legible por máquina. | a. En la lista Idioma, seleccione el idioma del texto de la imagen. Por defecto, se selecciona Desconocido. b. En la lista Detectar orientación, seleccione verdadero para detectar la orientación del texto en la imagen y corregirla antes de procesarla. Seleccione falso si no desea que el servicio detecte la orientación del texto en la imagen. |
Extraer texto escrito a mano: permite extraer texto escrito a mano de una imagen. | No se requiere ninguna acción. |
Etiquetar imagen: permite generar una lista de etiquetas que son relevantes para el contenido de la imagen. | En la lista Idioma, seleccione el idioma en el que desea generar la salida. Por defecto, se selecciona Inglés. |
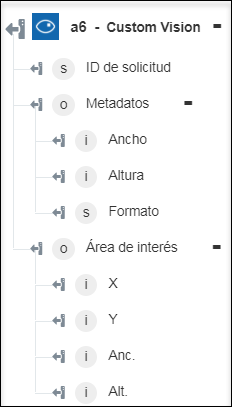
Extraer área de interés: permite devolver una caja alrededor del área más importante de la imagen. | No se requiere ninguna acción. |
10. Pulse en Terminado.
Esquema de salida
Cada servicio de Computer Vision tiene su propio esquema de salida.
◦ Analizar imagen: permite devolver las funciones visuales seleccionadas.
◦ Analizar imagen por dominio: permite devolver el contenido reconocido de la imagen.
◦ Describir imagen: permite devolver la descripción de la imagen.
◦ Detectar objetos: permite devolver los objetos y sus coordenadas.
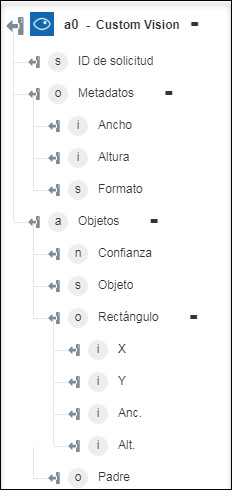
◦ Generar imagen reducida: permite devolver la imagen reducida.

◦ Extraer texto impreso (OCR): permite devolver el texto extraído de la imagen.
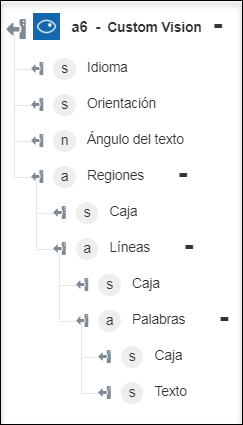
◦ Extraer texto escrito a mano: permite devolver el texto escrito a mano de la imagen.
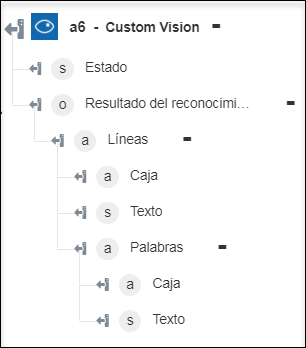
◦ Etiquetar imagen: permite devolver las etiquetas detectadas de la imagen.

◦ Extraer área de interés: permite devolver las coordenadas alrededor del área más importante de la imagen.