Data Storage Options
PTC supports the following storage options:
• Model providers
◦ H2
• Data providers
◦ InfluxDB
H2
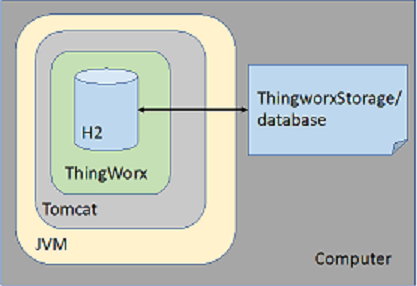
H2 is an open-source relational database with a low disk footprint. It is written in Java that can be embedded in Java applications or run in the client-server mode and provides a JDBC API. H2 fulfills both model and data provider requirements for ThingWorx. ThingWorx opens a persistent (as opposed to in-memory) H2 database in embedded mode. While this is the fastest and easiest connection mode, the database is only open within the same JVM as Tomcat with ThingWorx web application using JDBC (external processes cannot connect or use this database instance). As a persistent database, the data is written to the local disk (in the database folder in ThingworxStorage) and is retained after the ThingWorx restart.
Reference http://www.h2database.com.
Typical Use Cases
• Trials, developer systems, proof of concepts, near edge devices
• Strictly for single server deployments
Limitations
H2 is not recommended for production use due to its embedded nature:
• Limited scalability because it shares the resources (CPU, memory, disk, etc.) with the application
• Compromises the stability of the application as a whole. For example, if Tomcat crashes or the Tomcat process ends, it also terminates the database processes, which can lead to data corruption.
• It is more difficult to troubleshoot performance issues by isolating the bottlenecks in the application code or the database
• From a general operations and administration perspective, visualizing the data, backups, and disaster recovery can be more difficult to maintain.
For information about using H2 as a persistence provider for ThingWorx, see Using H2 as the Persistence Provider.
PostgreSQL
PostgreSQL is an open-source object relational database management system (ORDBMS) with an emphasis on extensibility and compliance to standards. As a database server, its primary function is to store data securely, and to retrieve data at the request of other software applications. It can handle workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users. PostgreSQL provides high-availability capability at the database level. It can be set up with one master and multiple secondary nodes in the same or different availability zones.
For more information on ThingWorx and PostgreSQL deployments, refer to the following documents:
Refer to https://www.postgresql.org/ for more information on PostgreSQL.
Typical Use Cases
The database scales for small, medium, and large implementations up to 15,000 property writes per second (wps) and provides high-availability functionality.
Microsoft SQL Server (MSSQL)
Microsoft SQL Server (MSSQL) is a relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications, which may run either on the same computer or on another computer across a network (including the Internet). For more information on ThingWorx and Microsoft SQL Server deployments, refer to Using Microsoft SQL Server as the Persistence Provider .
You can choose from several SQL Server editions to best fit your data solution. These editions have a maximum relational database size ranging from a small 10 GB to an extremely large 524 million GB. To attain high availability, it is recommended to use the Enterprise edition.
MSSQL, via its persistence provider, supports both model and data providers.
Reference https://www.microsoft.com/en-us/sql-server/sql-server-2016 for more information on Microsoft SQL Server.
Typical Use Cases
The SQL Server works for small to large IoT implementations. However, it is best used when Microsoft SQL/Azure is already in your IT Stack and your staff is familiar with implementing MSSQL Server high availability solution as per SQL Server 2017 scenarios using the availability features.
Azure SQL Database
Azure SQL Database is a relational database-as-a-service (DBaaS) hosted in Azure cloud and is a fully managed Platform as a Service (PaaS) Database Engine. Azure SQL database engine is based on the Enterprise Edition of SQL Server. The Azure platform fully manages every Azure SQL Database and guarantees no data loss and high percentage of data availability. Azure SQL Database comes with built in high availability, disaster recovery, and upgrade for the database.
Refer to https://docs.microsoft.com/en-us/azure/sql-database/sql-database-paas for more information on Azure SQL Database and its features. For information on using Azure SQL Database as a ThingWorx persistence provider, refer to Using Azure SQL Database as the Persistence Provider.
InfluxDB
You must have ThingWorx 8.4 or later to use InfluxDB. If your system intensively deals with time series data and your implementation heavily depends on value streams or streams for persistence/retrieval of data, we recommend using InfluxDB as the persistence provider in ThingWorx. InfluxDB is a high-performance data store written specifically for time series data. It allows for high throughput ingest, compression, and real-time querying of that same data. InfluxDB is used as a data store for any use case involving large amounts of time-stamped data, including DevOps monitoring, log data, application metrics, IoT sensor data, and real-time analytics. It also provides other capabilities, including Data Retention Policies (RP) etc. The InfluxDB enterprise offers high availability and highly scalable clustering solution for time series data needs.
The InfluxPersistenceProviderPackage is available in ThingWorx to be used with persistence providers as part of default installation for PostgreSQL or MSSQL.
• The InfluxDB data provider currently supports value streams and streams only. The support for data tables, wikis, and blogs is not available.
• The InfluxDB data provider does not currently support export functionality.
• InfluxDB is not currently supported as a property provider.
If you are using a persistence provider instance (created using InfluxDB persistence provider package) as the default persistence provider, you can edit the stream and value stream queue configurations settings, which will apply to all streams and value streams. You cannot change these settings for a specific stream or value stream.
For information about using InfluxDB as a Persistence Provider, see Using InfluxDB as the Persistence Provider