ThingWorx High Availability
Overview of ThingWorx High Availability Clustering
To reduce the duration of outages for critical Internet of Things (IoT) systems, you can configure ThingWorx to operate in a High Availability (HA) environment in cluster mode. Clustering provides additional scalability and high availability, assuming all components are configured properly.
|
|
HA clustering should not be used for a disaster recovery solution.
|
|
|
Using multiple availability zones for an HA deployment is not supported. The network latency between zones can be too great for constant communication between ThingWorx and Apache Ignite nodes.
|
The following sections outline the setup and configuration of a clustering environment and the components and considerations for a ThingWorx HA deployment.
All HA deployments require additional resources when compared to a deployment designed only to meet functional and scale requirements. These additional resources are hardware based (such as servers, disks, load balancers, and so forth) and software based (such as synchronization services and load balancers). The additional resources are then configured to ensure there are no single points of failure within the HA deployment.
All HA deployments should be based from an SLA (Service Level Agreement) where you have analyzed their uptime requirements of the application for your deployment. For example, how many hours per month can the system be offline? Is this allowed downtime for system failures, application upgrades, or both? The number of additional resources required for an HA system depends on the SLA it is designed to achieve. In general, as the SLA grows so does the need for resources to fulfill it.
Glossary of Terms
• high availability
A system or component that is continuously operational for a desirably long amount of time.
• scalability
The ability to increase the load that a system can support by increasing memory, disk, or CPU, or by adding servers.
• cluster
Instances of the same application that can simultaneously function. A cluster provides high availability and scalability.
• singleton
The singleton server is one server in the cluster that will handle cross-clusters behaviors such as timers and schedulers. It ensures that tasks are run only once within the cluster.
• virtual IP address
An IP address that represents an application. Clients that use the virtual IP are usually routed to a load balancer that then directs the request to the server running the application.
• load balancer
A device that receives network traffic and distributes it to the application(s) ready to accept it.
• failover
A backup operational mode in which the functions of a system component (such as a processor, server, network, or database) are assumed by secondary system components when the primary component becomes unavailable due to failure or scheduled down time.
• eventual consistency
Changes take time to propagate to all servers in a cluster environment.For more information, see Eventual Consistency.
• shared state
A state that is shared across multiple servers in the cluster and is guaranteed to be the same regardless of which server looks at it.Property data is an example of shared state, where the current property value is the same in all servers.
ThingWorx Reference Architecture for High Availability
The following image shows ThingWorx in a cluster configuration.
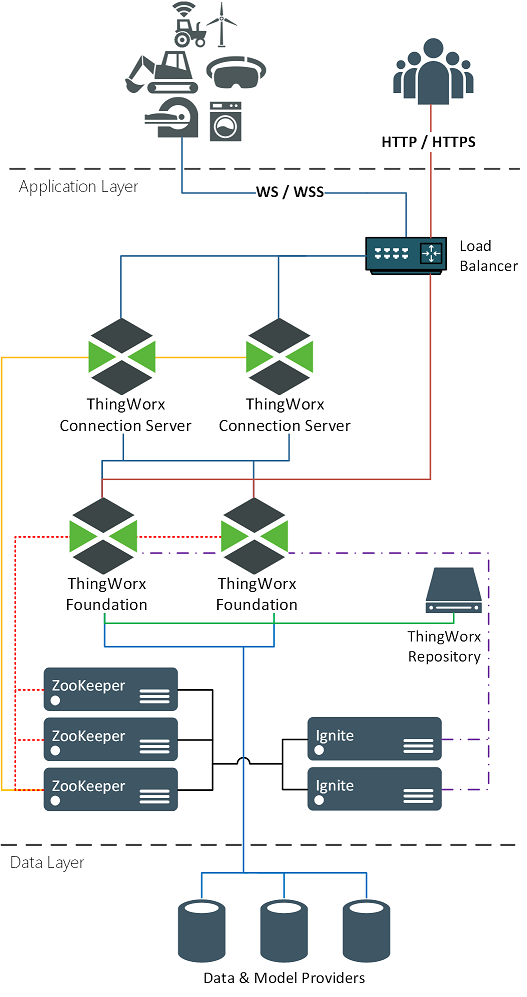
The following components can be part of a cluster deployment:
• Users and Devices- No role in HA functionality. From their perspective nothing changes. They always use the same URLs and IP address even if there is a change in the primary ThingWorx server.
• Firewalls- No HA function and can be considered optional. Firewalls are often placed to implement security requirements.
• Load Balancers- Load balancers manage a virtual IP address for the application they are supporting. All traffic routed to that virtual IP address is directed to the active application that can receive it.
• ThingWorx Connection Servers- Receives web socket traffic from assets and route it to the ThingWorx Platform. The connection servers can operate in a cluster configuration. Once an asset is directed to a specific Connection Server, it should always use the same connection server. If that server goes offline, then the asset should be redirected to another available Connection Server.
• ThingWorx Foundation- Receives all user and asset traffic.
• ThingWorx Repositories- These are required storage locations such as ThingworxPlatform, ThingworxStorage, and ThingworxBackupStorage, and any additional storage locations added to support your implementation. For a cluster environment, the storage folders must exist in a common storage location where all ThingWorx servers can equally access them.
• Apache ZooKeeper- ZooKeeper is a centralized coordination service used by ThingWorx Connection Server and Ignite for service discovery, singleton election, and distributed coordination.
• Apache Ignite- Ignite provides a distributed memory cache for sharing state across servers in the cluster.
• PostgreSQL- For an HA configuration, PostgreSQL will operate through two or more server nodes in a hot standby configuration. One node receives all write traffic, and one of the other nodes can receive all read traffic. Streaming replication is activated between all nodes to keep each node up to date.
• Pgpool-II- This is only used in PostgreSQL HA configurations. Pgpool-II nodes receive the ThingWorx requests (reads and writes) and directs them to the appropriate PostgreSQL node. It also monitors the health of each PostgreSQL node and can initiate failover and retargeting tasks when one of the nodes goes offline.
• Microsoft SQL Server (not pictured)- Microsoft Failover is used to ensure at least one MS SQL server is online and available.
• InfluxDB- An InfluxDB implementation is not required for a ThingWorx clustering configuration. If it is needed to meet the ingestion requirements of the implementation, then ensure it is configured for HA.