ThingWorx Foundation Bereitstellungskomponenten
ThingWorx Komponenten können in drei Ebenen eingeteilt werden: Client, Anwendung und Daten. Die folgende Abbildung zeigt einen grundlegenden Ausgangspunkt für jede ThingWorx Lösung:
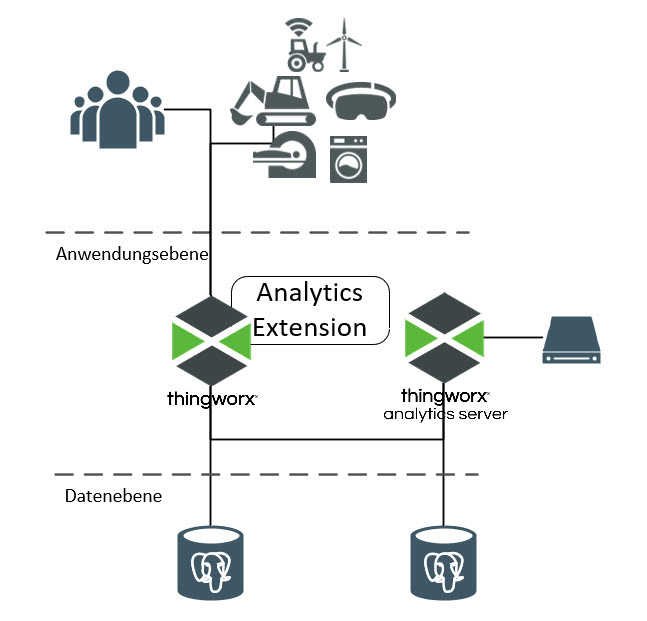 |
Dinge/Geräte: Diese Ebene enthält die Dinge, Geräte, Agents und andere Assets, die eine Verbindung zur ThingWorx Plattform herstellen, Daten an diese senden und Inhalte von ihr empfangen.
Benutzer/Clients: Diese Ebene enthält die Produkte (hauptsächlich Web-Browser), die Benutzer verwenden, um auf die ThingWorx Plattform zuzugreifen.
|
|
Plattform: Auf der Plattformebene (oder Anwendungsschicht) befindet sich ThingWorx Foundation, das als Hub eines ThingWorx Systems fungiert. Diese Ebene stellt Konnektivität zur Client-Ebene bereit, führt Authentifizierungs- und Autorisierungsprüfungen durch, nimmt Inhalte auf und verarbeitet/analysiert sie und reagiert auf Bedingungen wie das Senden von Warnungen.
|
|
|
Datenbank: Die Datenbankebene verwaltet ThingWorx Laufzeitmodell-Metadaten und Systemdaten:
• Zu den Modell-Metadaten gehören ThingWorx Entitätsdefinitionen, Dingdefinitionen und ihre zugeordneten Eigenschaftsdefinitionen.
• Laufzeitdaten, die für das ThingWorx Modell aufgenommen wurden. Bei den Daten kann es sich entweder um Tabellendaten oder Zeitreihendaten handeln, die vom ThingWorx Modell als Inhaltszeilen in Blogs, Wikis, Streams, Wert-Streams und Datentabellen persistent gemacht werden.
|
Mit dem Wachstum der ThingWorx Lösung im Hinblick auf Funktion und Komplexität steigen die architektonischen Anforderungen innerhalb jeder Ebene.
In den folgenden Abschnitten wird jede Komponente einer ThingWorx Lösung innerhalb der Ebene oder Schicht vorgestellt, in der die Komponente arbeitet.
Benutzer-/Client-Komponenten
Der Benutzer oder Client, der über ThingWorx Composer oder Laufzeit-Mashups auf die ThingWorx Platform zugreift, muss einen modernen Browser besitzen, der HTML/HTML5 unterstützt (Beispiele: Microsoft Edge, Firefox, Safari oder Chrome).
Ding-/Gerätekomponenten
• ThingWorx Edge MicroServer – Der ThingWorx Edge MicroServer (EMS) arbeitet mit Edge-Geräten oder Datenspeichern, die über das Internet eine Verbindung zum ThingWorx Server herstellen müssen. Dadurch können Geräte und Datenspeicher hinter Firewalls sicher mit dem ThingWorx Server kommunizieren und vollwertige Teilnehmer in der Lösungslandschaft sein. ThingWorx EMS ist kein einfacher Konnektor, sondern ermöglicht die Verschiebung von Intelligenz und Vorverarbeitung von Daten auf das Edge-Gerät.
• ThingWorx Edge SDKs – ThingWorx Edge SDKs sind Sammlungen von Klassen, Objekten, Funktionen, Methoden und Variablen, die ein Framework zum Erstellen von Anwendungen bereitstellen, die Daten sicher von Edge-Geräten an die ThingWorx Platform senden können. ThingWorx Edge SDKs bieten Tools für Entwickler, die in den Programmiersprachen C, .NET und Java erfahren sind.
ThingWorx EMS und ThingWorx Edge SDKs unterstützen Verbindungen über Proxies. Der Prozess der Verwaltung der Proxy-Konfiguration und des damit verbundenen Änderungsmanagements variiert je nach Kunde und/oder Projekt. ThingWorx Edge SDKs bieten höchste Flexibilität, da die SDK-Bibliotheken von jeder benutzerdefinierten Edge-Komponente eingeschlossen oder referenziert werden können und daher basierend auf der Konstruktion der Lösung aktualisiert werden können.
Plattformkomponenten
• ThingWorx Connection Server – Der ThingWorx Connection Server ist eine Serveranwendung, die die Verbindung von Remote-Geräten vereinfacht und das gesamte Nachrichten-Routing zu und von den Geräten übernimmt. Der ThingWorx Connection Server bietet skalierbare Konnektivität über WebSockets mithilfe des ThingWorx AlwaysOn-Kommunikationsprotokolls. PTC empfiehlt, Verbindungsserver zu verwenden, wenn es mehr als 25.000 Assets gibt, um die Verwaltung von Verbindungen vom ThingWorx Foundation Server auszulagern. Verbindungsserver sind in Hochverfügbarkeitskonfigurationen erforderlich, um Geräteverbindungen über die aktiven Cluster-Knoten zu verteilen. PTC empfiehlt außerdem mindestens einen Verbindungsserver für alle 100.000 simultanen Verbindungen mit dem ThingWorx Foundation Server. Dieses Verhältnis von Geräten zu Verbindungsserver kann sich abhängig von vielen Faktoren ändern, wie z.B. den Folgenden:
◦ Die Anzahl der Geräte
◦ Die Häufigkeit von Schreibvorgängen von den Geräten
• Tomcat – Apache Tomcat ist ein Open-Source-Servlet-Container, der von der Apache Software Foundation (ASF) entwickelt wurde. Tomcat implementiert die Spezifikationen Java Servlet und Java Server Pages (JSP) der Oracle Corporation und bietet eine reine Java-HTTP-Web-Server-Umgebung, in der Java-Code ausgeführt werden soll.
• ThingWorx Foundation Server – ThingWorx Foundation bietet eine vollständige Konstruktions-, Laufzeit- und Intelligenzumgebung für Machine-to-Machine(M2M)- und IoT-Anwendungen. ThingWorx Foundation wurde entwickelt, um Anwendungen, die Daten von Remote-Assets steuern und melden, wie verbundene Geräte, Maschinen, Sensoren und Industrieausrüstung, effizient zu erzeugen, auszuführen und zu erweitern.
ThingWorx Foundation dient als Hub Ihrer ThingWorx Umgebung. Es enthält Werkzeugsätze, mit denen Sie Anwendungen entwickeln können, um das Verhalten von Remote-Assets (oder Geräten) zu definieren, die in Ihrer Umgebung bereitgestellt werden, und Beziehungen zwischen den Assets.
Nachdem die Assets modelliert wurden, können sie sich registrieren und mit ThingWorx Foundation kommunizieren, sodass Sie die physischen Geräte überwachen und verwalten und Daten von ihnen sammeln können.
Datenbankkomponenten
Die ThingWorx Platform bietet ein austauschbares Datenspeichermodell, das es jedem Kunden ermöglicht, die Datenbank auszuwählen, die seinen Anforderungen am besten entspricht – von kleinen Implementierungen für Demo- oder Schulungsumgebungen bis hin zu hoch verfügbaren Datenbanken mit hohem Volumen, die Tausende von Transaktionen pro Sekunde unterstützen.
Wert-Streams, Streams, Datentabellen, Blogs und Wikis sind als Datenanbieter für ThingWorx definiert. Datenanbieter sind Datenbanken, die Laufzeitdaten speichern. Laufzeitdaten sind Daten, die persistent gemacht werden, sobald Dinge zusammengestellt und von verbundenen Geräten zum Speichern von Daten verwendet wurden (wie Temperatur, Feuchtigkeit oder Position). Modellanbieter werden verwendet, um Metadaten über die Dinge zu speichern.
Persistenzanbieter können einen Datenanbieter, einen Modellanbieter oder beides enthalten.
Weitere Informationen zu Datenbankoptionen finden Sie unter Persistenzanbieter.
Hochverfügbarkeitskomponenten
Hohe Verfügbarkeit ist ein wichtiger Aspekt für die Geschäftskontinuität. Hochverfügbarkeitskomponenten müssen sowohl auf Anwendungs- als auch auf Datenbankebene angewendet werden, um effektiv zu sein.
Ab Version 9.0 kann ThingWorx in einer Cluster-Konfiguration mit mehreren aktiven Serverknoten bereitgestellt werden, die Geschäftslogik und Benutzeranforderungen verarbeiten. Diese Konfiguration ersetzt die aktiv-passiv-Failover-Konfiguration aus früheren Versionen.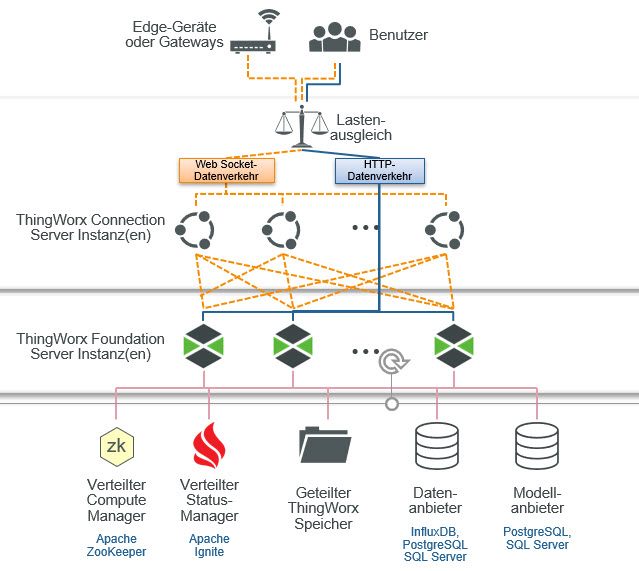
In einer Cluster-Konfiguration sind Verbindungsserver erforderlich, um Geräteverbindungen über die aktiven Clusterknoten zu verteilen.
Die ThingWorx Anwendungsebene erfordert Apache ZooKeeper und Apache Ignite als zusätzliche Komponenten. Die Anforderungen an Hochverfügbarkeit auf Datenbankebene hängen von den Anforderungen der ausgewählten Datenanbieter ab.
Die Überlegungen in puncto Hochverfügbarkeit gehen über den Software-Stack hinaus, damit diese wirklich effektiv ist. Redundante Infrastrukturen wie Netzteile, Festplatten und Netzwerkinfrastruktur (Router, Lastenausgleichsmodule, Firewalls usw.) sollten ebenfalls bewertet werden. |
• ZooKeeper – Apache ZooKeeper ist ein zentralisierter Dienst für die Verwaltung von Konfigurationsinformationen, die Benennung, die Bereitstellung verteilter Synchronisierungen und von Gruppendiensten. Es handelt sich um einen Koordinationsdienst für verteilte Anwendungen, der die Synchronisierung über einen Cluster hinweg ermöglicht. Speziell im Falle von ThingWorx wird ZooKeeper verwendet, um die Cluster-Knotenverfügbarkeit zu überwachen und im Falle eines Ausfalls einen neuen ThingWorx Foundation Führungsknoten zu wählen.
• Ignite – Apache Ignite ist eine verteilte Datenbank-, Caching- und Verarbeitungsplattform im Open-Source-Format zum Speichern und Berechnen großer Datenmengen über einen Cluster von Knoten. In einer ThingWorx Cluster-Bereitstellung wird Ignite verwendet, um einen geteilten Cache für Gerätedaten über alle Knoten im Cluster hinweg zu speichern und zu verwalten.
Hochverfügbarkeitsbereitstellung mit minimalem Footprint
Ignite kann innerhalb des ThingWorx Foundation Prozesses eingebettet ausgeführt werden, wofür keine separate Installation erforderlich ist. Ignite sollte nur eingebettet verwendet werden, wenn der Footprint der Umgebung wichtiger ist als die Leistung. Es sollte für kleine Umgebungen verwendet werden, die nur hohe Verfügbarkeit und keine Skalierung benötigen. Es ist nicht skalierbar und keine Lösung für Leistungsprobleme.
In einem Szenario mit eingebettetem Ignite und zwei Servern ist der einzige Vorteil das Lesen. Ignite kennzeichnet einige Daten als primär auf Server A, einige Daten als primär auf Server B und den anderen Server als Sicherung für die Daten. Normalerweise werden alle Lesevorgänge für die Daten auf dem Hauptserver ausgeführt. Dies kann ein Remote-Aufruf sein. Wenn Ignite eingebettet ist, liegt der Hauptunterschied darin, dass Sie die Option zum Lesen von der Sicherung auf "true" festlegen können. In diesem Fall wird beim Lesen kein Netzwerk-Hop durchgeführt.
Schreibvorgänge werden evtl. nicht auf demselben Rechner durchgeführt und verursachen eine Sicherung auf dem anderen Rechner. Daher gibt es keinen Leistungsvorteil für Schreibvorgänge.
Das Ausführen von Ignite in eingebetteter Form kann die Leistung je nach Größe des Rechners reduzieren. Ein ThingWorx Setup auf einem einzelnen Server und eine Ignite-Serverinstanz in einem HA-Cluster unterscheiden sich:
• Der Arbeitsspeicher wird mit der Plattform geteilt. Ignite fügt zusätzliche Warteschlangen und andere Dinge als Ergänzung zum Arbeitsspeicher für Eigenschaften hinzu.
• Eine JVM hat eine begrenzte Anzahl von Threads, die jederzeit basierend auf der Anzahl der CPUs aktiv sein können. Ignite braucht viele Threads, um Anforderungen zu verarbeiten, Daten zu sichern und für einige Ausnahmeaufgaben. Ein einzelner Server hat diese Last nicht.
• Alle Objekte zum und vom Cache werden in und aus dem Cache in einem HA-System serialisiert, was bei der Caffeine Cache-Schicht in einem Setup mit einem einzelnen Server nicht der Fall ist.
Hochverfügbarkeitsfunktionen für Datenbanken
• PostgreSQL – ThingWorx unterstützt die Verwendung von PostgreSQL-Hochverfügbarkeit als Datenlösung. Hochverfügbarkeit ermöglicht es Ihnen, separate Server einzurichten, um Lese- und Schreibvorgänge für Daten zu erfassen, wenn auf dem Hauptserver ein Fehler auftritt. Weitere Informationen dazu finden Sie unter Hochverfügbarkeit mit PostgreSQL.
• SQL Server – Im Allgemeinen eignet sich die SQL Standard Edition für den Einsatz in der Produktion, da sie die meisten erforderlichen Funktionen unterstützt. Für Produktionsumgebungen, die Hochverfügbarkeitsfunktionen, OLTP im Speicher oder Tabellen- und Indexpartitionierung erfordern, wird die SQL Enterprise Edition empfohlen. Weitere Informationen dazu finden Sie unter Hochverfügbarkeit mit Microsoft SQL Server.
• InfluxDB Enterprise – Stellt eine Cluster-Version der InfluxDB-Datenbank bereit. Das Clustering ermöglicht es, Daten über Knoten hinweg zu teilen, um sowohl hohe Verfügbarkeit als auch horizontale Skalierung zu unterstützen. So können Lese- und Abfragevorgänge auf verschiedenen Servern ausgeführt werden, um die Skalierbarkeit des gesamten Systems zu erhöhen. Die Anzahl der Datenknoten kann problemlos erweitert werden, um neue Arbeitslasten zu unterstützen. Weitere Informationen finden Sie unter InfluxDB als Persistenzanbieter verwenden.