InfluxDB als Persistenzanbieter verwenden
Übersicht
Wenn Sie in Ihrem System intensiv mit Zeitreihendaten arbeiten und sich Ihre Implementierung für Persistenz/Datenabrufe stark auf Wert-Streams oder Streams stützt, empfehlen wir die Verwendung von InfluxDB als Persistenzanbieter in ThingWorx. InfluxDB ist ein hochleistungsfähiger Datenspeicher, der speziell für Zeitreihendaten entwickelt wurde. Er ermöglicht Datenaufnahme mit hohem Durchsatz sowie Komprimierung und Echtzeitabfragen der erfassten Daten. InfluxDB kommt in allen Anwendungsfällen als Datenspeicher zum Einsatz, bei denen große Mengen von Daten mit Zeitstempel verarbeitet werden, beispielsweise DevOps-Überwachungsdaten, Protokolldaten, Anwendungsmetriken, Daten von IoT-Sensoren oder Echtzeitanalysedaten. Der Datenspeicher stellt auch andere Funktionen bereit, unter anderem Datenaufbewahrungsrichtlinien. InfluxDB Enterprise bietet Hochverfügbarkeit sowie eine hochgradig skalierbare Clustering-Lösung für Anwendungsfälle mit Zeitreihendaten.
InfluxDB-Datenpersistenz-Speicheranbieter sind als Teil der Standardinstallation für PostgreSQL, MS SQL oder Azure SQL verfügbar, die für Eigenschaftsanbieter verwendet werden:
• InfluxPersistenceProviderPackage
• Influx2PersistenceProviderPackage
ThingWorx unterstützt OSS-, Enterprise- und Cloud-Versionen.
• InfluxDB OSS 1.x und InfluxDB Enterprise 1.x werden über InfluxPersistenceProviderPackage unterstützt. InfluxDB Enterprise wird nur von InfluxDB 1.x unterstützt.
• InfluxDB OSS 2.x wird über Influx2PersistenceProviderPackage unterstützt.
• InfluxDB Cloud wird nur über Influx2PersistenceProviderPackage unterstützt.
Unter Release Advisor finden Sie die unterstützten spezifischen Versionen.
|
|
Unterstützung für Influx 2.0 wurde ab 9.3.1 zu ThingWorx hinzugefügt.
|
|
|
Der InfluxDB-Datenanbieter unterstützt derzeit ausschließlich Wert-Streams und Streams. Unterstützung für Datentabellen, Wikis und Blogs ist nicht verfügbar.
|
|
|
Datenexport wird mit InfluxPersistenceProviderPackage unterstützt. Ab ThingWorx 9.3.8 wird Datenexport jetzt mit Influx2PersistenceProviderPackage unterstützt.
|
|
|
InfluxDB wird nicht als Eigenschaftsanbieter unterstützt.
|
|
|
Kunden, die ein Upgrade auf ThingWorx 9.3.9 und höher sowie ThingWorx 9.4.0 und höher durchführen möchten und InfluxDB OSS 2.0 verwenden, müssen zur Nutzung von Influx2PersistenceProviderPackage zunächst ein Upgrade auf ThingWorx 9.3.8 durchführen, um zu InfluxDB OSS v2.6 zu wechseln, da vor dem Upgrade auf InfluxDB v2.6 ein Export erforderlich ist. Für InfluxDB Cloud ist kein Export vor dem Upgrade erforderlich. Daher ist es nicht erforderlich, vor einem Upgrade auf ThingWorx 9.3.9 und höher sowie ThingWorx 9.4.0 und höher zu ThingWorx 9.3.8 zu wechseln.
|
Ausgangsarchitektur mit InfluxDB Enterprise und ThingWorx
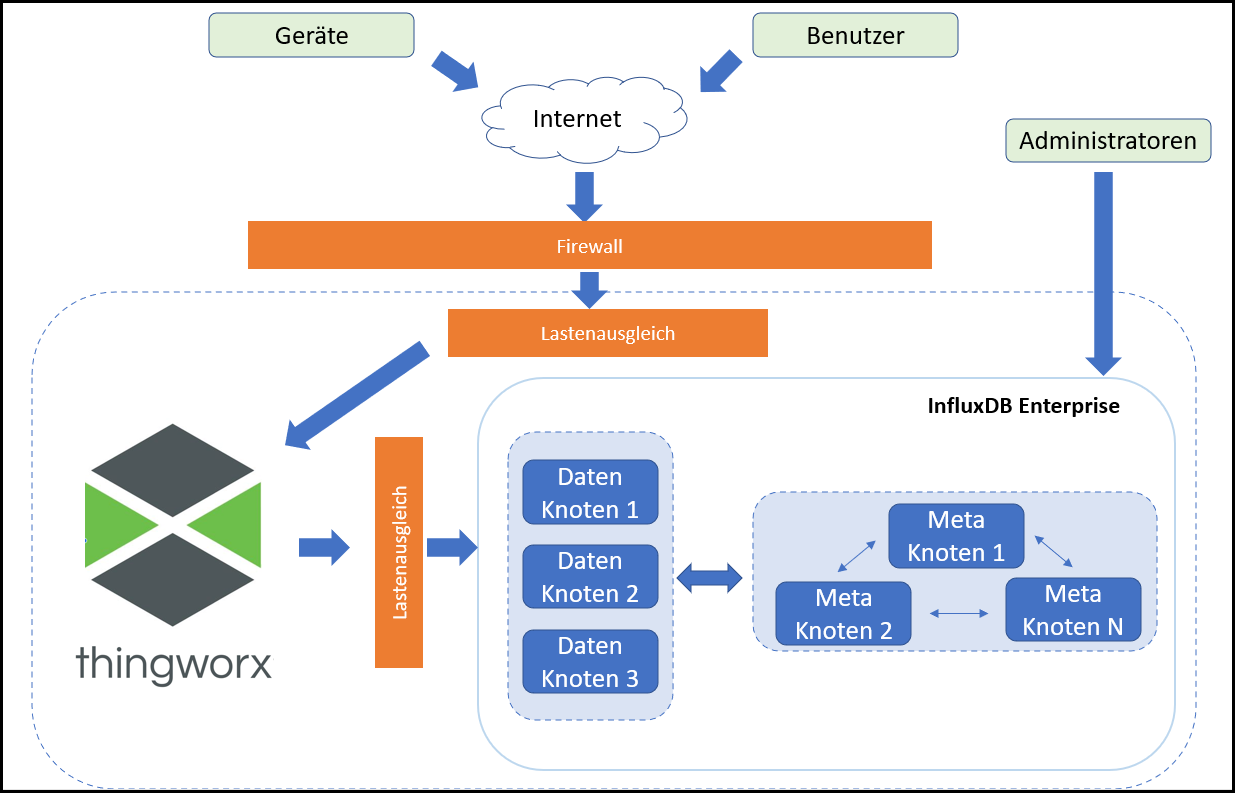
Im Diagramm oben wird InfluxDB Enterprise verwendet. Bei Verwendung von InfluxDB Open Source würde das Architekturdiagramm identisch aussehen, jedoch mit nur einem Knoten arbeiten. Für InfluxDB Cloud wird die Datenbank außerhalb der ThingWorx Umgebung gehostet und vom InfluxData-Unternehmen verwaltet. |
Die folgenden Begriffe werden in dieser Dokumentation verwendet, wenn auf die Konfiguration für InfluxDB Enterprise Bezug genommen wird:
• Lastenausgleich: InfluxDB Enterprise lässt sich nicht zum Lastenausgleich verwenden. Dieser muss von einem Administrator konfiguriert werden.
• Cluster: Ein InfluxDB Enterprise-Cluster besteht aus zwei Typen von Knoten – Metaknoten und Datenknoten.
• Datenknoten: Hier liegen sämtliche Roh-Zeitreihendaten. Für Hochverfügbarkeit ist mindestens ein Replikationsfaktor von 2 erforderlich.
• Metaknoten: Die Aufgabe dieser Knoten ist einfach – sie müssen den Status konsistent halten. Sie enthalten lediglich grundlegende Statusinformationen wie Aufbewahrungsrichtlinien, Benutzer und Datenbanken. In Umgebungen mit Hochverfügbarkeit sind mindestens drei Metaknoten erforderlich.
Weitere Informationen zum Thema Hochverfügbarkeit finden Sie unter https://www.influxdata.com/blog/understanding-influxenterprise-what-is-a-cluster/.
Auswahl der richtigen Influx-Datenbankoption
Nachfolgend finden Sie eine Übersicht der zwei InfluxDB-Optionen, die derzeit für PTC Kunden lokal verfügbar sind. Die Datenbank-Software-Optionen und die zugrunde liegenden Support-Optionen sollten bei der Wahl eines Influx-Produkts sorgfältig abgewogen werden. Wenden Sie sich bei Fragen zur Auswahl der richtigen Datenbankoptionen an den Influx-Support unter: https://www.influxdata.com/contact-sales. PTC Kunden sollten die Angabe machen, dass sie PTC ThingWorx Benutzer sind.
• InfluxDB Open Source OSS (einzelner Knoten)
◦ Nur einzelner Knoten, nicht skalierbar
◦ Kostenlos
◦ Community-basierter Influx-Support, verfügbar auf der Influx-Community-Website unter InfluxData Community Forums.
◦ Nicht empfohlen für Produktionsinstanzen aufgrund eingeschränkten technischen Supports durch Influx (kein Live-Support in dringenden Situationen)
◦ PTC Kunde ist verantwortlich für Pflege und Überwachung der Datenbank.
◦ PTC ist bestrebt, die besten Empfehlungen hinsichtlich Influx zu geben, doch in einigen Situationen ist eine Eskalation an den technischen Support von Influx erforderlich.
• InfluxDB Enterprise
Wenn Sie einen Datenspeicher für höhere Datenvolumen und Durchsatzgeschwindigkeiten suchen, als sie derzeit mit anderen Datenbanken möglich sind, kann InfluxDB Enterprise Ihnen folgende Vorteile bieten:
◦ Höhere Datenaufnahmerate
◦ Sie können mehr als ein Daten-Repository für Laufzeitdaten nutzen. Beispielsweise können Sie relationale Daten in PostgreSQL hinterlegen und InfluxDB für Stream- und Wert-Stream-Daten verwenden, die in großen Mengen anfallen. Wenn Sie einen Stream oder Wert-Stream definieren, verwendet ThingWorx den standardmäßigen Laufzeitdatenspeicher-Anbieter. Sie können die Konfiguration aber auch so anpassen, dass ein beliebiger angegebener Persistenzanbieter verwendet wird. Sie können weiterhin Daten von anderen Datenanbietern exportieren und in InfluxDB importieren. ThingWorx kümmert sich um die Datenabstrahierung.
◦ Cloud-fähige Architektur (horizontal skalierbar, jedoch nur mit InfluxDB Enterprise)
◦ Hohe Verfügbarkeit
◦ Technischer Support durch Influx nach Abschluss eines Vertrags über die Influx Support-Website unter InfluxData.
◦ PTC Kunde kann, falls erforderlich, Tickets bei Influx eröffnen und um Zusammenarbeit mit PTC zu bitten.
◦ PTC Kunde ist verantwortlich für Pflege und Überwachung der Datenbank.
• InfluxDB Cloud (außerhalb der ThingWorx Umgebung gehostet und vom InfluxData-Unternehmen verwaltet)
InfluxDB Cloud bietet die folgenden Vorteile:
◦ InfluxDB Cloud ist eine cloudnative, elastisch skalierbare, serverlose Plattform für mehrere Mandanten.
◦ Die Plattform bietet Verfügbarkeit, Dauerhaftigkeit und Skalierbarkeit in mehreren Regionen unter AWS, Google und Azure.
◦ Sie ist sicher und gehärtet, und alle aktuellen Sicherheitsfunktionen und Patches sind installiert und konfiguriert.
◦ InfluxDB Cloud gleicht Cluster automatisch aus, verarbeitet Sharding und nutzt integrierte Replikationsfaktoren.
InfluxDB installieren und konfigurieren
Es liegt in der Verantwortung desjenigen, der die Influx-Datenbank installiert, die gesamte sicherheitsbezogene Dokumentation, die für InfluxDB bereitgestellt wird, zu lesen und zu verstehen. PTC empfiehlt dringend, InfluxDB mit sicheren Konfigurationen zu installieren und zu konfigurieren, einschließlich Verwendung von Benutzername und starkem Passwort. |
Dieser Prozess setzt voraus, dass ThingWorx installiert ist. Weitere Informationen finden Sie unter ThingWorx installieren. |
Wenn sich InfluxDB und ThingWorx auf Rechnern mit unterschiedlichen Zeitzonen befinden, kann es Probleme beim Abrufen von Daten geben. Um diese Probleme zu vermeiden, wird eine der folgenden Bereitstellungsoptionen empfohlen: • Stellen Sie InfluxDB und ThingWorx auf demselben Host/Rechner bereit. • Wenn InfluxDB und ThingWorx auf verschiedenen Hosts/Rechnern bereitgestellt werden, sollte die Zeitzone des InfluxDB-Servers auf den -Duser.timezone Tomcat-Parameter abgestimmt und die Uhren sollten synchronisiert sein, um Probleme im Zusammenhang mit den Abfrageergebnissen zu vermeiden. |
1. Influx DB herunterladen und installieren
◦ Richtlinien für das Herunterladen und Installieren von InfluxDB 2.0:
▪ InfluxDB Open Source (Einzelknoten): Referenzieren Sie InfluxDB als Persistenzanbieter verwenden Download-Links – Datenknoten:
▪ InfluxDB Enterprise (hohe Verfügbarkeit): nicht verfügbar für Influx 2.0
◦ Richtlinien für das Herunterladen und Installieren von InfluxDB 1.x:
InfluxDB wird unter Windows nicht unterstützt. In der Anleitung unten wird das Betriebssystem UNIX verwendet. |
▪ InfluxDB Open Source (einzelner Knoten): Siehe die englische Referenz Install InfluxDB
Download-Link:
▪ InfluxDB Enterprise (hohe Verfügbarkeit): Siehe die englische Referenz Install an InfluxDB Enterprise cluster in your own environment
Download-Links – Datenknoten:
Download-Links – Meta-Knoten:
2. Für Influx1
Erstellen Sie eine Datenbank in InfluxDB. Laden Sie das Skript thingworxInfluxDBSetup.sh herunter, und führen Sie es aus, um die Datenbank in InfluxDB zu erstellen. Die InfluxDB-Befehlszeilenschnittstelle muss an dem Speicherort verfügbar sein, von dem aus das Skript ausgeführt wird. Weitere Informationen finden Sie auf der englischen Seite Launchinflux.
Das Skript thingworxInfluxDBSetup.sh steht im PTC Support-Portal im Ordner install des Software-Download-Pakets zur Verfügung. |
Der folgende Beispielbefehl erstellt eine Datenbank mit den standardmäßigen Aufbewahrungsrichtlinien:
CREATE DATABASE thingworx with DURATION 365d REPLICATION 1 SHARD DURATION 30d NAME autogen
Der InfluxDB-Datenanbieter unterstützt derzeit nur eine Aufbewahrungsrichtlinie mit Namen autogen. Beim Erstellen der Datenbank, die mit dem Datenanbieter verwendet werden soll, können Sie den Namen der Richtlinie und andere Richtlinien wie etwa Replikationsfaktor angeben. |
Erstellen Sie einen InfluxDB-Benutzer über die InfluxDB-Befehlszeilenschnittstelle. Der folgende Beispielbefehl erstellt einen Benutzer:
CREATE USER twadmin WITH PASSWORD 'password' WITH ALL PRIVILEGES
3. Erstellen Sie für Influx2 den anfänglichen Bucket und Benutzer mit dem folgenden Befehl: influx setup. Weitere Informationen finden Sie unter https://docs.influxdata.com/influxdb/v2.0/reference/cli/influx/setup/.
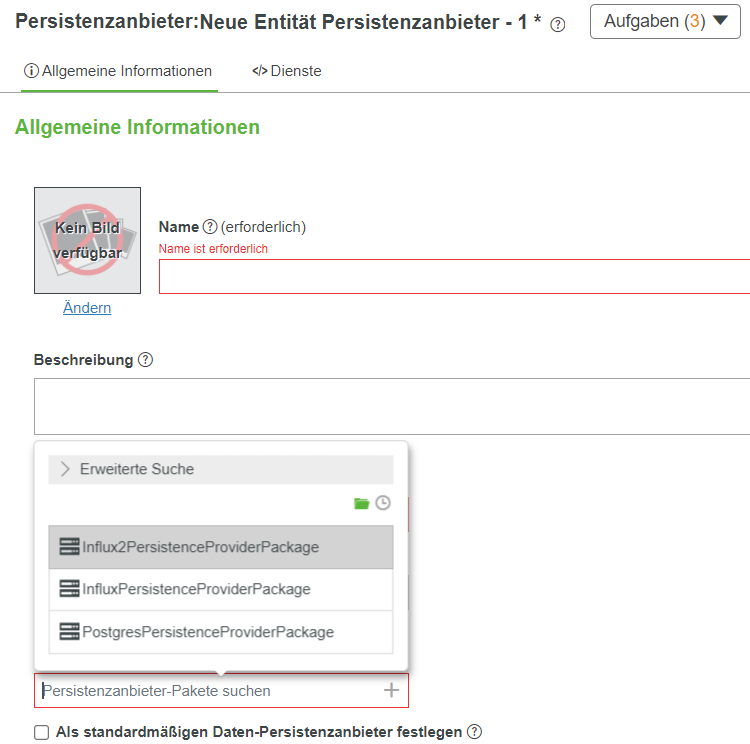
4. Erstellen Sie in ThingWorx Composer einen neuen Persistenzanbieter.

5. Wählen Sie im Feld Persistenzanbieter-Paket Folgendes aus:
◦ Wählen Sie InfluxPersistenceProviderPackage für Versionen kleiner als Influx 2.0.
◦ Wählen Sie Influx2PersistenceProviderPackage für Influx 2.0.
6. Klicken Sie auf Speichern.
7. Klicken Sie auf die Registerkarte Konfiguration, konfigurieren Sie die Verbindungsinformationen nach Bedarf, und speichern Sie. Die Konfigurationsoptionen finden Sie in den Tabellen unten.
Wenn Sie eine (mit dem InfluxDB Persistenzanbieter-Paket erstellte) Persistenzanbieter-Instanz als standardmäßigen Persistenzanbieter verwenden, können Sie die nachfolgend aufgeführten Konfigurationseinstellungen für Stream- und Wert-Stream-Warteschlangen bearbeiten. Diese Bearbeitungen werden auf alle Streams und Wert-Streams angewendet. Sie können diese Einstellungen für einen bestimmten Stream oder Wert-Stream nicht ändern.
Wenn Sie den Persistenzanbieter eines Wert-Streams wechseln (beispielsweise von ThingworxPersistenceProvider zu InfluxPersistenceProviderPackage), muss jedes Ding, das einen Wert-Stream implementiert, den Dienst RestartThing aufrufen, um in den neuen Persistenzanbieter geschriebene Einträge abrufen zu können. Wenn die Dinge nicht neu gestartet werden, werden die Einträge zwar eventuell in die Datenbank geschrieben; sie werden jedoch erst abgerufen, wenn das Ding neu gestartet wurde. |

Name | Beschreibung | Standardwert | ||
|---|---|---|---|---|
Verbindungs-URL | URL der Datenbank, von der Sie Verbindungen abrufen sollen. | http://localhost:8086 | ||
Token | Anstelle eines Passworts wird das Sicherheitstoken für den Zugriff auf das System verwendet (wie ein Anwendungsschlüssel). | |||
Organisationsname | Name der Organisation | |||
Bucket-Name | Name des Daten-Buckets (Schema, in dem alle Daten gespeichert sind) | |||
Automatische Bucket-Erstellung | Bei Einstellung auf wahr wird der in bucketName angegebene Bucket erstellt, wenn er nicht bereits vorhanden ist. Andernfalls tritt ein Fehler auf. | False | ||
Aufbewahrungszeitraum (Tage) | Anzahl der Tage, die Daten beibehalten werden. Daten werden nach Verstreichen dieses Zeitraums gelöscht. Standardeinstellung 0 (Daten für immer beibehalten). | 0 | ||
Batch-Größe | Dies ist die vom Influx-Client verwendete Batch-Größe. Es werden immer Datenpunkte in Batches gesendet, um die Leistung zu erhöhen. Dies ist eine Ergänzung zur Batch-Größe des Streams. Wenn die Anzahl der Datenpunkte in Batch-Größe bereit zum Senden ist, werden die Daten an Influx gesendet.
| 1000 | ||
Intervall für Leerung | Gibt an, wie oft der Influx-Client Daten leert, wenn die Batch-Größe nicht erreicht wurde. Der Wert wird in Millisekunden angegeben.
| 1000 oder einmal pro Sekunde | ||
Abrufgröße der Daten vom Persistenzanbieter | Anzahl der Zeilen, die in Gruppen abgerufen werden, statt alle Zeilen auf Client-Seite zwischenzuspeichern. | 5000 | ||
Verbindungstimeout (Zeit) | Dauer für Verbindungsversuch mit Influx. Der Wert wird in Sekunden angegeben. | 10 | ||
Lesetimeout (Zeit) | Zeit, die benötigt wird, um Daten aus Influx für eine Anforderung zu lesen. Der Wert wird in Sekunden angegeben. | 10 | ||
Schreibtimeout (Zeit) | Zeit, die benötigt wird, um zu versuchen, Daten in Influx zu schreiben. Der Wert wird in Sekunden angegeben.
| 10 | ||
Protokollebene | Die Protokollebene des Influx-Clients und die Protokolle werden an die Konsolenausgabe gesendet. Die Werte können NONE, BASIC, HEADERS oder BODY sein, wobei jede Ebene weitere Informationen bereitstellt. | KEINE |
Name | Beschreibung | Standardwert |
|---|---|---|
Verbindungs-URL | URL der Datenbank, von der Sie Verbindungen abrufen sollen. | http://localhost:8086 |
Datenbankschema | Schema für Verbindungen | thingworx |
Benutzername | Benutzername zum Abrufen einer Datenbankverbindung. | twadmin |
Passwort | Passwort zum Abrufen einer Datenbankverbindung. | N/A |
Abrufgröße der Daten vom Persistenzanbieter | Abrufgröße der Daten vom Persistenzanbieter. | 5000 |
Verbindungstimeout (Zeit) | Zeit in Sekunden für ein Verbindungstimeout. | 10 |
Lesetimeout (Zeit) | Zeit in Sekunden für ein Lesetimeout. | 10 |
Schreibtimeout (Zeit) | Zeit in Sekunden für ein Schreibtimeout. | 10 |
Name | Beschreibung | Basistyp | Standardwert | ||
|---|---|---|---|---|---|
Maximale Warteschlangengröße | Maximale Anzahl der Stream-Einträge in der Warteschlange. Sobald der angegebene Wert erreicht ist, werden die nachfolgenden Einträge zurückgewiesen. | Number | 250000 | ||
Maximale Wartezeit vor der Leerung des Stream-Puffers (Millisek.) | Anzahl der Millisekunden, die das System wartet, bevor der Stream-Puffer geleert wird. | Number | 2000 | ||
Anzahl der Verarbeitungs-Threads | Anzahl der Verarbeitungs-Threads, die dem Stream zugeordnet sind
| Number | 5 | ||
Maximale Anzahl der Elemente vor der Leerung des Stream-Puffers | Maximale Anzahl von Elementen, die erfasst werden, bevor der Stream-Puffer geleert wird. | Number | 1000 | ||
Maximale Anzahl der Wert-Stream-Schreibvorgänge im Verarbeitungsblock | Maximale Anzahl der Stream-Schreibvorgänge zum Verarbeiten in einem Block | Number | 2500 | ||
Pufferstatus-Scanrate (Millisek.) | Der Pufferstatus wird in der angegebenen Rate in Millisekunden geprüft. | Number | 5 |
Name | Beschreibung | Basistyp | Standardwert | ||
|---|---|---|---|---|---|
Maximale Warteschlangengröße | Maximale Anzahl der Wert-Stream-Einträge in der Warteschlange. Sobald der angegebene Wert erreicht ist, werden die folgenden Einträge zurückgewiesen. | Number | 500000 | ||
Maximale Wartezeit vor der Leerung des Wert-Stream-Puffers (Millisek.) | Anzahl der Millisekunden, die das System wartet, bevor der Wert-Stream-Puffer geleert wird. | Number | 10000 | ||
Anzahl der Verarbeitungs-Threads | Anzahl der Verarbeitungs-Threads, die dem Wert-Stream zugeordnet sind
| Number | 5 | ||
Maximale Anzahl der Elemente vor der Leerung des Wert-Puffers | Maximale Anzahl von Elementen, die erfasst werden, bevor der Wert-Stream-Puffer geleert wird. | Number | 1000 | ||
Maximale Anzahl der Wert-Stream-Schreibvorgänge im Verarbeitungsblock | Maximale Anzahl von Elementen zum Verarbeiten in einem Block | Number | 2500 | ||
Pufferstatus-Scanrate (Millisek.) | Der Pufferstatus wird in der angegebenen Rate in Millisekunden geprüft. | Number | 5 |
8. Klicken Sie auf die Registerkarte Allgemeine Informationen, und aktivieren Sie das Kontrollkästchen Aktiv.
9. Klicken Sie auf Speichern.
Optimale Vorgehensweisen
Reihengrenzwert
Eine Reihe ist die Gesamtzahl der Eigenschaften aller Dinge, die bei InfluxDB angemeldet sind. InfluxDB bietet ein gutes Leistungsniveau bei hohen Datenvolumen, die an eine kleine Anzahl von Dingen und Dingeigenschaften gesendet werden (beispielsweise mehrere Zehntausend oder mehrere Hunderttausend). Die Gesamtzahl an Reihen ist in InfluxDB standardmäßig auf 1 Million begrenzt. Dieser Grenzwert kann heraufgesetzt werden. Die Leistung von InfluxDB sinkt jedoch kontinuierlich, je höher die Reihenanzahl über diesem Grenzwert liegt.
Wenn Sie mit einer großen Anzahl von Dingen und Eigenschaften arbeiten, können Sie diejenigen mit dem höchsten Datenvolumen wählen und nur diese mit InfluxDB verknüpfen. Das entlastet PostgreSQL bzw. MSSQL.
Wenn Sie die Reihen auf mehrere Server aufteilen möchten, können Sie alternativ mehrere Instanzen des InfluxDB-Datenanbieters verwenden, die jeweils auf unterschiedliche InfluxDB-Serverinstanzen verweisen.
Grenzwert für Schreibvorgänge
Der Grenzwert beträgt 100.000 Schreibvorgänge pro Sekunde bei einer VM mit 60 GB Arbeitsspeicher und 32 Kernen. Eine Überschreitung dieses Grenzwerts kann Probleme in ThingWorx verursachen: Es können dann Ressourcen für die Verarbeitung jeglicher Anforderungen oder Jobs fehlen, beispielsweise für Schreibvorgänge in die Datenbank. Passiert das, stürzt ThingWorx ab, während InfluxDB weiterhin in die Datenbank schreibt. Dieses Problem tritt bei PostgreSQL nicht auf, weil PostgreSQL zum Engpass wird und ThingWorx zu keinem Zeitpunkt die nötigen Ressourcen fehlen, um interne Aufgaben zu bearbeiten.
SSL/sichere Verbindung
InfluxDB unterstützt SSL- und HTTPS-Verbindungen. Sie können SSL- und HTTPS-Verbindungen aktivieren, um die Sicherheit zu erhöhen, wenn das Netzwerk zwischen ThingWorx und InfluxDB nicht unterstützt wird. Ein selbstsigniertes Zertifikat ist ausreichend, sofern der signierende private Schlüssel sicher aufbewahrt wird.
Bekannte Einschränkungen in InfluxDB bezüglich Eigenschaften-Basistypen
Sie können den Basistyp einer Eigenschaft nicht ändern, nachdem die Eigenschaft in einem Wert-Stream protokolliert wurde. Weitere Informationen finden Sie auf der englischen Seite Type conflict on insert int value in float field#3460.
Eigenschaften bereinigen
Die Dienste PurgeAllPropertyHistory, PurgeSelectedPropertyHistory und PurgePropertyHistory können verwendet werden, um Eigenschaften endgültig aus InfluxDB zu löschen (bereinigen). Verwenden Sie die Parameter startDate und endDate, um einen Bereich anzugeben.
Das Bereinigen wird bei Verwendung des Influx2PersistenceProviderPackage-Anbieters nicht unterstützt. Die Dienste PurgePropertyHistory, PurgeAllPropertyHistory und PurgeSelectedPropertyHistory haben keine Auswirkung. |