Statistik einer multivariaten Polynomregression
• polyfitstat(X, Y, n/"terms"/M, [conf]) – Übergibt statistische Daten für ein Polynomregressionsmodell und passt die in der Matrix Y erfassten Ergebnisse an die Daten in der Matrix X an. Die Polynomregressionsgleichung kann durch ihren Polynomgrad n oder durch ihre Ausdrücke definiert werden, die in der Zeichenfolge “terms” oder in der Matrix M angegeben werden. Verwenden Sie Matrix M, wenn der Achsenabschnitt nicht in die Polynomanpassung einbezogen werden soll. Verwenden Sie das optionale Argument conf, um ein anderes Konfidenzintervall anzugeben als das Standardintervall von 95 %.
Die zweite Spalte der von polyfitstat zurückgegebenen Matrix enthält folgende Elemente:
|
Zeile
|
Beschreibung
|
|---|---|
|
1
|
Die Standardabweichung für Y
|
|
2, 3, 4
|
R2, R2 angepasst und R2 vorhergesehen
|
|
5
|
PRESS – Vorhergesehene Fehlersumme der Quadrate (Prediction Error Sum of Squares) (nützlich für die Skalierung von Residuen)
|
|
6
|
Durbin-Watson-Teststatistik für Autokorrelationen
|
|
7
|
Matrix der Regressionskoeffizienten wie von polyfitc zurückgegeben
|
|
8
|
ANOVA-Matrix für das Regressionsmodell mit Spalten, die mit der von anova zurückgegebenen Ergebnistabelle übereinstimmt und folgende Zeilen aufweist:
• Regression – Teilsumme, die dann für jeden Term (ausgenommen intercept) aufgeschlüsselt wird
• Residuum (Fehler) – Teilsumme, die dann zwischen dem Passungsfehler und dem reinen Versuchsfehler aufgeschlüsselt wird
• Summe für das Regressionsmodell
|
|
9
|
Diagnosematrix mit folgenden Spalten:
1. Nummerierung für jeden Rechenlauf und Datenpunkt
2. Beobachtetes Ergebnis für jeden Rechenlauf und Datenpunkt
3. Von dem zu untersuchenden Regressionsmodell vorhergesagtes Ergebnis
4. Residuum – Differenz zwischen dem beobachteten und dem vorhergesagten Ergebnis
5. Hebelwirkung – Messung des Abstands zwischen dem beobachteten Ergebnis und dem Punkt in der Mitte aller beobachteten Ergebnisse
6. Student-verteiltes Residuum – Residuum dividiert durch die Varianz basierend auf dem beobachteten Ergebnis
7. R-Student – Residuum dividiert durch die Varianz basierend auf einem Datensatz, wobei das beobachtete Ergebnis entfernt wird
8. Cook-Abstand – Messung des Einflusses des beobachteten Ergebnisses auf alle anderen Datenpunkte
9. DFFITS – Differenz zwischen den von einem Regressionsmodell auf Basis eines Datensatzes mit inkludiertem beobachteten Ergebnis vorhergesagten Ergebnis und dem von einem anderen Modell, bei dem das beobachtete Ergebnis entfernt wurde, vorhergesagten Ergebnis
|
Argumente
• X ist eine Konstruktionsmatrix oder eine Matrix, in der jede Spalte eine unabhängige Variable darstellt. Jede Spalte von X muss kompatible Einheiten enthalten.
• Y ist ein Vektor oder eine Matrix gemessener oder simulierter Ergebnisse, wobei jede Zeile die Ergebnisse für jeden Rechenlauf oder alle in X definierten Datenpunkte enthält. Wenn die Zeilen nicht jeweils die gleiche Anzahl von Replikaten enthalten, müssen Sie die leeren Elemente von Y mit NaNs auffüllen. Die Elemente von Y müssen kompatible Einheiten enthalten.
• n ist eine Ganzzahl, die den Polynomgrad angibt. Sie muss kleiner sein als die Gesamtmenge der Datenpunkte: 1 ≤ n ≤ length(Y) − 1. Andernfalls ist das Problem unterbestimmt und hat keine eindeutige Lösung.
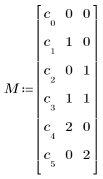
• “terms” ist eine Zeichenfolge, die Ausdrücke oder die Faktoren und Interaktionen angibt, die bei der Polynomregression einbezogen werden sollen. "A B AB AA BB" bedeutet, dass das Polynom die folgenden Ausdrücke enthält:
c0 + c1 ∙ A + c2 ∙ B + c3 ∙ A ∙ B + c4 ∙ A2 + c5 ∙ B2
Als Trennzeichen können Sie ein Leerzeichen, ein Komma, einen Doppelpunkt oder ein Semikolon verwenden.
• M ist eine Matrix, die ein Polynom angibt. Die erste Spalte enthält Schätzwerte für die Koeffizienten, die übrigen Spalten enthalten die Potenz der unabhängigen Variablen für jeden Ausdruck. Definieren Sie M für das oben beschriebene Polynom folgendermaßen:
• conf (optional) ist die gewünschte Vertrauensgrenze, ein als Zahl zwischen 0 und 1 (inklusive) ausgedrückter Prozentwert. Der Standardwert ist conf = 0.95 für ein Konfidenzintervall von 95 %.