Mélangez les caractères de la plupart des langues au sein d'une chaîne unique grâce à la prise en charge d'Unicode.
Creo Elements/Direct Modeling emploie le codage UTF-16 pour les chaînes et les données textuelles stockées en mémoire. Creo Elements/Direct Modeling peut donc traiter et prendre en charge une large plage de caractères internationaux. Plus précisément, tous les caractères du plan multilingue de base Unicode (points de code U+0000 à U+FFFF) sont gérés.
Vous pouvez utiliser des chaînes en allemand, en japonais, en chinois, en hébreu et en russe, par exemple, dans la même session. Vous pouvez même mélanger les caractères de toutes ces langues dans une chaîne unique.
Si la version de base de Creo Elements/Direct Modeling prend désormais en charge les caractères de toutes ces langues, cela ne signifie pas pour autant que des versions localisées sont disponibles pour toutes les langues.
Tous les formats de fichiers propres à Creo Elements/Direct Modeling gèrent maintenant les chaînes Unicode.
Les noms d'objet pouvant contenir n'importe quel type de caractère, Creo Elements/Direct Modeling exploite un algorithme pour définir la police par défaut de son interface graphique.
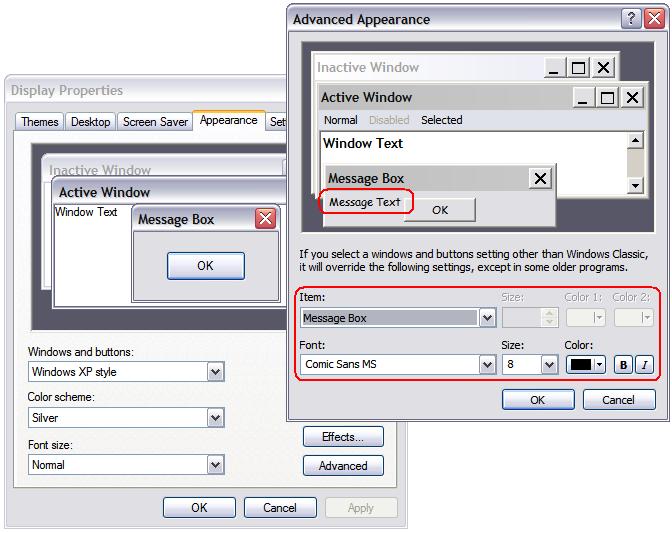
Windows fournit des valeurs par défaut pour les polices des éléments de l'interface. Creo Elements/Direct Modeling les consulte lors du démarrage, puis les exploite pour son interface. Vous pouvez vérifier et modifier ces valeurs par défaut dans la boîte de dialogue Apparence - paramètres avancés : Cliquez sur Démarrer > Paramètres > Panneau de configuration > Affichage, puis cliquez sur Avancé dans l'onglet Apparence.
Les polices affichées dans les différents éléments de l'interface utilisateur de Creo Elements/Direct Modeling proviennent du système d'exploitation et sont réparties comme suit :
Type de police Windows
Eléments de l'interface Creo Elements/Direct Modeling
Boîte de message
Tous les contrôles d'interface des boîtes de dialogue et des listes de navigation, à l'exception des champs d'édition multilignes
Menu
Barre de menus de l'application, menus contextuels
Info-bulle
Info-bulles, barre d'état
La police par défaut des contrôles d'édition multilignes est "MS Gothic" pour la version japonaise de Creo Elements/Direct Modeling et "Courier New" pour toutes les autres. Sa taille initiale dérive de la taille de la police de la boîte de message. Pour modifier ce paramètre, cliquez sur Fichier > Paramètres > IU . La boîte de dialogue Paramètres IU s'ouvre. Dans le volet Contrôles, cliquez sur le bouton Modifier pour changer la police.
Par défaut, les valeurs de police par défaut sélectionnées par Windows englobent tous les caractères de la langue du système d'exploitation. Si vous utilisez une version japonaise ou allemande de Windows, ces valeurs par défaut sont déjà définies. Vous pouvez alors saisir du texte en japonais ou en allemand sans problème.
Boîte de dialogue Sortie
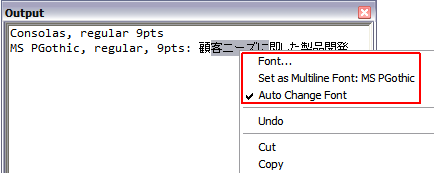
La boîte de dialogue Sortie possède trois options de menu contextuel liées à la prise en charge d'Unicode :
• Police : Définit la police du texte sélectionné. Si vous n'avez sélectionné aucun texte, Creo Elements/Direct Modeling applique la police spécifiée à tout texte saisi ultérieurement.
• Définir police multiligne : (nom de la police)
Ce raccourci est très pratique pour changer la police par défaut attribuée aux contrôles d'édition multilignes (similaire à Fichier > Paramètres > IU. La boîte de dialogue Paramètres IU s'ouvre. Dans le volet Contrôles, cliquez sur le bouton Modifier sous Police champ saisie multiligne). Cette option de menu contextuel n'est visible que si du texte est sélectionné et qu'il n'utilise qu'une police unique.
• Changer de police automatiquement : Cette option est activée par défaut. Ainsi, la boîte de dialogue Sortie change automatiquement la police active au fur et à mesure de l'ajout du texte. Par exemple, lorsque du texte en japonais est saisi et que la police active ne possède aucune définition de caractères japonais, la boîte de dialogue Sortie sélectionne automatiquement une police capable d'afficher les caractères japonais. Lorsque cette option est désactivée, la boîte de dialogue Sortie utilise la police de contrôle d'édition multiligne globale.
Ces options de menu sont également disponibles depuis le menu contextuel de l'éditeur de texte général.
Editeur de texte général
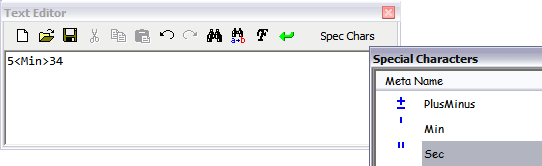
L'éditeur de texte général comporte une fonctionnalité de modification présente dans une barre d'outils ancrée au sommet de sa fenêtre. En fonction de la commande de démarrage de l'éditeur, un bouton supplémentaire, qui remplit une fonction particulière, peut apparaître à l'extrême droite de la barre d'outils. Par exemple, la commande Texte de Creo Elements/Direct Annotation affiche la mention Caract. Spéc. sur ce bouton. Ce dernier permet alors d'accéder au tableau des caractères spéciaux :
L'éditeur peut charger des fichiers texte en Unicode et dans les anciens codages. Lors de l'enregistrement de texte de l'éditeur, le fichier obtenu est toujours codé en UTF-8 et commence par une marque d'ordre d'octet UTF-8 (Byte-order marker - BOM).
Labels et polices
Creo Elements/Direct Modeling utilise des polices à trait pour afficher les labels et annotations dans ses clôtures 3D et 2D (c'est-à-dire à la fois pour le module Documentation 3D et pour Creo Elements/Direct Annotation). La police à trait par défaut est appelée osd_default ; elle combine les polices hp_i3098_v, hp_hangul_c et hp_kanj2_c. C'est pourquoi cette police englobe à la fois les caractères japonais et ceux d'Europe occidentale. Dans Creo Elements/Direct Annotation, deux autres polices par défaut sont disponibles :
Creo Elements/Direct Modeling n'établit aucune distinction entre les polices codées sur un octet et celles sur deux octets.
Pour améliorer la prise en charge des caractères Unicode, Creo Elements/Direct Modeling prend en charge les polices TrueType Windows. Creo Elements/Direct Modeling détecte automatiquement les polices TrueType installées et les convertit dans le format des polices à trait. Les boîtes de dialogue avec une liste de sélection de polices répertorient à la fois les polices à trait fournis par Creo Elements/Direct et celles dérivées des polices TrueType. Par conséquent, si vous devez afficher des annotations 3D en chinois, par exemple, vous pouvez installer une police TrueType Windows couvrant les points de code Unicode attribués aux caractères chinois comme la police MS Mincho. Ensuite, à partir de cette policeCreo Elements/Direct Modeling génère une police à trait utilisable pour les annotations 3D.
Si une annotation 3D comporte une police fusionnée, telle que osd_default, et qu'elle est enregistrée dans un ancien format Creo Elements/Direct Modeling rétrocompatible, Creo Elements/Direct Modeling n'attribue au label d'annotation que les polices constitutives de l'une des polices fusionnées. Le choix exact de la police dépend de la langue courante. Si la langue courante est le japonais, la sous-police à deux octets est utilisée. Sinon, la sous-police à un octet est employée.
Les symboles utilisent des polices distinctes (hp_symbols, hp_symbols2).
Les versions de Creo Elements/Direct Modeling antérieures à la version 2007 ne prenaient pas en charge l'intégralité de la plage des caractères Unicode et utilisaient des codages différents pour leurs chaînes de caractères. Il en va de même pour certaines applications pour lesquelles Creo Elements/Direct Modeling fournit des fonctionnalités d'exportation. Si vous exportez des données vers ces applications, Creo Elements/Direct Modeling doit convertir les chaînes de caractères codées en UTF-16 dans un codage et un jeu de caractères externes. Toutes les applications cible ne gérant pas l'intégralité de la plage des caractères Unicode, le processus de conversion peut se révéler incapable de transférer l'ensemble des caractères. Exemple : CoCreate Modeling 2006 et les versions antérieures n'ayant jamais pris en charge le russe, toute tentative d'exportation de caractères cyrilliques à partir de cette version de Creo Elements/Direct Modeling risque d'engendrer des pertes de données partielles.
Le
tableau des formats de fichiers indique les codages utilisés et pris en charge par les différentes fonctions d'importation et d'exportation de Creo Elements/Direct Modeling. En fonction du type de l'application à laquelle vous devez vous connecter, vous pouvez vous limiter à un sous-assemblage du jeu de caractères Unicode pris en charge à la fois par Creo Elements/Direct Modeling et l'application cible.
Les deux exemples suivants illustrent ce point.
• Supposez que vous utilisez la version actuelle de Creo Elements/Direct Modeling en langue allemande et que vous avez créé un modèle contenant à la fois des caractères allemands et chinois. Votre partenaire continuant d'utiliser CoCreate Modeling 2006, vous enregistrez donc ce modèle dans un mode rétrocompatible pour permettre l'échange de données. La version allemande de CoCreate Modeling 2006 exploite le format de codage HP-Roman8 pour coder les caractères des chaînes. Creo Elements/Direct Modeling effectue donc la conversion dans ce codage. Cependant, le codage HP-Roman8 ne couvre que les caractères anglais et européens, mais pas les caractères chinois. Les caractères chinois ne peuvent donc pas être convertis lorsqu'ils sont écrits dans le format de fichier de CoCreate Modeling 2006.
• Les fichiers VRML 1.0 codant les chaînes en US-ASCII, une implémentation stricte n'emploie que les caractères anglais lors de l'enregistrement de données dans ce format.
Lors du stockage des données de Creo Elements/Direct Modeling (format *.sd) dans un mode rétrocompatible, les chaînes et les noms doivent être convertis dans l'ancien codage. Les noms des objets apparaissant dans la liste des structures peuvent contenir des caractères non couverts par l'ancien codage particulier. Pour conserver l'unicité, ces caractères sont remplacés par une transcription Unicode hexadécimale (U+XXXX). Ce traitement spécial s'applique uniquement aux noms des objets. Dans les autres cas, comme dans les notes 3D, des caractères de soulignement remplacent les caractères non convertibles.
Lorsque vous rechargez ces fichiers dans la version actuelle de Creo Elements/Direct Modeling, les transcriptions U+XXXX ne sont pas reconverties en caractères Unicode correspondants.
Lors du chargement d'anciens fichiers, Creo Elements/Direct Modeling convertit automatiquement les chaînes de caractères dans son codage UTF-16 interne. Le codage source est déterminé de la manière suivante :
• Si l'ancien fichier contient des informations sur la langue utilisée pour les chaînes figurant dans ce fichier (versions 14.50 et supérieures), elles sont utilisées pour déduire le codage source. Par exemple, le codage HP-Roman8 est supposé pour les données d'Europe occidentale et le codage Shift-JIS pour les données japonaises.
• Si ces informations sont absentes (versions antérieures à CoCreate Modeling 2006/v14.0x, c'est-à-dire dans la majorité des cas), Creo Elements/Direct Modeling part du principe que le fichier à charger contient des chaînes de caractères dans la même langue que celle de Creo Elements/Direct Modeling. Ainsi, lors du chargement d'un fichier CoCreate Modeling 2004 dans la version allemande de Creo Elements/Direct Modeling, par exemple, Creo Elements/Direct Modeling suppose qu'il contient des chaînes de caractères en langue allemande et utilise le codage HP-Roman8.
Fondamentalement, il s'agit de la même hypothèse que dans les anciennes versions de Creo Elements/Direct Modeling. Toutefois, en raison de la conversion explicite effectuée à partir du codage Roman8 ou Shift-JIS lors du chargement de données anciennes dans Creo Elements/Direct Modeling, cette hypothèse a désormais des conséquences pratiques. Les tentatives de mélange et de mise en correspondance d'anciens codages de manière non autorisée (chargement de données japonaises dans une version anglaise, par exemple) peuvent entraîner des pertes de données.
• La liste des fichiers fournit également des options pour remplacer explicitement la détection et la conversion automatiques du codage. Elles s'avèrent utiles lors des tentatives de chargement d'un ancien fichier japonais dans une version allemande de CoCreate Modeling 2007.
Modification des fichiers texte Unicode
Tous les éditeurs de texte ne traitent pas correctement les fichiers de texte Unicode. Par exemple, WordPad (write.exe, fourni avec Windows) peut endommager les fichiers UTF-8 dont la taille est supérieure à 4094 octets. Microsoft fournit un
correctif pour remédier à ce problème. Il est disponible auprès de Microsoft sur simple demande. Toutefois, nous vous conseillons de ne pas utiliser WordPad pour modifier les fichiers UTF-8.
Creo Elements/Direct Modeling est fourni avec une version personnalisée de l'éditeur libre Notepad++, qui gère correctement à la fois les fichiers UTF-8 et les fichiers UTF-16. Des fichiers de coloration syntaxique sont également fournis pour le langage Lisp de Creo Elements/Direct Modeling et le langage de macro de Creo Elements/Direct Drafting. Si Notepad++ est installé sur votre système, Creo Elements/Direct Modeling l'utilise comme éditeur externe par défaut.
Autres éditeurs recommandés :
• vim et gvim avec les paramètres :set encoding=utf-8 et :set bomb.
• XEmacs 21.5 et versions supérieures.
• Emacs 22 et versions supérieures.
• Microsoft Visual Studio
• Vous pouvez également utiliser Notepad de Microsoft. Toutefois, Notepad ne gérant pas correctement les fins de ligne de style Unix, les fichiers doivent être convertis de manière à prendre en charge les fins de ligne de style DOS avant de les modifier.