Options de stockage des données
PTC prend en charge les options de stockage suivantes :
• Fournisseurs de modèles
• Fournisseurs de données
|
|
A compter de la version 8.5.0 de ThingWorx Platform, DataStax Enterprise n'est plus disponible à la vente et ne sera plus pris en charge dans les prochaines versions. Pour plus d'informations, reportez-vous à l'article concernant la
fin de sa commercialisation.
|
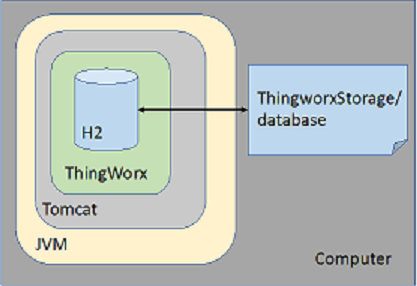
H2
H2 est une base de données relationnelle open source avec une faible empreinte sur disque. Ecrite dans Java, elle peut être intégrée aux applications Java ou exécutée en mode client-serveur et fournit une API JDBC. H2 répond à la fois aux exigences des fournisseurs de modèles et de données pour ThingWorx. ThingWorx ouvre une base de données H2 persistante (par opposition à en mémoire) en mode intégré. Bien qu'il s'agisse du mode de connexion le plus rapide et le plus simple, la base de données n'est ouverte que dans la même JVM que Tomcat, l'application Web ThingWorx utilisant JDBC (les processus externes ne peuvent pas se connecter, ni utiliser cette instance de base de données). En tant que base de données persistante, les données sont écrites sur le disque local (dans le dossier database dans ThingworxStorage) et sont conservées après le redémarrage de ThingWorx.
Cas d'utilisation typiques
• Essais, systèmes de développement, preuves de concepts, périphériques proches de l'Edge
• Destiné strictement aux déploiements sur un seul serveur
Limites
Etant intégré, H2 n'est pas recommandé pour une utilisation en production :
• Evolutivité limitée en raison d'un partage des ressources (processeur, mémoire, disque, etc.) avec l'application
• Compromet la stabilité de l'application dans son ensemble. Par exemple, si Tomcat se bloque ou que le processus Tomcat prend fin, les processus de base de données sont également interrompus, ce qui peut entraîner un endommagement des données.
• Il est plus difficile de résoudre les problèmes de performances en isolant les goulets d'étranglement dans le code d'application ou dans la base de données.
• En matière d'opérations et d'administration, la visualisation des données, les sauvegardes et la récupération d'urgence peuvent être plus difficiles à gérer.
Pour plus d'informations sur l'utilisation de H2 en tant que fournisseur de persistance pour ThingWorx, consultez la rubrique
Utilisation de H2 en tant que fournisseur de persistance.
PostgreSQL
PostgreSQL est un système de gestion de base de données relationnel-objet (SGBDRO) open source qui met l'accent sur l'extensibilité et la conformité aux normes. En tant que serveur de base de données, sa fonction principale est de stocker les données de manière sécurisée et de récupérer les données à la demande d'autres applications logicielles. Il est capable de gérer des charges de travail allant des petites applications monopostes aux applications Internet étendues impliquant de nombreux utilisateurs simultanés. PostgreSQL fournit une capacité de haute disponibilité au niveau de la base de données. Il peut être configuré avec un noeud maître et plusieurs noeuds esclaves dans des zones de disponibilité identiques ou distinctes.
Pour plus d'informations sur les déploiements ThingWorx et PostgreSQL, reportez-vous aux documents suivants :
Pour plus d'informations sur PostgreSQL, accédez à l'adresse
https://www.postgresql.org/.
Cas d'utilisation typiques
La base de données est mise à l'échelle pour les implémentations de petite, moyenne et grande envergure jusqu'à 15 000 écritures de propriétés par seconde et fournit une fonctionnalité haute disponibilité.
Microsoft SQL Server (MSSQL)
Microsoft SQL Server (MSSQL) est un système de gestion de base de données relationnelle développé par Microsoft. En tant que serveur de base de données, il s'agit d'un logiciel principalement dédié au stockage et à la récupération de données d'autres applications logicielles exécutées sur le même ordinateur ou sur un autre ordinateur via un réseau (y compris Internet). Pour plus d'informations sur les déploiements de ThingWorx et Microsoft SQL Server, consultez la rubrique
Utilisation de Microsoft SQL Server en tant que fournisseur de persistance .
Il existe plusieurs éditions de SQL Server, ce qui vous permet de choisir la version la plus adaptée à votre solution de données. Ces éditions offrent une taille maximale de base de données relationnelle allant de 10 Go à 524 millions de Go. Pour disposer d'un environnement haute disponibilité, il est recommandé d'utiliser l'édition Entreprise.
MSSQL, via son fournisseur de persistance, prend en charge les fournisseurs de modèles et de données.
Accédez à l'adresse
https://www.microsoft.com/en-us/sql-server/sql-server-2016 pour obtenir plus d'informations sur Microsoft SQL Server.
Cas d'utilisation typiques
SQL Server est adapté aux implémentations IoT de petite et grande envergure. Toutefois, il est préférable de l'utiliser lorsque Microsoft SQL/Azure est déjà présent dans votre pile informatique et que votre équipe maîtrise l'implémentation d'une solution MS SQL Server haute disponibilité conformément aux
scénarios SQL Server 2017 utilisant les fonctionnalités de disponibilité.
Base de données Azure SQL
Une base de données Azure SQL est une DBaaS (Database-as-a-Service) relationnelle hébergée sur le Cloud Azure ainsi qu'un moteur de base de données PaaS (Platform as a Service) entièrement géré. Le moteur de base de données Azure SQL est basé sur SQL Server Enterprise. La plateforme Azure gère entièrement chaque base de données Azure SQL, garantissant aucune perte de données et une haute disponibilité des données. Une base de données Azure SQL offre de base une haute disponibilité, une récupération d'urgence et une mise à niveau de la base de données.
Rendez-vous à l'adresse
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-paas pour en savoir plus sur les bases de données Azure SQL et leurs fonctionnalités. Pour plus d'informations sur l'utilisation d'une base de données Azure SQL en tant que fournisseur de persistance ThingWorx, consultez
Utilisation de la base de données Azure SQL en tant que fournisseur de persistance.
DataStax Enterprise (DSE)
A compter de la version 8.5.0 de ThingWorx Platform, DataStax Enterprise n'est plus disponible à la vente et ne sera plus pris en charge dans les prochaines versions. Pour plus d'informations, reportez-vous à l'article concernant la
fin de sa commercialisation. |
ThingWorx utilise également DataStax Enterprise (DSE), un fournisseur de magasin de données d'exécution haute volumétrie, basé sur Apache Cassandra. DSE permet une ingestion des données plus rapide que leurs actifs ne les génèrent et une mise à l'échelle transparente en cas d'ajout d'appareils supplémentaires (ou d'autres charges de travail). L'utilisation de DSE comme magasin de données d'exécution fournit une plateforme de base de données conçue pour répondre aux exigences de performance et de disponibilité des applications IoT, Web et mobiles.
La plupart des bases de données relationnelles ne permettent pas une mise à l'échelle horizontale, ni fonctionner sur un mode maître/esclave. En revanche, l'architecture de clustering pair-à-pair sans maître de Cassandra permet une évolutivité linéaire et à grande échelle.
DSE propose un déploiement de Cassandra entièrement testé et validé avec des outils d'administration et de surveillance avancés, une intégration de base de Solr pour l'indexation et la recherche, ainsi qu'un mécanisme de support et de correctifs. Cela coïncide directement avec le modèle de magasin de données enfichable qui permet aux clients de disposer de plusieurs référentiels de données pour stocker les données de configuration, les données de modèle et les grands volumes de données. Vous pouvez choisir le référentiel de données qui répond à vos exigences pour une fonction donnée.
DSE est un système de base de données intégré, actif en permanence et multimodèle avec des fonctionnalités d'analyse en temps réel et par lots utilisant Apache Spark, une technologie en mémoire, une fonction de recherche disponible en continu et le calcul de base de données orientée graphe. Il propose des outils avancés pour les opérations de système de développement et de production, des fonctionnalités flexibles telles que le stockage hiérarchisé pour répondre aux besoins d'accès aux données à court et long termes, une architecture mutualisée pour exécuter plusieurs clusters de base de données au sein du même système et une sécurité avancée pour répondre aux exigences de l'entreprise.
Le composant de recherche intégrée DSE (Apache Solr) de la pile DSE est requis pour que ThingWorx fonctionne. Par conséquent, ThingWorx ne peut pas fonctionner avec les installations Apache Cassandra open source dans lesquelles Apache Solr n'est pas intégré. |
DSE offre les avantages suivants aux plateformes ThingWorx qui nécessitent un magasin de données prenant en charge des volumes et vitesses de données supérieurs à ce qu'offrent H2 ou PostgreSQL :
• Fournit un taux plus élevé d'ingestion des données.
• Prend en charge plusieurs référentiels de données pour les données d'exécution (conservation des données de modèle dans H2 ou PostgreSQL et utilisation de DSE pour les données de flux haute volumétrie).
• Prend en charge les propriétés de mise à l'échelle élastique. Vous pouvez ajouter des noeuds supplémentaires à un anneau DSE pour des taux de transaction plus élevés.
• Sépare les processus de données des processus de plateforme.
• Prend en charge l'architecture compatible avec le cloud.
Pour plus d'informations, consultez le manuel anglais
Getting Started with DataStax Enterprise and ThingWorx et la rubrique
Utilisation de DataStax Enterprise en tant que fournisseur de persistance.
Cas d'utilisation type
Un cas d'utilisation type peut impliquer de grandes quantités (au-delà de 15 000 écritures par seconde) de données transactionnelles (exécution) sur une charge distribuée.
InfluxDB
Vous devez disposer de ThingWorx 8.4 ou version ultérieure pour utiliser InfluxDB. Si votre système traite intensivement des données de séries temporelles et que votre implémentation est fortement tributaire de flux ou flux de valeurs pour la persistance/récupération des données, nous vous recommandons d'utiliser InfluxDB comme fournisseur de persistance dans ThingWorx. InfluxDB est un magasin de données hautes performances écrit spécifiquement pour les données de séries temporelles. Il permet l'ingestion, la compression et l'interrogation en temps réel de ces données à haut débit. InfluxDB est utilisable comme magasin de données pour tout cas d'utilisation impliquant de grandes quantités de données horodatées, y compris la surveillance DevOps, les données des journaux, les mesures d'application, les données des capteurs IoT et l'analyse en temps réel. Il fournit également un certain nombre d'autres fonctionnalités, telles que des règles de rétention des données, par exemple. InfluxDB Enterprise offre une solution de clustering haute disponibilité et haute évolutivité pour les besoins liés aux données de séries temporelles.
Le package InfluxPersistenceProviderPackage est disponible dans ThingWorx pour utilisation avec des fournisseurs de persistance dans le cadre d'une installation par défaut pour PostgreSQL ou MSSQL.
• Le fournisseur de données InfluxDB ne prend actuellement en charge que les flux et les flux de valeurs. La prise en charge des tables de données, des wikis et des blogs n'est pas assurée.
• Le fournisseur de données InfluxDB ne prend actuellement pas en charge la fonctionnalité d'exportation.
• InfluxDB n'est actuellement pas pris en charge en tant que fournisseur de propriétés.
Si vous utilisez une instance du fournisseur de persistance (créée à l'aide du package du fournisseur de persistance InfluxDB) comme fournisseur de persistance par défaut, vous pouvez modifier les paramètres de configuration des files d'attente de flux et flux de valeurs, qui s'appliqueront à tous les flux et flux de valeur. Ces modifications ne peuvent pas être appliquées à un flux ou flux de valeurs spécifique.
Pour plus d'informations sur l'utilisation d'InfluxDB en tant que fournisseur de persistance, consultez la rubrique
Utilisation d'InfluxDB en tant que fournisseur de persistance.