Opciones de almacenamiento de datos
PTC soporta las siguientes opciones de almacenamiento:
• Proveedores de modelos
• Proveedores de datos
|
|
A partir de la versión 8.5.0 de ThingWorx Platform, DataStax Enterprise deja de estar en venta y no se soportará en una versión futura. Para obtener más información, consulte el artículo
End of Sale.
|
H2
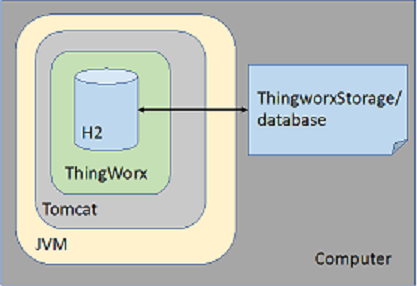
H2 es una base de datos relacional de código abierto con poca huella en disco. Se escribe en Java, que se puede integrar en aplicaciones Java o ejecutar en el modo cliente-servidor, y proporciona una API de JDBC. H2 cumple los requisitos de modelo y de proveedor de datos para ThingWorx. ThingWorx abre una base de datos H2 persistente (en lugar de en la memoria) en modo integrado. Aunque este es el modo de conexión más rápido y sencillo, la base de datos solo se abre en la misma JVM que Tomcat con una aplicación web de ThingWorx que utiliza JDBC (los procesos externos no pueden conectar o utilizar esta instancia de base de datos). Como base de datos persistente, los datos se escriben en el disco local (en la carpeta database de ThingworxStorage) y se conservan después del reinicio de ThingWorx.
Casos de uso típicos
• Pruebas, sistemas de desarrolladores, prueba de conceptos, dispositivos Edge cercanos
• Estrictamente para implementaciones de servidor único
Limitaciones
No se recomienda utilizar H2 para producción debido a su naturaleza integrada:
• Escalabilidad limitada porque comparte los recursos (CPU, memoria, disco, etc.) con la aplicación.
• Pone en riesgo la estabilidad de la aplicación en su totalidad. Por ejemplo, si Tomcat se bloquea o el proceso de Tomcat finaliza, también finalizan los procesos de la base de datos, lo que puede hacer que los datos resulten dañados.
• Es más difícil solucionar problemas de rendimiento aislando los cuellos de botella en el código de la aplicación o la base de datos.
• Desde una perspectiva general de operaciones y administración, la visualización de los datos, las copias de seguridad y la recuperación ante desastres pueden ser más difíciles de mantener.
Para obtener información sobre el uso de H2 como proveedor de persistencia para ThingWorx, consulte
Utilización de H2 como proveedor de persistencia.
PostgreSQL
PostgreSQL es un sistema de gestión de bases de datos relacionales de objetos de código abierto (ORDBMS) con énfasis en la extensibilidad y el cumplimiento de las normas. Como servidor de bases de datos, su función principal es almacenar datos de forma segura y recuperarlos a petición de otras aplicaciones de software. Puede gestionar cargas de trabajo que van desde pequeñas aplicaciones de un solo ordenador hasta grandes aplicaciones orientadas a Internet con muchos usuarios simultáneos. PostgreSQL proporciona una capacidad de alta disponibilidad en el nivel de la base de datos. Se puede configurar con un nodo maestro y varios nodos secundarios en las mismas zonas de disponibilidad o en distintas.
Para obtener más información sobre las implementaciones de ThingWorx y PostgreSQL, consulte los siguientes documentos:
Consulte
https://www.postgresql.org/ para obtener más información sobre PostgreSQL.
Casos de uso típicos
La base de datos escala para implementaciones pequeñas, medianas y grandes de hasta 15.000 escrituras de propiedad por segundo (wps) y proporciona funcionalidad de alta disponibilidad.
Microsoft SQL Server (MSSQL)
Microsoft SQL Server (MSSQL) es un sistema de gestión de bases de datos relacionales desarrollado por Microsoft. Como servidor de base de datos, es un producto de software con la función principal de almacenar y recuperar datos según las solicitudes de otras aplicaciones de software, que pueden ejecutarse en el mismo ordenador o en otro, a través de una red (incluida Internet). Para obtener más información sobre las implementaciones de ThingWorx y Microsoft SQL Server, consulte
Uso de Microsoft SQL Server como proveedor de persistencia .
Se puede elegir entre varias ediciones de SQL Server para adecuarse mejor a la solución de datos. Estas ediciones tienen un tamaño máximo de base de datos relacional que varía desde un volumen pequeño de 10 GB hasta uno muy grande de 524 millones de GB. Para conseguir una alta disponibilidad, se recomienda utilizar la edición Enterprise.
MSSQL, a través de su proveedor de persistencia, soporta tanto los proveedores de modelos como los de datos.
Consulte
https://www.microsoft.com/es-es/sql-server/sql-server-2016 para obtener más información sobre Microsoft SQL Server.
Casos de uso típicos
SQL Server funciona para implementaciones de IoT pequeñas y grandes. Sin embargo, se utiliza con más eficacia cuando Microsoft SQL/Azure ya se encuentra en la pila de TI y el personal está familiarizado con la implementación de la solución de alta disponibilidad de MSSQL Server, según
Escenarios de SQL Server 2017 que utilizan las características de disponibilidad.
Azure SQL Database
Azure SQL Database es una base de datos como servicio (DBaaS) relacional alojada en la nube de Azure y es un motor de base de datos de plataforma como servicio (PaaS) completamente gestionado. El motor de Azure SQL Database se basa en la versión Enterprise Edition de SQL Server. La plataforma de Azure gestiona completamente todas las instancias de SQL Azure Database y garantiza que no haya pérdida de datos y ofrece un alto porcentaje de disponibilidad. Azure SQL Database incluye alta disponibilidad integrada, recuperación ante desastres y actualización de la base de datos.
Consulte
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-paas para obtener más información sobre Azure SQL Database y sus características. Para obtener información sobre la utilización de Azure SQL Database como proveedor de persistencia de ThingWorx, consulte
Utilización de Azure SQL Server como proveedor de persistencia.
DataStax Enterprise (DSE)
A partir de la versión 8.5.0 de ThingWorx Platform, DataStax Enterprise deja de estar en venta y no se soportará en una versión futura. Para obtener más información, consulte el artículo
End of Sale. |
En ThingWorx, también se utiliza un proveedor de almacenes de datos en tiempo de ejecución de gran volumen, DataStax Enterprise (DSE) con tecnología de Apache Cassandra. DSE permite introducir datos a una velocidad superior a la que generan sus recursos y permite escalar a la perfección cuando se añaden dispositivos adicionales (o cualquier otra carga de trabajo). El uso de DSE como almacén de datos en tiempo de ejecución proporciona una plataforma de bases de datos creada para las demandas de rendimiento y disponibilidad de las aplicaciones de IoT, Web y móviles.
La mayoría de las bases de datos relacionales no pueden escalarse horizontalmente y funcionan en modo maestro/secundario. Por el contrario, la arquitectura de agrupación entre pares sin maestro de Cassandra permite escalar de forma lineal y masiva.
DSE ofrece una implementación de Cassandra completamente probada y validada, con herramientas avanzadas de administración y supervisión, integración incorporada con Solr para indexación y búsqueda, y un mecanismo de soporte y parches. Esto coincide directamente con el modelo de almacén de datos conectable que permite a los clientes disponer de varios almacenes de datos para almacenar datos de configuración, modelo y gran volumen. El usuario puede elegir el almacén de datos que cumpla sus requisitos para una función concreta.
DSE es un sistema de bases de datos integrado, siempre activado y de varios modelos, con análisis en tiempo real y por lotes, que utiliza Apache Spark, tecnología en memoria, búsqueda disponible continuamente y cálculo de bases de datos de gráficos. Ofrece herramientas avanzadas para operaciones de sistemas de producción y desarrollo, funciones flexibles, tales como el almacenamiento por niveles a fin de acceder a datos a corto y largo plazo, servicio multicliente para ejecutar varias agrupaciones de bases de datos dentro del mismo sistema y seguridad avanzada para cumplir los requisitos empresariales.
Para que ThingWorx funcione, se necesita el componente de búsqueda integrado de DSE (Apache Solr) de la pila de DSE. Como consecuencia, ThingWorx no funciona con instalaciones de Apache Cassandra de código abierto que no tienen Apache Solr integrado. |
DSE proporciona las siguientes ventajas para las instancias de ThingWorx Platform que requieren un almacén de datos para volúmenes y datos de velocidad superiores a los que están disponibles actualmente con H2 o PostgreSQL:
• Proporciona una mayor velocidad de ingesta de datos.
• Soporta más de un almacén de datos para datos en tiempo de ejecución (permite conservar datos de modelo en H2 o PostgreSQL y utilizar DSE para datos de flujos de gran volumen).
• Soporta propiedades de escalado elásticas. Se pueden añadir más nodos a un anillo de DSE para velocidades de transacción superiores.
• Permite separar los procesos de datos de los procesos de plataforma.
• Soporta arquitectura compatible con la nube.
Para obtener más información, consulte
Getting Started with DataStax Enterprise and ThingWorx y
DataStax Enterprise (DSE).
Caso de uso típico
Un caso de uso típico ocurre cuando hay grandes cantidades (por encima de 15.000 wps) de datos transaccionales (tiempo de ejecución) en una carga distribuida.
InfluxDB
Para utilizar InfluxDB se debe disponer de ThingWorx 8.4 o una versión posterior. Si el sistema trata de manera intensiva datos de serie temporal y la implementación depende en gran medida de flujos de valor o flujos de persistencia o recuperación de datos, se recomienda utilizar InfluxDB como proveedor de persistencia en ThingWorx. InfluxDB es un almacén de datos de alto rendimiento escrito específicamente para datos de serie temporal. Permite la ingesta, compresión y consulta en tiempo real de alto rendimiento de dichos datos. InfluxDB se utiliza como almacén de datos para cualquier caso de uso que implique una gran cantidad de datos con marca de tiempo, como la supervisión de DevOps, los datos de registro, las métricas de aplicación, los datos de sensor de IoT y los análisis en tiempo real. También proporciona otras funciones, como las directivas de conservación de datos (RP), etc. La empresa InfluxDB ofrece una solución de agrupación de alta disponibilidad y escalabilidad que satisface las necesidades de datos de serie temporal.
InfluxPersistenceProviderPackage está disponible en ThingWorx para utilizarse con proveedores de persistencia como parte de la instalación por defecto para PostgreSQL o MSSQL.
• El proveedor de datos InfluxDB actualmente solo soporta flujos de valor y flujos. El soporte de tablas de datos, wikis y blogs no está disponible.
• El proveedor de datos InfluxDB no soporta actualmente la funcionalidad de exportación.
• InfluxDB no se soporta actualmente como proveedor de propiedades.
Si se utiliza una instancia de proveedor de persistencia (creada mediante el paquete de proveedor de persistencia de InfluxDB) como proveedor de persistencia por defecto, se pueden editar las opciones de configuración de cola de flujo y flujo de valor, que se aplicarán a todos los flujos y flujos de valor. No se puede cambiar esta configuración para un flujo o un flujo de valor específico.
Para obtener información acerca de la utilización de InfluxDB como proveedor de persistencia, consulte
Utilización de InfluxDB como proveedor de persistencia.