Utilización de InfluxDB como proveedor de persistencia
Resumen
Si el sistema trata de manera intensiva datos de serie temporal y la implementación depende en gran medida de flujos de valor o flujos de persistencia o recuperación de datos, se recomienda utilizar InfluxDB como
proveedor de persistencia en ThingWorx. InfluxDB es un almacén de datos de alto rendimiento escrito específicamente para datos de serie temporal. Permite la ingesta, compresión y consulta en tiempo real de alto rendimiento de dichos datos. InfluxDB se utiliza como almacén de datos para cualquier caso de uso que implique una gran cantidad de datos con marca de tiempo, como la supervisión de DevOps, los datos de registro, las métricas de aplicación, los datos de sensor de IoT y los análisis en tiempo real. También proporciona otras funciones, incluidas las directivas de retención de datos (RP), etc. InfluxDB Enterprise ofrece una solución de almacenamiento en clúster de alta disponibilidad y altamente escalable para las necesidades de datos cronológicos.
|
|
Para utilizar InfluxDB, se necesita ThingWorx 8.4.0 o una versión posterior.
|
InfluxPersistenceProviderPackage está disponible como parte de la instalación por defecto para PostgreSQL o MSSQL.
|
|
El proveedor de datos InfluxDB actualmente solo soporta flujos de valor y flujos. El soporte de tablas de datos, wikis y blogs no está disponible.
|
|
|
El proveedor de datos InfluxDB no soporta actualmente la funcionalidad de exportación.
|
|
|
InfluxDB no se soporta como proveedor de propiedades.
|
|
|
Actualmente, el proveedor de datos InfluxDB solo soporta una directiva de conservación con el nombre "autogen". Durante la creación de la base de datos que se va a utilizar con el proveedor de datos, se puede especificar el nombre de la directiva y otras directivas, por ejemplo, el factor de replicación, etc.
|
Panorama de inicio de InfluxDB Enterprise y ThingWorx
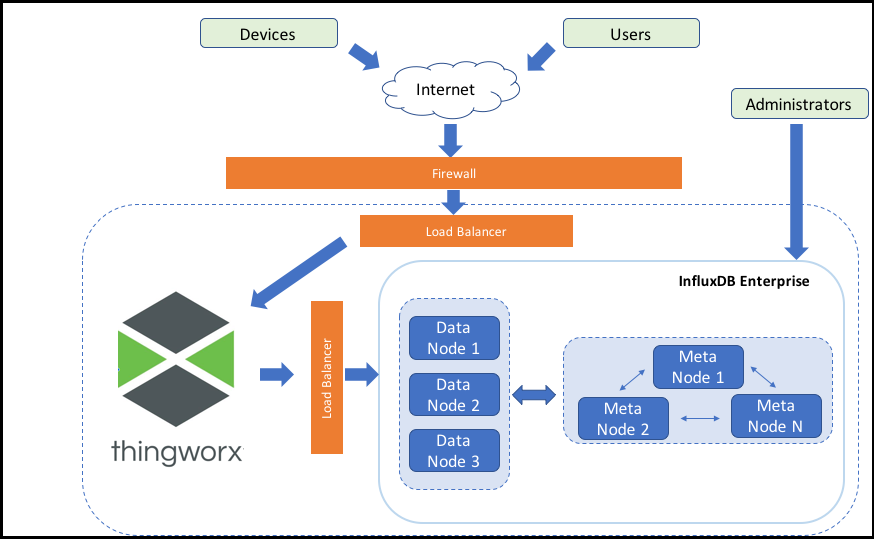
En el diagrama anterior se incluye InfluxDB Enterprise. Para InfluxDB de código abierto, el diagrama de arquitectura es el mismo, excepto que solo funciona con un nodo. |
En esta documentación se utilizan los siguientes términos cuando se hace referencia a la configuración de InfluxDB Enterprise:
• Equilibrador de carga: InfluxDB Enterprise no funciona como equilibrador de carga. Un administrador debe configurarlo.
• Clúster: un clúster de InfluxDB Enterprise consta de dos tipos de nodos; nodos de metadatos y de datos.
• Nodos de datos: en ellos residen todos los datos de serie temporal sin procesar. Para un entorno de alta disponibilidad, es necesario un factor de replicación de al menos dos.
• Nodos de metadatos: estos nodos tienen un trabajo simple, que es mantener la coherencia del estado. Contienen solo la información básica sobre el estado, como las directivas de retención, los usuarios y las bases de datos. En un entorno de alta disponibilidad, se necesitan al menos tres nodos de metadatos.
Para obtener más información acerca de la alta disponibilidad, consulte
https://www.influxdata.com/blog/understanding-influxenterprise-what-is-a-cluster/.
Ventajas de la utilización de InfluxDB Enterprise
Si se busca un almacén de datos para volúmenes y datos de velocidad superiores a los que están disponibles actualmente con otras bases de datos, InfluxDB Enterprise presenta las siguientes ventajas:
• Mayor velocidad de introducción de datos
• Puede haber más de un almacén de datos para los datos de tiempo de ejecución. Por ejemplo, se pueden mantener datos relacionales en PostgreSQL, a la vez que se utiliza InfluxDB para datos de flujo y flujo de valor de gran volumen. Al definir un flujo o un flujo de valor, ThingWorx utiliza el proveedor de almacén de datos de tiempo de ejecución por defecto, pero se puede configurar para utilizar cualquier proveedor de persistencia definido.
Aún se pueden exportar datos de otros proveedores e importarlos en InfluxDB. ThingWorx gestiona la abstracción de datos. |
• Arquitectura apta para la nube (escala horizontal, solo con InfluxDB Enterprise)
Instalación y configuración de InfluxDB
Es responsabilidad de quien instale la base de datos de Influx leer y comprender toda la documentación relacionada con la seguridad que se proporciona para InfluxDB. PTC recomienda encarecidamente instalar y configurar InfluxDB con configuraciones seguras que incluyan el uso del nombre de usuario y una contraseña segura. |
Para este proceso se supone que está instalado ThingWorx. Consulte
Instalación de ThingWorx. |
1. Descargue e instale InfluxDB.
InfluxDB no se soporta en Windows. En los siguientes pasos se utiliza el sistema operativo UNIX. |
◦ InfluxDB Open Source (nodo único): consulte
https://docs.influxdata.com/influxdb/v1.7/introduction/installation/
Vínculos de descarga:
◦ InfluxDB Enterprise (alta disponibilidad): consulte
https://docs.influxdata.com/enterprise_influxdb/v1.7/install-and-deploy/production_installation/
Vínculos de descarga, nodo de datos:
Vínculos de descarga, nodo de metadatos:
2. Cree una base de datos dentro de InfluxDB. Obtenga y ejecute el script thingworxInfluxDBSetup.sh para crear la base de datos en InfluxDB.
El script thingworxInfluxDBSetup.sh está disponible en Portal de soporte de PTC, en la carpeta install del paquete del software descargado. |
En el siguiente comando de ejemplo se crea una base de datos con las directivas de conservación por defecto:
CREATE DATABASE thingworx with DURATION 365d REPLICATION 1 SHARD DURATION 30d NAME autogen
.
3. Cree un usuario de InfluxDB. En el siguiente comando de ejemplo se crea un usuario:
CREATE USER twadmin WITH PASSWORD 'password' WITH ALL PRIVILEGES
.
4. En ThingWorx Composer, cree un nuevo proveedor de persistencia.

5. En el campo Paquete de proveedor de persistencia, seleccione InfluxPersistenceProviderPackage.
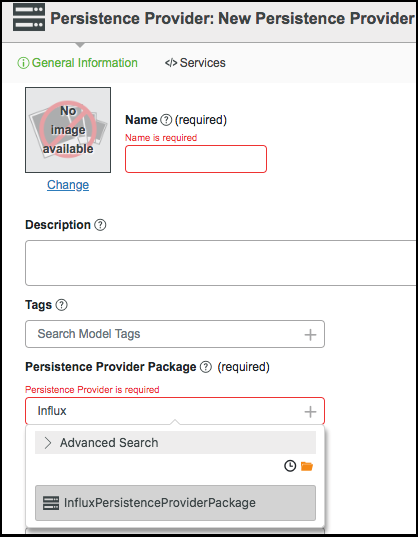
6. Pulse en Guardar.
7. Pulse en la ficha Configuración, configure la información de conexión, según sea necesario, y pulse en Guardar. Consulte las opciones de configuración en las siguientes tablas.
Si se utiliza una instancia de proveedor de persistencia (creada con el paquete de proveedor de persistencia de InfluxDB) como
proveedor de persistencia por defecto, se pueden editar las siguientes opciones de configuración de cola de flujo y flujo de valor. Estas ediciones se aplicarán a todos los flujos y flujos de valor. No se puede cambiar esta configuración para un flujo o un flujo de valor específico.
Al cambiar el proveedor de persistencia de un flujo de valor (por ejemplo, de ThingworxPersistenceProvider a InfluxPersistenceProviderPackage), cualquier cosa que implemente un flujo de valor debe llamar al servicio RestartThing para recuperar las entradas escritas en el nuevo proveedor de persistencia. Si las cosas no se reinician, las entradas se pueden escribir en la base de datos, pero no se recuperan hasta que se reinicia la cosa. |

Nombre | Descripción | Valor por defecto |
|---|---|---|
URL de conexión | URL de la base de datos de la que se deben adquirir las conexiones. | http://localhost:8086 |
Esquema de base de datos | Esquema para conectarse. | thingworx |
Nombre de usuario | Nombre de usuario para adquirir una conexión de base de datos. | thingworx |
Contraseña | Contraseña para adquirir una conexión de base de datos. | n/d |
Nombre | Descripción | Tipo base | Valor por defecto | ||
|---|---|---|---|---|---|
Tamaño máximo de cola | Número máximo de entradas de flujo para la cola. Cuando se alcanza el valor especificado, se rechazan las entradas posteriores. | Número | 250000 | ||
Tiempo de espera máximo para vaciar el búfer de flujo (milisegundos) | Número de milisegundos que el sistema espera antes de vaciar el búfer de flujo. | Número | 2000 | ||
Número de subprocesos de procesamiento | Número de subprocesos de procesamiento dedicados al flujo.
| Número | 5 | ||
Número máximo de elementos para vaciar el búfer de flujo | Número máximo de elementos que se pueden acumular antes de vaciar el búfer de flujo. | Número | 1000 | ||
Número máximo de escrituras de flujo por bloque de proceso | Número máximo de escrituras de flujo para procesar en un bloque. | Número | 2500 | ||
Velocidad de lectura de estado de búfer (milisegundos) | El estado de búfer se verifica con el valor de velocidad especificado en milisegundos. | Número | 5 |
Nombre | Descripción | Tipo base | Valor por defecto | ||
|---|---|---|---|---|---|
Tamaño máximo de cola | Número máximo de entradas de flujo de valor para la cola. Cuando se alcanza el valor especificado, se rechazan las entradas siguientes. | Número | 250000 | ||
Tiempo de espera máximo para vaciar el búfer de flujo de valores (milisegundos) | Número de milisegundos que el sistema espera antes de vaciar el búfer de flujo de valor. | Número | 2000 | ||
Número de subprocesos de procesamiento | Número de subprocesos de procesamiento asignados al flujo de valor.
| Número | 5 | ||
Número máximo de elementos para vaciar el búfer de valores | Número máximo de elementos que se pueden acumular antes de vaciar el búfer de flujo de valor. | Número | 500 | ||
Número máximo de escrituras de flujo de valores por bloque de proceso | Número máximo de elementos para procesar en un bloque. | Número | 2500 | ||
Velocidad de lectura de estado de búfer (milisegundos) | El estado de búfer se verifica con el valor de velocidad especificado en milisegundos. | Número | 5 |
8. Pulse en la ficha Información general y seleccione la casilla Activo.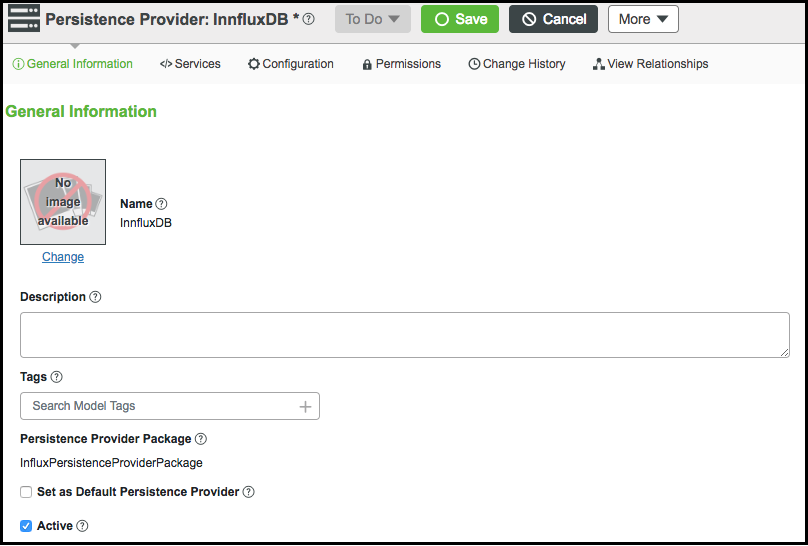
9. Pulse en Guardar.
Prácticas recomendadas
Límite de la serie
La serie es el número total de combinaciones únicas de cosas y flujos de valor asociados conectados a InfluxDB. InfluxDB tiene un buen rendimiento con un gran volumen de datos dirigido a una pequeña cantidad de cosas y propiedades de cosa, como 10.000 o 100.000. Por defecto, en InfluxDB el número total de la serie se limita a un millón. Se puede aumentar el límite, pero el rendimiento de InfluxDB se reduce a medida que el número de la serie supera este límite.
Si hay una gran cantidad de cosas y propiedades, se pueden elegir las que tienen un mayor volumen de datos y señalar solo a estas en InfluxDB para aliviar la presión de PostgreSQL o MSSQL.
Como alternativa, si desea dividir la serie en varios servidores, se pueden tener varias instancias de proveedor de datos de InfluxDB señalando a otras instancias de servidor InfluxDB.
Límite de escritura
Hay 100.000 escrituras por segundo con una máquina virtual con memoria de 60 GB y 32 núcleos. Más allá de este límite, se pueden producir problemas en ThingWorx y se pueden agotar los recursos para controlar cualquier solicitud o trabajo, como escribir en la base de datos. En ese punto, ThingWorx se detiene, mientras InfluxDB sigue escribiendo en la base de datos. No se trata de un problema con PostgreSQL porque PostgreSQL se convierte en un cuello de botella y ThingWorx nunca llega al punto de quedarse sin recursos para controlar las tareas interiores.
Conexión SSL/segura
InfluxDB soporta las conexiones SSL y HTTPS. Se pueden activar las conexiones SSL y HTTPS para aumentar la seguridad si no se soporta la red entre ThingWorx e InfluxDB. Un certificado autofirmado es adecuado si la clave privada de firma se mantiene segura.
Limitaciones conocidas de InfluxDB en tipos base de propiedades
No se puede cambiar el tipo base de una propiedad después de haberla registrado en un flujo de valor. Para obtener más información, consulte
https://github.com/influxdata/influxdb/issues/3460.
Depuración de propiedades
Los servicios PurgeAllPropertyHistory, PurgeSelectedPropertyHistory y PurgePropertyHistory se pueden utilizar para depurar las propiedades de InfluxDB. Los parámetros startDate y endDate se utilizan para especificar un rango.