Utilizzo di InfluxDB come provider di persistenza
Panoramica
Se il sistema si occupa in modo intensivo di dati di serie temporali e l'implementazione dipende in larga misura da stream di valori o stream per la persistenza o il recupero di dati, consigliamo di utilizzare InfluxDB come
provider di persistenza in ThingWorx. InfluxDB è un archivio dati ad alte prestazioni scritto in modo specifico per i dati di serie temporali. Consente l'inserimento, la compressione e l'interrogazione in tempo reale di throughput elevati degli stessi dati. InfluxDB viene utilizzato come archivio dati per qualsiasi caso d'uso che coinvolga grandi quantità di dati con timestamp, tra cui monitoraggio DevOps, dati di log, criteri di misurazione di applicazione, dati del sensore IoT e analisi in tempo reale. Fornisce inoltre altre caratteristiche tra cui criteri di conservazione dei dati e così via. InfluxDB Enterprise offre disponibilità elevata e una soluzione di clustering altamente scalabile per le esigenze di dati di serie temporali.
|
|
Per utilizzare InfluxDB, è richiesto ThingWorx 8.4.0 e versioni successive.
|
InfluxPersistenceProviderPackage è disponibile nell'ambito dell'installazione di default per PostgreSQL o MSSQL.
|
|
Il provider di dati InfluxDB attualmente supporta solo stream di valori e stream. Il supporto per tabelle dati, wiki e blog non è disponibile.
|
|
|
Il provider di dati InfluxDB attualmente non supporta la funzionalità di esportazione.
|
|
|
InfluxDB non è supportato come provider di proprietà.
|
|
|
Attualmente il provider di dati InfluxDB supporta un criterio di conservazione solo con il nome "autogen". Durante la creazione del database da utilizzare con il provider di dati è possibile specificare il nome del criterio e altri criteri, come il fattore di replica e così via.
|
Ambiente di avvio di InfluxDB Enterprise e ThingWorx

Il diagramma sopra riportato include InfluxDB Enterprise. Per InfluxDB open source, il diagramma dell'architettura sarebbe lo stesso, tranne per il fatto che funziona con un solo nodo. |
Di seguito vengono spiegati i termini utilizzati in questa documentazione in riferimento alla configurazione di InfluxDB Enterprise.
• Bilanciamento del carico: InfluxDB Enterprise non funziona come bilanciamento del carico. Un amministratore deve configurarlo.
• Cluster: un cluster InfluxDB Enterprise comprende due tipi di nodi: metanodi e nodi di dati.
• Nodi di dati: sono inclusi tutti i dati delle serie temporali non elaborate. Per la disponibilità elevata, è necessario un fattore di replica pari almeno a due.
• Metanodi: questi nodi hanno un compito semplice, ovvero mantenere lo stato coerente. Includono solo informazioni di base che riguardano lo stato, come criteri di conservazione, utenti e database. In un ambiente ad alta disponibilità sono necessari almeno tre metanodi.
Maggiori informazioni sulla disponibilità elevata sono disponibili all'indirizzo
https://www.influxdata.com/blog/understanding-influxenterprise-what-is-a-cluster/.
Vantaggi dell'utilizzo di InfluxDB Enterprise
InfluxDB Enterprise può apportare i vantaggi elencati di seguito in termini di possibilità di archiviare dati di volumi e velocità maggiori rispetto a quelli attualmente disponibili con altri database.
• Maggiore velocità di inserimento dei dati
• Per i dati della fase di esecuzione è possibile utilizzare più repository di dati. Ad esempio è possibile mantenere i dati relazionali in PostgreSQL, mentre si utilizza InfluxDB per i dati di stream di valori e stream dai volumi elevati. Quando si definisce uno stream o uno stream di valori, ThingWorx utilizza il provider dell'archivio dei dati della fase di esecuzione di default, ma può essere configurato per utilizzare qualsiasi provider di persistenza definito.
È ancora possibile esportare dati da altri provider di dati e importarli in InfluxDB. ThingWorx gestisce l'astrazione dei dati. |
• Architettura cloud-friendly (scala orizzontale, solo con InfluxDB Enterprise)
Installazione e configurazione di InfluxDB
È responsabilità di chiunque installi il database Influx leggere e comprendere tutta la documentazione relativa alla sicurezza fornita per InfluxDB. PTC consiglia vivamente di installare e configurare InfluxDB utilizzando configurazioni sicure, tra cui un nome utente e una password complessa. |
Questa procedura presuppone che ThingWorx sia installato. Vedere
Installare ThingWorx. |
1. Scaricare e installare InfluxDB.
InfluxDB non è supportato in Windows. I passi descritti di seguito utilizzano il sistema operativo UNIX. |
◦ InfluxDB Open Source (nodo singolo): fare riferimento a
https://docs.influxdata.com/influxdb/v1.7/introduction/installation/
Link per il download:
◦ InfluxDB Enterprise (disponibilità elevata): fare riferimento a
https://docs.influxdata.com/enterprise_influxdb/v1.7/install-and-deploy/production_installation/
Link per il download - Nodo di dati:
Link per il download - Metanodo:
2. Creare un database all'interno di InfluxDB. Ottenere ed eseguire lo script thingworxInfluxDBSetup.sh per creare il database in InfluxDB.
Lo script thingworxInfluxDBSetup.sh è disponibile nel portale di supporto PTC, nella cartella install del pacchetto di download del software. |
Il seguente comando di esempio crea un database con i criteri di conservazione di default:
CREATE DATABASE thingworx with DURATION 365d REPLICATION 1 SHARD DURATION 30d NAME autogen
3. Creare un utente InfluxDB. Il seguente comando di esempio crea un utente:
CREATE USER twadmin WITH PASSWORD 'password' WITH ALL PRIVILEGES
4. In ThingWorx Composer creare un nuovo provider di persistenza.

5. Nel campo Package provider di persistenza selezionare InfluxPersistenceProviderPackage.
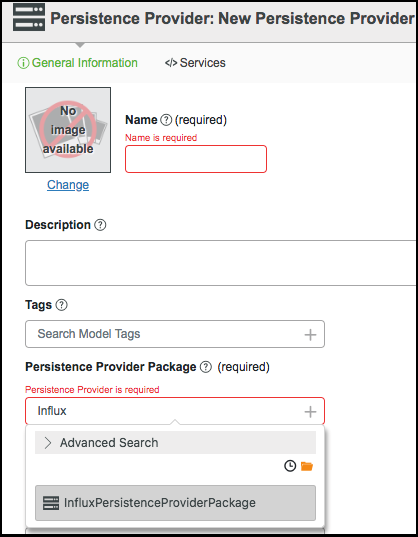
6. Fare clic su Salva.
7. Fare clic sulla scheda Configurazione, configurare le informazioni di connessione in base alle esigenze, quindi salvare. Fare riferimento alle opzioni di configurazione nelle tabelle riportate di seguito.
Se si utilizza un'istanza del provider di persistenza (creata utilizzando il package del provider di persistenza InfluxDB) come
provider di persistenza di default, è possibile modificare le impostazioni di configurazione delle code di stream e stream di valori riportate di seguito, che verranno applicate a tutti gli stream e stream di valori. Non è possibile modificare queste impostazioni per uno stream o uno stream di valori specifico.
Quando si cambia il provider di persistenza di uno stream di valori (ad esempio si passa da ThingworxPersistenceProvider a InfluxPersistenceProviderPackage), qualsiasi oggetto che implementi uno stream di valori deve chiamare il servizio RestartThing per recuperare le voci scritte nel nuovo provider di persistenza. Se gli oggetti non vengono riavviati, le voci potrebbero essere scritte nel database, ma non vengono recuperate fino al riavvio dell'oggetto. |

Nome | Descrizione | Valore di default |
|---|---|---|
URL connessione | L'URL del database da cui le connessioni devono essere acquisite. | http://localhost:8086 |
Schema database | Schema per connettersi. | thingworx |
Nome utente | Nome utente utilizzato per acquisire una connessione di database. | thingworx |
Password | Password utilizzata per acquisire una connessione di database. | n/d |
Nome | Descrizione | Tipo di base | Valore di default | ||
|---|---|---|---|---|---|
Dimensione max coda | Numero massimo di voci dello stream da mettere in coda. Una volta raggiunto il valore specificato, le voci successive vengono rifiutate. | Number | 250000 | ||
Tempo max di attesa prima di scaricare il buffer dello stream (millisec) | Numero di millisecondi che il sistema attende prima di scaricare il buffer dello stream. | Number | 2000 | ||
Numero di thread di elaborazione | Numero dei thread di elaborazione dedicati allo stream.
| Number | 5 | ||
Numero max di elementi prima di scaricare il buffer dello stream | Numero massimo di elementi da accumulare prima di scaricare il buffer dello stream. | Number | 1000 | ||
Numero max di scritture dello stream da elaborare in blocco | Numero massimo di scritture dello stream da elaborare in un unico blocco. | Number | 2500 | ||
Frequenza analisi stato buffer (millisec). | Lo stato del buffer viene controllato in base al valore della frequenza specificata in millisecondi. | Number | 5 |
Nome | Descrizione | Tipo di base | Valore di default | ||
|---|---|---|---|---|---|
Dimensione max coda | Numero massimo di voci dello stream di valori da mettere in coda. Una volta raggiunto il valore specificato, le voci seguenti vengono rifiutate. | Number | 250000 | ||
Tempo max di attesa prima di scaricare il buffer dello stream di valori (millisec) | Numero di millisecondi che il sistema attende prima di scaricare il buffer dello stream di valori. | Number | 2000 | ||
Numero di thread di elaborazione | Numero di thread di elaborazione allocati allo stream di valori.
| Number | 5 | ||
Numero max di elementi prima di scaricare il buffer di valori | Numero massimo di elementi da accumulare prima di scaricare il buffer dello stream di valori. | Number | 500 | ||
Numero max di scritture dello stream di valori da elaborare in blocco | Numero massimo di elementi da elaborare in un unico blocco. | Number | 2500 | ||
Frequenza analisi stato buffer (millisec) | Lo stato del buffer viene controllato in base al valore della frequenza specificata in millisecondi. | Number | 5 |
8. Fare clic sulla scheda Informazioni generali e selezionare la casella di controllo Attivo.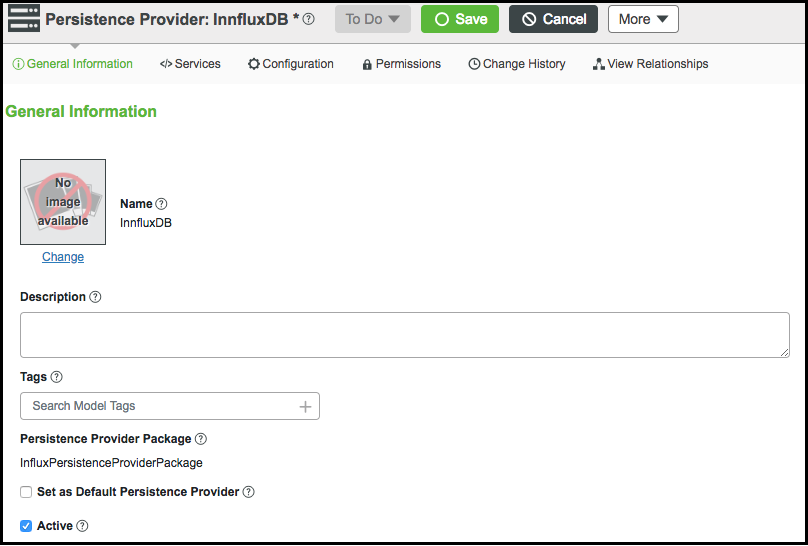
9. Fare clic su Salva.
Best practice
Limite di serie
La serie è il numero totale di combinazioni univoche di oggetti e stream di valori associati che sono registrati in InfluxDB. InfluxDB funziona bene con un volume di dati elevato diretto a una piccola quantità di oggetti e proprietà di oggetti, ad esempio 10K o 100K. Per default, in InfluxDB il numero di serie totale è limitato a 1 milione. Questo limite può essere aumentato ma, quando il numero di serie lo supera, si ha una riduzione delle prestazioni di InfluxDB.
Se si dispone di molti oggetti e proprietà, è possibile scegliere quelli con il volume di dati più elevato e puntare solo questi a InfluxDB per evitare il sovraccarico in PostgreSQL o MSSQL.
In alternativa, se si desidera dividere la serie su più server, è possibile avere più istanze del provider di dati InfluxDB che puntano a diverse istanze del server InfluxDB.
Limite di scrittura
100K scritture al secondo con una memoria VM da 60 GB con 32 core. Andare oltre questo limite può causare problemi in ThingWorx e può esaurire le risorse necessarie per gestire qualsiasi richiesta o operazione, come scrivere sul database. A quel punto, ThingWorx si blocca mentre InfluxDB continua a scrivere sul database. Questo problema non viene riscontrato con PostgreSQL perché PostgreSQL diventa il collo di bottiglia e ThingWorx non riesce mai ad arrivare al punto di esaurire le risorse necessarie per gestire i task internamente.
SSL/Connessione protetta
InfluxDB supporta connessioni SSL e HTTPS. È possibile attivare queste connessioni per aumentare la protezione, se la rete tra ThingWorx e InfluxDB non è supportata. Un certificato autofirmato è adeguato, se la chiave privata di accesso è conservata in modo sicuro.
Limitazioni note di InfluxDB sui tipi di base delle proprietà
Non è possibile modificare il tipo di base di una proprietà dopo che è stato registrato in uno stream di valori. Per ulteriori informazioni, vedere
https://github.com/influxdata/influxdb/issues/3460.
Eliminazione delle proprietà
Per eliminare le proprietà da InfluxDB, è possibile utilizzare i servizi PurgeAllPropertyHistory, PurgeSelectedPropertyHistory e PurgePropertyHistory. Utilizzare i parametri startDate ed endDate per specificare un intervallo.