テキスト分析
「テキスト分析」操作は、生のテキストに対して高度な自然言語処理を行うときに使用し、次の分析タイプを含みます。
• 言語検出
• 感情分析
• キーフレーズ抽出
• エンティティ認識
詳細については、Azure Text Analytics を参照してください。
ワークフローで「テキスト分析」操作を使用するには、次の手順を完了します。
1. 「Azure」の下の「テキスト分析」操作をキャンバスにドラッグし、この操作にマウスポインタを合わせて  をクリックするか、この操作をダブルクリックします。「テキスト分析」ウィンドウが開きます。
をクリックするか、この操作をダブルクリックします。「テキスト分析」ウィンドウが開きます。
をクリックするか、この操作をダブルクリックします。「テキスト分析」ウィンドウが開きます。2. 必要に応じて、「ラベル」を編集します。デフォルトでは、ラベル名は操作名と同じです。
3. Azure コネクタタイプを追加するには、サポートされている Azure コネクタタイプを参照してください。
以前にコネクタタイプを追加した場合は、該当する「コネクタタイプ」を選択し、「コネクタ名」でコネクタを選択します。
4. 「テスト」をクリックしてこのコネクタを検証します。
5. 「マップコネクタ」をクリックして、入力フィールドの設定に使用しているコネクタとは異なるコネクタを使用して操作を実行します。「ランタイムコネクタ」フィールドで、有効な Azure コネクタ名を指定します。「マップコネクタ」の詳細については、マップコネクタの使用を参照してください。
「コネクタタイプ」で「なし」を選択した場合、「マップコネクタ」オプションは使用できません。
6. 「リソースグループ」リストで、Azure サブスクリプションで定義されている適切なリソースグループを選択します。
7. 「音声サービスアカウント」リストで、リソースグループで定義されている音声アカウントを選択します。
8. 「特定のサービスを選択」リストで、次のいずれかのオプションを選択します。
◦ 「言語を検出」 - 0 から 1 の間の数値スコアで、入力テキストの言語を検出します。スコアが 1 に近いほど、識別された言語は正確です。
◦ 「認識されたエンティティを取得」 - 組織、人、場所など、テキスト内の名前付きのすべてのエンティティを検出します。
◦ 「キーフレーズを取得」 - 入力テキスト内のキーフレーズを検出します。
◦ 「感情分析」 - 0 から 1 までの間の数値スコアで、テキストの感情を検出します。スコアが 1 に近いほど肯定的な感情を示し、スコアが 0 に近いほど否定的な感情を示します。
9. 「ドキュメント」セクションで、「追加」をクリックし、次の操作を行います。
◦ 「テキスト」フィールドに、分析するテキストを入力します。
◦ 「言語」リストで、入力テキストの言語を選択します。
「言語を検出」サービスの「言語」フィールドは指定しません。
複数の入力テキストを追加するには、「追加」をクリックします。追加した入力テキストを削除するには、 をクリックします。
をクリックします。
をクリックします。10. 「完了」をクリックします。
出力スキーマ
各「テキスト分析」サービスに独自の出力スキーマがあります。
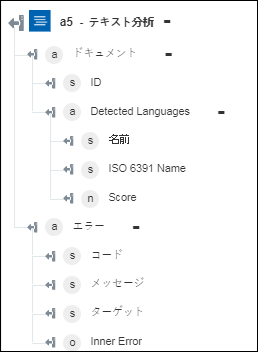
◦ 「言語を検出」 - 検出された言語とその信頼スコアを含む配列を返します。
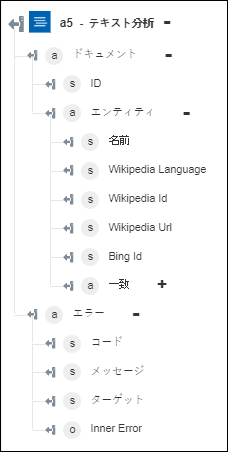
◦ 「認識されたエンティティを取得」 - 検出されたエンティティに関する情報を含む配列を返します。
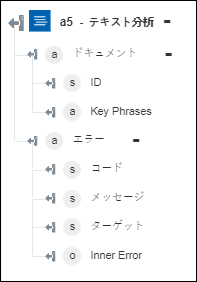
◦ 「キーフレーズを取得」 - ドキュメント内で検出されたキーフレーズの配列を返します。
◦ 「感情分析」 - ドキュメントの感情スコアを返します。
