Composants de déploiement de ThingWorx Foundation
Les composants ThingWorx peuvent être envisagés selon trois couches : la couche client, la couche d'application et la couche de données. L'architecture de départ de base de toute solution ThingWorx se présente comme suit :
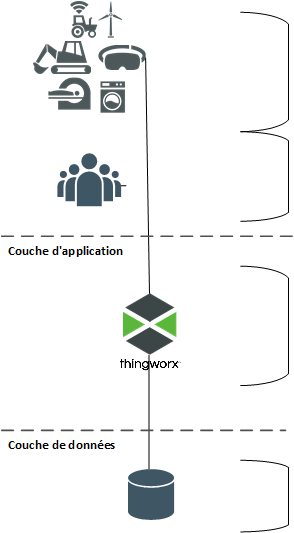 |
Objets/périphériques : cette couche regroupe les objets, les appareils, les agents et autres actifs qui se connectent à ThingWorx Platform, lui envoient des données et reçoivent du contenu de sa part.
Utilisateurs/clients : cette couche regroupe les produits (principalement les navigateurs Web) utilisés pour accéder à ThingWorx Platform.
|
|
Plateforme : la couche plateforme (ou couche application) est celle où réside ThingWorx Foundation, qui constitue la plaque tournante d'un système ThingWorx. Cette couche fournit sa connectivité à la couche client, assure les contrôles d'authentification et d'autorisation, ingère, traite et analyse le contenu, et réagit à des conditions telles que l'envoi d'alertes.
|
|
|
Base de données : la couche base de données stocke les métadonnées du modèle ThingWorx Runtime ainsi que les données système :
• Les métadonnées du modèle incluent les définitions d'entité ThingWorx, les définitions d'objet et leurs définitions de propriété associées.
• Les données d'exécution sont ingérées selon le modèle ThingWorx. Les données peuvent être des données tabulaires ou de séries temporelles que le modèle ThingWorx rend persistantes en tant que lignes de contenu dans les blogs, wikis, flux, flux de valeurs et tables de données.
|
Avec le développement de la solution ThingWorx en fonctionnalités et en complexité, les besoins architecturaux de chaque niveau augmentent.
Les sections suivantes présentent chaque composant d'une solution ThingWorx dans le niveau ou la couche où il opère.
Composants d'utilisateur/de client
L'utilisateur ou le client qui accède à ThingWorx Platform via ThingWorx Composer ou via les applications composites d'exécution doit disposer d'un navigateur moderne prenant en charge HTML/HTML5 (exemples : Microsoft Edge, Firefox, Safari ou Chrome).
Composants d'objet/d'appareil
• ThingWorx Edge Microserver : ThingWorx Edge Microserver (EMS) fonctionne avec des périphériques Edge ou des magasins de données qui doivent se connecter au serveur ThingWorx sur Internet. Il permet aux appareils et magasins de données qui sont derrière des pare-feu de communiquer en toute sécurité avec le serveur ThingWorx et d'être des participants complets dans le paysage de la solution. ThingWorx EMS n'est pas un simple connecteur et permet de déplacer l'intelligence et le prétraitement des données vers l'Edge.
• SDK ThingWorx Edge : Les SDK ThingWorx Edge sont des collections de classes, d'objets, de fonctions, de méthodes et de variables qui fournissent une infrastructure pour la création d'applications qui peuvent envoyer des données en toute sécurité à partir de périphériques Edge vers ThingWorx Platform. Les SDK ThingWorx Edge fournissent des outils pour les développeurs expérimentés dans les langages de programmation C, .NET et Java.
ThingWorx EMS et les SDK ThingWorx Edge prennent en charge les connexions via des proxys. Le processus de gestion de la configuration du proxy et de la gestion des modifications associées varie selon le client et/ou le projet. Les SDK ThingWorx Edge offrent une flexibilité optimale car les bibliothèques de SDK peuvent être incluses ou référencées par n'importe quel composant Edge personnalisé, et peuvent donc être mises à jour en fonction de la conception de la solution.
Composants de plateforme
• ThingWorx Connection Server : ThingWorx Connection Server est une application serveur qui facilite la connexion des appareils distants et gère l'ensemble du routage des messages vers et depuis les appareils. ThingWorx Connection Server fournit une connectivité évolutive via des WebSockets à l'aide du protocole de communication ThingWorx AlwaysOn. PTC recommande l'utilisation de serveurs de connexion lorsqu'il y a plus de 25 000 actifs pour décharger la gestion des connexions du serveur ThingWorx Foundation. Les serveurs de connexion sont requis dans les configurations haute disponibilité afin de distribuer les connexions d'appareils sur les noeuds de cluster actifs. PTC recommande également au moins un serveur de connexion pour toutes les 100 000 connexions simultanées au serveur ThingWorx Foundation. Ce rapport entre le nombre d'appareils et le serveur de connexion peut changer en fonction de nombreux facteurs, tels que les suivants :
◦ Nombre d'appareils
◦ Fréquence des soumissions d'écriture à partir des appareils
• Tomcat : Apache Tomcat est un conteneur de servlet open source développé par Apache Software Foundation (ASF). Tomcat implémente les spécifications Java Servlet et Java Server Pages (JSP) d'Oracle Corporation et fournit un environnement de serveur Web HTTP purement Java pour l'exécution du code Java.
• ThingWorx Foundation Server : ThingWorx Foundation fournit un environnement de conception, d'exécution et de veille complet pour les applications Machine-to-Machine (M2M) et IoT. ThingWorx Foundation est conçu pour créer, exécuter et développer efficacement des applications qui contrôlent et génèrent des rapports sur les données provenant d'actifs distants, tels que les appareils, les machines, les capteurs et l'équipement industriel connectés.
ThingWorx Foundation sert de concentrateur à votre environnement ThingWorx. Il inclut des ensembles d'outils qui vous aident à développer des applications afin de définir le comportement des actifs (ou des appareils) distants déployés dans votre environnement et les relations entre les actifs.
Une fois les actifs modélisés, ils peuvent s'enregistrer et communiquer avec ThingWorx Foundation, ce qui vous permet de surveiller et de gérer les appareils physiques et de collecter des données à partir de ces derniers.
Composants de la base de données
ThingWorx Platform offre un modèle de magasin de données enfichable qui permet à chaque client de choisir la base de données qui répond le mieux à ses exigences, des petites implémentations pour les environnements de démonstration ou de formation, aux bases de données à volume élevé et hautement disponibles qui prennent en charge des milliers de transactions par seconde.
Les flux de valeurs, les flux, les tables de données, les blogs et les wikis sont définis en tant que fournisseurs de données pour ThingWorx. Les fournisseurs de données sont considérés comme des bases de données qui stockent les données d'exécution. Ces données deviennent persistantes une fois les objets composés et utilisés par des appareils connectés pour stocker leurs données (température, humidité, position, etc.). Les fournisseurs de modèles sont utilisés pour stocker les métadonnées relatives aux objets.
Les fournisseurs de persistance peuvent contenir un fournisseur de données, un fournisseur de modèles ou les deux.
Pour en savoir plus sur les options de base de données, consultez la rubrique Fournisseurs de persistance.
Composants haute disponibilité
La haute disponibilité est un facteur essentiel de la continuité opérationnelle. Les composants haute disponibilité doivent être appliqués aux couches d'application et de base de données pour être effectifs.
Depuis la version 9.0, ThingWorx peut être déployé dans une configuration en cluster avec plusieurs noeuds de serveur actifs qui traitent la logique applicative et les requêtes des utilisateurs. Cette configuration remplace la configuration de basculement active-passive fournie dans les versions antérieures.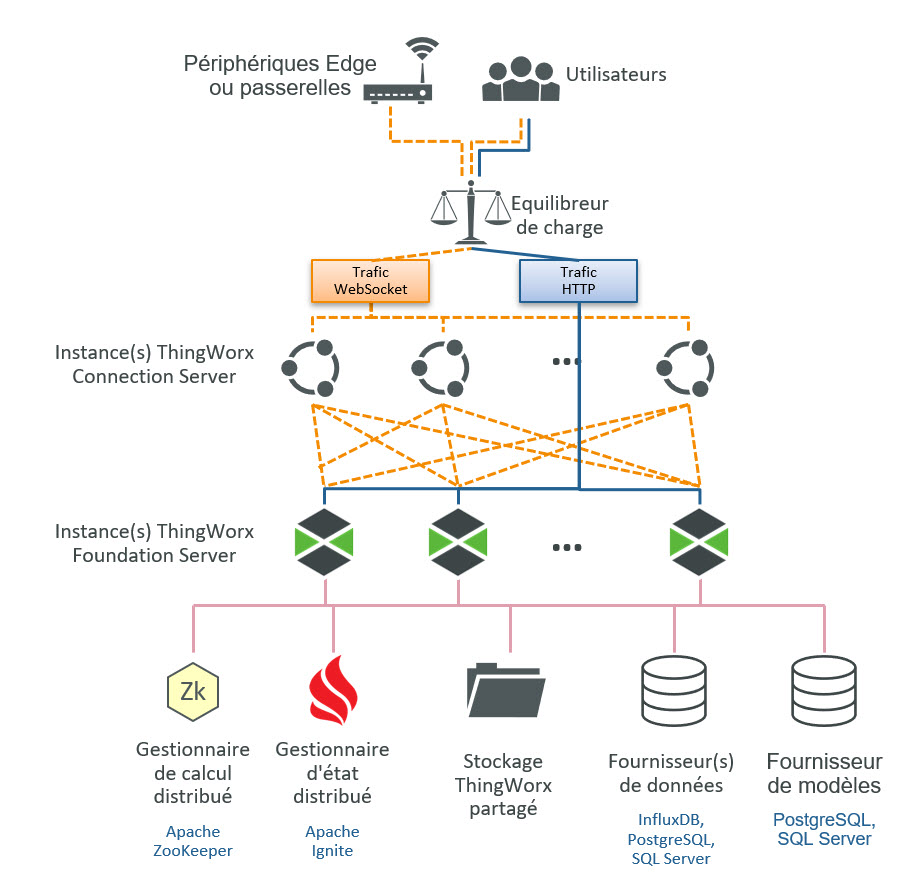
Dans une configuration en cluster, des serveurs de connexion sont nécessaires pour distribuer les connexions d'appareils sur les noeuds de cluster actifs.
La couche d'application ThingWorx nécessite Apache ZooKeeper et Apache Ignite en tant que composants supplémentaires. Les exigences de couche de base de données haute disponibilité dépendent des besoins du ou des fournisseurs de données sélectionnés.
Pour être vraiment efficace, la haute disponibilité devra tenir compte de facteurs autres que la pile de logiciels. L'infrastructure redondante, telle que les alimentations électriques, les disques durs et l'infrastructure réseau (routeurs, équilibreurs de charge, pare-feu, etc.) doit également être évaluée. |
• ZooKeeper : Apache ZooKeeper est un service centralisé permettant de gérer les informations de configuration et le nommage, de fournir une synchronisation distribuée et de fournir des services de groupe. Il s'agit d'un service de coordination pour application distribuée qui permet la synchronisation au sein d'un cluster. Spécifique à ThingWorx, ZooKeeper est utilisé pour surveiller la disponibilité des noeuds de cluster et choisit un nouveau noeud leader ThingWorx Foundation en cas d'échec.
• Ignite : Apache Ignite est une base de données distribuée ouverte, une plateforme de mise en cache et de traitement conçue pour stocker et calculer de gros volumes de données dans un cluster de noeuds. Dans un déploiement ThingWorx en cluster, Ignite est utilisé afin de stocker et de gérer un cache partagé pour les données d'appareil sur tous les noeuds du cluster.
Déploiement haute disponibilité avec empreinte minimale
Ignite peut être intégré dans le processus ThingWorx Foundation, qui ne nécessite pas d'installation distincte. S'il est intégré, Ignite ne doit être utilisé que lorsque l'empreinte de l'environnement est plus importante que les performances. Il doit être utilisé pour les petits environnements qui n'ont besoin que d'une haute disponibilité et non d'une mise à l'échelle. Il ne s'agit pas d'une solution évolutive ou adaptée aux problèmes de performances.
Dans le cas d'une intégration à deux serveurs Ignite, le seul avantage réside dans la lecture. Ignite marquera certaines données comme principales sur le serveur A, d'autres comme principales sur le serveur B et l'autre serveur comme sauvegarde des données. Normalement, toutes les lectures seront dirigées vers le serveur principal pour les données. Il peut s'agir d'un appel distant ou non. Si Ignite est intégré, la principale différence réside dans le fait que vous pouvez définir le paramètre de lecture à partir de "sauvegarde" sur "vrai". Dans ce cas, les lectures ne font pas de saut de réseau.
Les écritures peuvent avoir ou non la même machine et entraîneront une sauvegarde vers l'autre machine. Par conséquent, il n'existe aucun avantage de performances pour les écritures.
L'exécution d'Ignite, s'il est intégré, peut réduire les performances en fonction de la taille de la machine. Une configuration de ThingWorx à un seul serveur et une instance de serveur Ignite dans un cluster haute disponibilité sont différentes :
• La mémoire est partagée avec la plateforme. Ignite ajoute des files d'attente supplémentaires et d'autres objets en plus de stocker la mémoire des propriétés.
• Une JVM possède un nombre limité de threads pouvant être actifs à tout moment en fonction du nombre de ressources CPU. Ignite requiert de nombreux threads pour traiter les requêtes, sauvegarder les données ainsi que pour certaines tâches d'exception. Un serveur unique ne dispose pas de cette charge.
• Tous les objets vers et depuis le cache sont sérialisés dans et hors du cache dans un système haute disponibilité, ce qui n'est pas vrai avec la couche de cache Caffeine dans une configuration de serveur unique.
Fonctionnalités de haute disponibilité de la base de données
• PostgreSQL : ThingWorx prend en charge l'utilisation de la haute disponibilité PostgreSQL comme solution de données. La haute disponibilité permet de configurer des serveurs secondaires pour gérer les accès aux données en lecture et écriture, en cas de défaillance du serveur principal. Pour plus d'informations, consultez la rubrique Haute disponibilité PostgreSQL.
• SQL Server : en général, l'édition Standard de SQL Server est adaptée à une utilisation en production, car elle prend en charge la plupart des fonctionnalités requises. Pour les paramètres de production nécessitant des fonctionnalités de haute disponibilité, OLTP en mémoire ou le partitionnement de tables et d'index, l'édition Entreprise de SQL est recommandée. Pour en savoir plus, consultez la rubrique Haute disponibilité Microsoft SQL Server.
• InfluxDB Enterprise : fournit une version en cluster de la base de données InfluxDB. La mise en cluster permet de partager les données entre plusieurs noeuds afin de prendre en charge à la fois la haute disponibilité et l'évolution horizontale, ce qui permet de faire passer les lectures et les requêtes par différents serveurs pour accroître l'évolutivité de l'ensemble du système. Le nombre de noeuds de données peut facilement être étendu afin de prendre en charge de nouvelles charges de travail. Pour en savoir plus, consultez la rubrique Utilisation d'InfluxDB en tant que fournisseur de persistance.