Componentes de la implementación de ThingWorx Foundation
Los componentes de ThingWorx se pueden plantear en tres capas: cliente, aplicación y datos. En la siguiente imagen se muestra un punto inicial básico para cualquier solución ThingWorx:
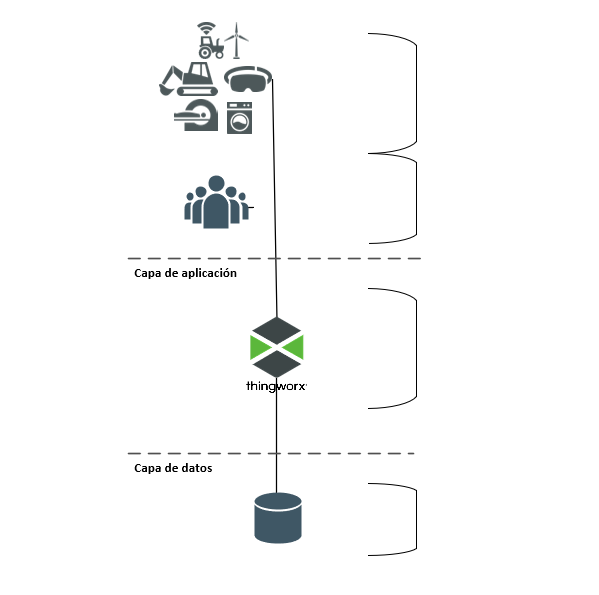 |
Cosas/dispositivos: en esta capa se incluyen las cosas, los dispositivos, los agentes y los demás activos que se conectan a ThingWorx Platform, le envían datos y reciben contenido de ella.
Usuarios y clientes: en esta capa se incluyen los productos (principalmente exploradores Web) que las personas utilizan para acceder a ThingWorx Platform.
|
|
Plataforma: la capa de plataforma (o el nivel de aplicación) es donde reside ThingWorx Foundation, que actúa como centro de un sistema ThingWorx. Esta capa proporciona la conectividad con la capa de cliente; realiza verificaciones de autenticación y autorización; ingiere, procesa y analiza el contenido y reacciona a las condiciones, como el envío de alertas.
|
|
|
Base de datos: la capa de base de datos conserva los metadatos del modelo de ThingWorx Runtime y los datos del sistema.
• Entre los metadatos del modelo se incluyen las definiciones de entidad de ThingWorx, las definiciones de cosa y las definiciones de propiedad asociadas.
• Los datos de tiempo de ejecución ingeridos en el modelo de ThingWorx. Los datos pueden ser datos de series tabulares o temporales que el modelo de ThingWorx almacena como filas de contenido en blogs, wikis, flujos, flujos de valor y tablas de datos.
|
Con el crecimiento de la capacidad y la complejidad de la solución de ThingWorx, las necesidades arquitectónicas de cada nivel crecen.
En las siguientes secciones se presenta cada componente de una solución de ThingWorx en el nivel o capa en la que opera el componente.
Componentes de usuario/cliente
El usuario o el cliente que accede a ThingWorx Platform a través de ThingWorx Composer o a través de los mashups en tiempo de ejecución debe disponer de un explorador moderno que soporte HTML/HTML5 (ejemplos: Microsoft Edge, Firefox, Safari o Chrome).
Componentes de cosa/dispositivo
• ThingWorx Edge MicroServer: ThingWorx Edge MicroServer (EMS) funciona con dispositivos Edge o almacenes de datos que necesitan conectarse al servidor ThingWorx a través de Internet. Permite a los dispositivos y almacenes de datos que están detrás de firewalls comunicarse de forma segura con el servidor ThingWorx y ser participantes completos en el entorno de la solución. ThingWorx EMS no es un conector simple, pero permite que la inteligencia y el procesamiento previo de datos se muevan a la periferia.
• ThingWorx Edge SDK: las instancias de ThingWorx Edge SDK son recopilaciones de clases, objetos, funciones, métodos y variables que proporcionan un marco para la creación de aplicaciones que puedan enviar datos de forma segura desde dispositivos Edge a ThingWorx Platform. Las instancias de ThingWorx Edge SDK proporcionan herramientas para los desarrolladores con experiencia en los lenguajes de programación C, .NET y Java.
ThingWorx EMS y ThingWorx Edge SDK soportan conexiones a través de servidores proxy. El proceso de gestión de la configuración del Proxy y la gestión de cambios asociados varía según el cliente y/o el proyecto. Las instancias de ThingWorx Edge SDK proporcionan la máxima flexibilidad porque cualquier componente Edge personalizado puede incluir bibliotecas del SDK o hacer referencia a ellas y, por lo tanto, se puede actualizar en función del diseño de la solución.
Componentes de la plataforma
• ThingWorx Connection Server: ThingWorx Connection Server es una aplicación de servidor que facilita la conexión de dispositivos remotos y gestiona toda la distribución de mensajes hacia los dispositivos y desde ellos. ThingWorx Connection Server proporciona una conectividad escalable sobre WebSockets mediante el protocolo de comunicación AlwaysOn de ThingWorx. PTC recomienda utilizar servidores de conexión cuando haya más de 25.000 activos para descargar la gestión de las conexiones del servidor ThingWorx Foundation. Los servidores de conexión son necesarios en configuraciones de alta disponibilidad para distribuir las conexiones de dispositivo entre los nodos de clúster activos. PTC también recomienda al menos un servidor de conexión para cada 100.000 conexiones simultáneas al servidor ThingWorx Foundation. Esta proporción de dispositivos a servidor de conexión puede cambiar en función de muchos factores, como los siguientes:
◦ El número de dispositivos
◦ La frecuencia de envíos de escritura desde los dispositivos
• Tomcat: Apache Tomcat es un contenedor de servlets de código abierto desarrollado por Apache Software Foundation (ASF). Tomcat implementa las especificaciones de Java Servlet y Java Server Pages (JSP) de Oracle Corporation y proporciona un entorno de servidor Web HTTP puro Java para que se ejecute el código Java.
• ThingWorx Foundation Server: ThingWorx Foundation proporciona un entorno completo de diseño, tiempo de ejecución e inteligencia para las aplicaciones de máquina a máquina (M2M) y de IoT. ThingWorx Foundation está diseñado para crear, ejecutar y aumentar eficazmente las aplicaciones que controlan y notifican datos de activos remotos, tales como dispositivos conectados, ordenadores, sensores y maquinaria industrial.
ThingWorx Foundation sirve de concentrador del entorno de ThingWorx. Incluye conjuntos de herramientas que ayudan a desarrollar aplicaciones para definir el comportamiento de los activos (o dispositivos) remotos implementados en el entorno y las relaciones entre los activos.
Una vez que los activos se hayan modelado, pueden registrarse y comunicarse con ThingWorx Foundation, lo que permite supervisar y gestionar los dispositivos físicos y recopilar datos de ellos.
Componentes de base de datos
ThingWorx Platform ofrece un modelo de almacén de datos conectable que permite a cada cliente elegir la base de datos que mejor se adapte a sus requisitos: desde pequeñas implementaciones para entornos de demostración o formación a bases de datos de gran volumen y alta disponibilidad que soportan miles de transacciones por segundo.
Los flujos de valor, los flujos, las tablas de datos, los blogs y los wikis se definen como proveedores de datos para ThingWorx. Los proveedores de datos se consideran bases de datos que almacenan datos en tiempo de ejecución. Los datos de tiempo de ejecución son datos que se almacenan después de componer cosas y los dispositivos conectados los utilizan para almacenar los datos (por ejemplo, la temperatura, la humedad o la posición). Los proveedores de modelos se utilizan para almacenar los metadatos de las cosas.
Los proveedores de persistencia pueden contener un proveedor de datos, un proveedor de modelos o ambos.
Para obtener más información sobre las opciones de base de datos, consulte Proveedores de persistencia.
Componentes de alta disponibilidad
La alta disponibilidad es una consideración crítica para la continuidad del negocio. Los componentes de alta disponibilidad se deben aplicar tanto en la aplicación como en las capas de base de datos para que sean eficaces.
A partir de la versión 9.0, ThingWorx se puede implementar en una configuración de clúster con varios nodos de servidor activos que procesan la lógica de negocio y las solicitudes de usuario. Esta configuración reemplaza a la configuración de conmutación por error activa-pasiva que se proporciona en versiones anteriores.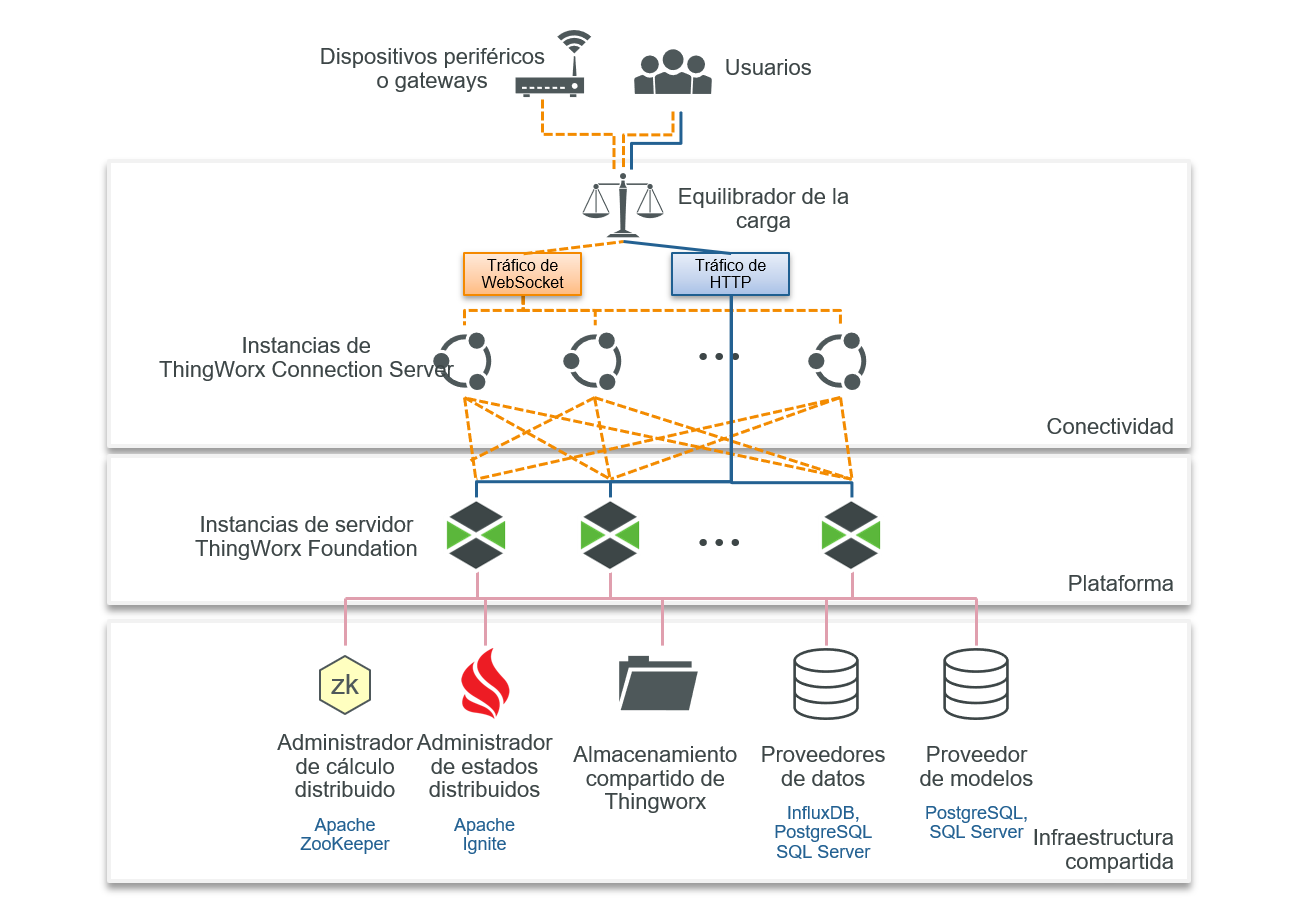
En una configuración agrupada, es necesario disponer de servidores de conexión para poder distribuir conexiones de dispositivo entre los nodos del clúster activos.
La capa de aplicación de ThingWorx requiere Apache Zookeeper y Apache Ignite como componentes adicionales. Los requisitos de capa de base de datos de alta disponibilidad dependen de las necesidades de los proveedores de datos seleccionados.
La alta disponibilidad tendrá consideraciones que van más allá de la pila de software para ser verdaderamente eficaz. También se debe evaluar la infraestructura redundante, como las fuentes de alimentación, los discos duros y la infraestructura de red (direccionadores, equilibradores de carga, firewalls, etc.). |
• Zookeeper: Apache Zookeeper es un servicio centralizado para conservar la información de configuración, asignar nombres y proporcionar sincronización distribuida y servicios de grupo. Se trata de un servicio de coordinación para la aplicación distribuida que permite la sincronización en todo un clúster. En particular para ThingWorx, Zookeeper se utiliza para supervisar la disponibilidad del nodo de clúster y elegir un nuevo nodo principal de ThingWorx Foundation en caso de un fallo.
• Ignite: Apache Ignite es una base de datos distribuida de código abierto, una plataforma de caché y procesamiento diseñada para almacenar y calcular grandes volúmenes de datos en todo un clúster de nodos. En una implementación de ThingWorx agrupada, Ignite se utiliza para almacenar y conservar una caché compartida para los datos de dispositivo en todos los nodos del clúster.
Implementación de alta disponibilidad con huella mínima
Ignite se puede ejecutar integrado en el proceso de ThingWorx Foundation, que no requiere una instalación independiente. La instancia de Ignite integrada solo se debe utilizar cuando la huella ambiental es más importante que el rendimiento. Debe utilizarse para entornos pequeños que solo necesitan alta disponibilidad y no el escalado. No es escalable ni tampoco es una solución para los problemas de rendimiento.
En un escenario de dos servidores de una instancia de Ignite integrada, la única ventaja es la lectura. Ignite marcará algunos datos como principales en el servidor A, algunos datos como principales en el servidor B y el otro servidor como copia de seguridad para los datos. Normalmente, todas las lecturas irán al servidor principal de los datos. Esto puede ser o no ser una llamada remota. En una instancia de Ignite integrada, la diferencia principal es que la lectura se puede definir en verdadera desde la copia de seguridad. En ese caso, las lecturas no saltan de una red a otra.
Las escrituras pueden o no ir a al mismo ordenador, y producirán una copia de seguridad en el otro ordenador. Por lo tanto, no hay ninguna ventaja de rendimiento para las escrituras.
La ejecución una instancia de Ignite integrada puede reducir el rendimiento en función del tamaño del ordenador. Una configuración de ThingWorx de un único servidor y una instancia de servidor Ignite en un clúster de alta disponibilidad son diferentes:
• La memoria se comparte con la plataforma. Ignite añade colas adicionales y otras cosas, además de almacenar la memoria de la propiedad.
• Una JVM tiene un número limitado de subprocesos que pueden estar activos en cualquier momento según el número de CPU. Ignite requiere muchos subprocesos para procesar solicitudes y realizar copias de seguridad de datos, y para algunas tareas de excepción. Un único servidor no tiene esta carga.
• Todos los objetos que entran y salen de la caché se serializan dentro y fuera de la caché en un sistema de alta disponibilidad, lo que no ocurre con la capa de caché de Caffeine en una configuración de servidor único.
Funciones de alta disponibilidad de la base de datos
• PostgreSQL: ThingWorx soporta el uso de la alta disponibilidad de PostgreSQL como solución de datos. La alta disponibilidad ofrece la opción de configurar servidores independientes para capturar lecturas y escrituras de datos si se produce un fallo en el servidor principal. Para obtener más información, consulte Alta disponibilidad de PostgreSQL.
• SQL Server: por lo general, SQL Standard Edition es apta para el uso en producción, ya que soporta la mayoría de las funciones necesarias. Para las configuraciones de producción que requieren funciones de alta disponibilidad, OLTP en memoria o partición de tabla e índice, se recomienda SQL Enterprise Edition. Para obtener más información, consulte Alta disponibilidad de Microsoft SQL Server.
• InfluxDB Enterprise: se proporciona una versión agrupada de la base de datos de InfluxDB. La agrupación permite que los datos se puedan compartir entre los nodos para soportar la alta disponibilidad y la escala horizontal, con lo que se pueden ejecutar lecturas y consultas a través de distintos servidores y así aumentar la escalabilidad de todo el sistema. El número de nodos de datos se puede expandir fácilmente para soportar nuevas cargas de trabajo. Para obtener más información, consulte Utilización de InfluxDB como proveedor de persistencia.