Mix characters from almost any language in a single string with Unicode support.
Creo Elements/Direct Modeling uses UTF-16 encoding for strings and textual data held in memory. Consequently, Creo Elements/Direct Modeling can process and support a large range of characters from all over the world. More precisely, all characters from the Unicode Basic Multilingual Plane (codepoints from U+0000 to U+FFFF) are supported.
You can use, for example, German, Japanese, Chinese, Hebrew, and Russian strings in the same session. You can even mix characters from all these languages in a single string.
While the Creo Elements/Direct Modeling core now supports characters from all these languages, this does not mean that localized versions are available for all languages.
All Creo Elements/Direct Modeling-specific file formats now support Unicode strings.
Because object names can contain all kinds of characters, Creo Elements/Direct Modeling uses an algorithm for setting the default font for its graphical user interface.
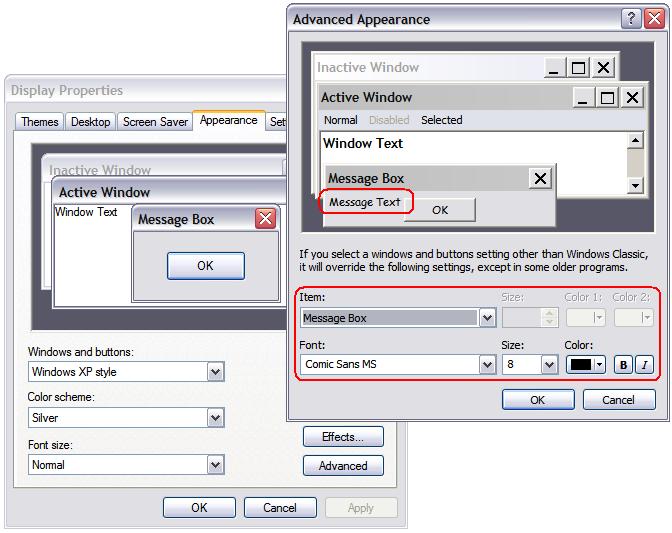
Windows provides defaults for UI element fonts, which Creo Elements/Direct Modeling inquires during startup and then uses for its user interface. You can review and change these defaults in the Advanced Appearance dialog box: Click Start > Settings > Control Panel > Display, then click Advanced in the Appearance tab.
Creo Elements/Direct Modeling derives from the operating system the fonts displayed in various elements of the user interface as follows:
Windows font type
Creo Elements/Direct Modeling UI element
Message Box
All UI controls in dialogs and browsers, except multiline edit fields
Menu
Application menu bar, popup menus
ToolTip
ToolTips, status bar
The default font for multiline edit controls is "MS Gothic" for the Japanese version of Creo Elements/Direct Modeling, and "Courier New" for all others. Its initial size derives from the message box font. To change this, click File > Settings > UI . The UI Settings dialog box opens. In Controls pane, click the Modify button to change the font.
By default, the font defaults selected by Windows cover all characters of the operating system's language; If you run a German or Japanese version of Windows, the defaults are already set so that you can use German or Japanese text without problems.
Output box
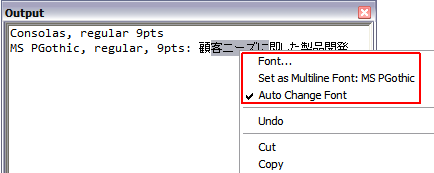
The Output box provides three right-click menu options related to Unicode support:
• Font: Set the font of the currently selected text. If you select no text, Creo Elements/Direct Modeling applies the specified font to any subsequently entered text.
• Set Multiline Font: (font name)
Use this convenient shortcut to change the default font for multiline edit controls (similar to File > Settings > UI. The UI Settings dialog box opens. In Controls pane, click the Modify button under Multiline Input Field Font). This context menu entry is only visible if text is selected, and the selected text uses only a single font.
• Auto Change Font: This option is enabled by default, so that the Output box automatically changes the current font as you add text. For instance, when Japanese text is entered and the currently active font does not have any Japanese character definitions, the Output box automatically selects a font capable of displaying Japanese characters. When this option is disabled, the Output box uses the global multiline edit control font.
These menu entries are also available from the context menu offered in the general text editor.
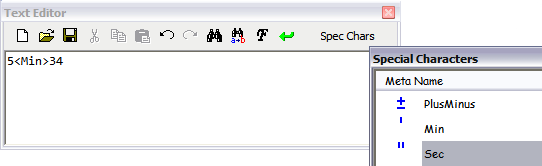
General text editor
The General Text Editor provides editing functionality in a toolbar docked at the top of the editor window. Depending on the command from which the editor is started, an additional special-purpose button might be displayed at the right most toolbar position. For example, the Creo Elements/Direct Annotation Text command displays the title Spec Chars in this button, and the button opens the Special Characters table:
The editor can load text files in Unicode and legacy encodings. When storing text from the editor, the resulting file is always encoded in UTF-8, and the file starts with a UTF-8 BOM.
Labels and fonts
Creo Elements/Direct Modeling uses stroke fonts to display labels and annotations in its 3D and 2D viewports (i.e., for both 3D Documentation and Creo Elements/Direct Annotation). The default stroke font is called osd_default; this is a merged font combining the fonts hp_i3098_v, hp_hangul_c, and hp_kanj2_c. Hence, this font covers both Western European and Japanese characters. In Creo Elements/Direct Annotation, two additional default fonts are available:
Creo Elements/Direct Modeling makes no distinction between one-byte and two-byte fonts.
For improved coverage of Unicode characters, Creo Elements/Direct Modeling supports Windows TrueType fonts. Creo Elements/Direct Modeling automatically detects installed TrueType fonts and converts them to stroke font format. Dialogs providing a font selection list both stroke fonts provided by Creo Elements/Direct and those derived from TrueType fonts. Hence, if you need to display 3D annotations in, say, Chinese, you can install a Windows TrueType font covering the Unicode code points assigned to Chinese characters, such as MS Mincho. Creo Elements/Direct Modeling then derives a stroke font from this font, which you may then use for 3D annotations.
If a 3D annotation has an assigned merged font (such as osd_default) and is saved in an older, backward-compatible Creo Elements/Direct Modeling format, Creo Elements/Direct Modeling assigns only one of the merged font's component fonts to the annotation label. The exact font choice depends on the current language. If the current language is Japanese, the two-byte sub-font will be used, otherwise it uses the one-byte sub-font.
Symbols use separate symbol fonts (hp_symbols, hp_symbols2).
Pre-2007 versions of Creo Elements/Direct Modeling did not support the full range of Unicode characters, and they used different encodings for their strings. The same is true for some applications for which Creo Elements/Direct Modeling provides export capabilities. When exporting data to such applications, Creo Elements/Direct Modeling must convert strings from their internal UTF-16 representation to the external character set and encoding. Since not all targets support the full Unicode range, the conversion process may be unable to transfer all characters. For example, because Russian was never supported in CoCreate Modeling 2006 and earlier, any attempt to export Russian characters from this version of Creo Elements/Direct Modeling may result in partial data loss.
The
file format table shows which encodings are used and supported by various export and import functions in Creo Elements/Direct Modeling. Depending on the kind of applications to which you must connect, you may want to restrict yourself to a subset of the Unicode character set supported both by Creo Elements/Direct Modeling and the target application.
Two examples illustrate this point:
• Let's say that you run the current German version of Creo Elements/Direct Modeling and create a model containing both German and Chinese characters. Your development partner still uses CoCreate Modeling 2006, so you store the model in backwards-compatible mode for data exchange. German versions of CoCreate Modeling 2006 use an encoding called HP-Roman8 to encode characters in strings, so this is the encoding to which your version of Creo Elements/Direct Modeling converts. However, HP-Roman8 covers only English and European characters, not Chinese characters. Consequently, the Chinese characters cannot be converted when written to the CoCreate Modeling 2006 file format.
• VRML 1.0 files encode strings in US-ASCII, so a strict implementation will use only English characters when storing data in this format.
When storing Creo Elements/Direct Modeling data (*.sd format) in backward-compatible mode, strings and names must be converted to legacy encoding. Names of objects appearing in the structure browser may contain characters not covered by the particular legacy encoding. To maintain uniqueness, such characters are replaced by a hexadecimal Unicode transcription (U+XXXX). This special handling applies to object names only. Elsewhere, such as in 3D Notes, underscore characters replace inconvertible characters.
The U+XXXX transcriptions are not converted back into the corresponding Unicode characters when loading such files back into the current version of Creo Elements/Direct Modeling.
When loading older files, Creo Elements/Direct Modeling automatically converts strings to its internal UTF-16 encoding. The source encoding is determined as follows:
• If the old file contains information about the language used for the strings contained in the file (release 14.50 and later), this information is used to derive the source encoding. For example, HP-Roman8 is assumed for Western European data, and Shift-JIS for Japanese data.
• If there is no such information (releases up to CoCreate Modeling 2006/v14.0x, i.e., in the majority of cases), Creo Elements/Direct Modeling assumes that the file to be loaded contains strings in the same language as the current Creo Elements/Direct Modeling language. So when loading, say, a CoCreate Modeling 2004 file into a German version of Creo Elements/Direct Modeling, Creo Elements/Direct Modeling assumes it contains German strings and uses HP-Roman8 encoding.
This is basically the same assumption as in older versions of Creo Elements/Direct Modeling. However, because an explicit conversion from either Roman8 or Shift-JIS is performed when loading legacy data into Creo Elements/Direct Modeling, this assumption now has practical consequences. Attempts to mix and match legacy encodings in unsupported ways (such as loading Japanese data into an English version) can result in data loss.
• The file browser also provides options to explicitly override the automatic encoding detection and conversion. This is useful, for example, when trying to load a Japanese legacy file into a German version of CoCreate Modeling 2007.
Editing Unicode text files
Not all text editors handle Unicode text files correctly. For example, WordPad (write.exe, ships with Windows) can corrupt UTF-8 files larger than 4094 bytes. Microsoft provides a
hotfix for this which is available from Microsoft upon request. However, we do not recommend WordPad for editing UTF-8 files.
Creo Elements/Direct Modeling ships with a customized version of the excellent open-source editor Notepad++, which correctly handles both UTF-8 and UTF-16 files. We're also shipping syntax highlighter files for Creo Elements/Direct Modeling Lisp and the Creo Elements/Direct Drafting macro language. If Notepad++ is installed on your system, Creo Elements/Direct Modeling uses it as its default external editor.
Other recommended editors:
• vim and gvim with settings :set encoding = utf-8 and :set bomb
• XEmacs 21.5 and later
• Emacs 22 and later
• Microsoft Visual Studio
• Microsoft's Notepad can be used as well. However, Notepad does not handle Unix-style line endings correctly, so files must be converted to DOS-style line endings before editing.