Solution Overview
This integration between DataFlowML and ThingWorx Analytics consists of a set of custom processors that can be built into DataFlowML pipelines to allow API access to analytics-ready datasets, scoring data, and retrieving results.
The solution includes four custom processors that provide specific functionality. For detailed information about configuring and using each custom processor, follow the appropriate links below.
• CreateDatasetProcessor – Creates analytics-ready datasets using
ThingWorx Analytics REST APIs and returns a Job ID to your pipeline.
• AsyncPredictionProcessor – Runs asynchronous scoring against a
ThingWorx Analytics dataset and returns a Job ID to your pipeline.
• SyncPredictionProcessor – Runs synchronous scoring against a
ThingWorx Analytics dataset and returns prediction results to your pipeline.
• ResultProcessor – With a Job ID from an asynchronous scoring job, returns CSV prediction results to your pipeline.
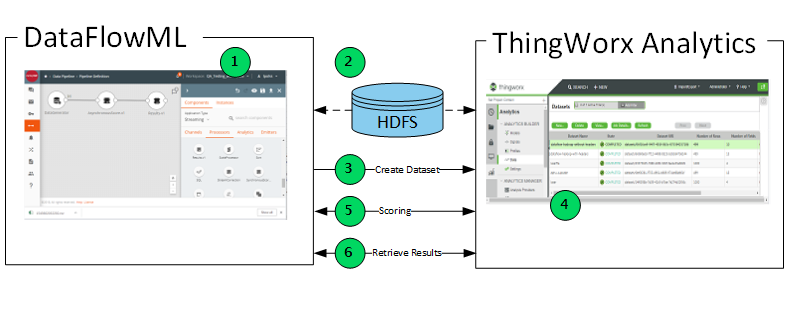
Flow Diagram
The integration between DataFlowML and ThingWorx Analytics is highly flexible. You can build your solution to use any of the available custom processors, together in a single pipeline or in multiple separate pipelines. For the purposes of generating an analytics-ready dataset, running batch or real-time scoring, and retrieving results, the interaction between the two products resembles the steps described below. The numbered steps correspond to the numbers in the image.
1. In DataFlowML, build a data pipeline that can access, transform, and prepare data for use by ThingWorx Analytics logic. You can access data from a variety of sources, including product usage history, service records, and product design information.
2. When the data, and possibly a corresponding JSON metadata file, have been accessed and prepared, make them available from an HDFS location. If preparing metadata, the JSON file can be made available from either the HDFS location or from any location supported by the ThingWorx Analytics Server.
3. Upload, configure, and run the Create Dataset processor. It accesses the CSV data from the HDFS location and generates an analytics-ready dataset. The new dataset is made available in ThingWorx Analytics and Analytics Builder.
4. Log into ThingWorx Analytics Builder. Manually launch a job to create a predictive model and select the newly created dataset on which to build the model. The training service runs on the dataset and outputs a PMML prediction model. Before leaving Analytics Builder, navigate to the new model, select it, and click View to open the Model Results page. Find and note the Model Result ID.
In addition to training a predictive model, you can use Analytics Builder to generate diagnostic analytics on the dataset, such as profiles and signals.
5. In DataFlowML, upload, configure, and run either of the scoring processors: Asynchronous Prediction processor or Synchronous Prediction processor. One of the following happens:
◦ Asynchronous Prediction – A batch scoring job runs and returns a jobID to your pipeline. In the next step, you can use the jobID to retrieve the prediction results.
◦ Synchronous Prediction – Real-time scoring runs and returns prediction scores directly to your pipeline. You can build some other processor into your pipeline to read or display the output.
6. If you ran an asynchronous scoring job, enter the output jobID as input for the Scoring Results processor and retrieve the prediction results.