Create Dataset Custom Processor
Overview
The Create Dataset custom processor can be built into a DataFlowML pipeline and used to generate an analytics-ready dataset. The data that the processor uses to create the dataset must be in CSV format and must be available from an HDFS location. The HDFS location, and a name for the new dataset, must be provided to the processor as configuration parameters.
When the Create Dataset processor is built into a DataFlowML pipeline and launched, the dataset creation job runs and a Job ID is output and returned to your pipeline. The newly created dataset can be used to train a ThingWorx Analytics model. You can access the new dataset to train a model either via REST API calls to the ThingWorx Analytics Server or by logging into Analytics Builder and running a New Predictive Model job.
|
|
Before using a Create Dataset pipeline in DataFlowML to create an analytics-ready dataset, create a JSON metadata file and upload it to the same HDFS location where the data is located. For information about the parameters and the required format of the metadata file, see the metadata chart in the Prepare Data and Metadata section of the ThingWorx Analytics Help Center. |
Uploading and Configuring the Processor
To use the Create Dataset processor, add it to a pipeline in DataFlowML and configure it with parameters as described below.
1. In DataFlowML, select
Data Pipeline from the left navigation panel (

). The
Pipeline Definition page opens.
2. In the panel on the right, ensure that the
Auto Inspection option is enabled. The default is enabled:

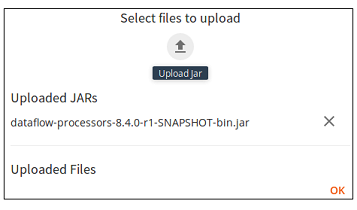
3. Upload the JAR file containing the custom processors as follows:
◦ Click the
Upload option (

). A file selection dialog box opens.
◦ Select the JAR file that contains the custom processors.
◦ Click OK. The JAR file is uploaded.
| This JAR file must be uploaded once for each pipeline that you create. |
4. Navigate to the Processors tab and select the Custom processor. Drag is to the pipeline page on the left to add it to the pipeline.
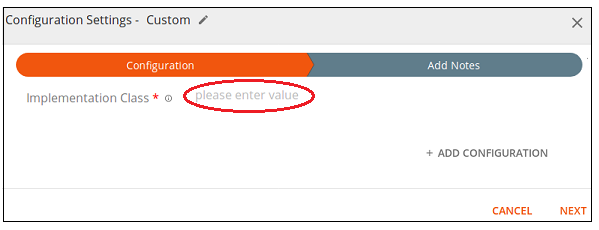
5. When the
Custom processor has been added to the pipeline, right-click on the processor icon (

). The
Configuration Settings – Custom dialog box opens.
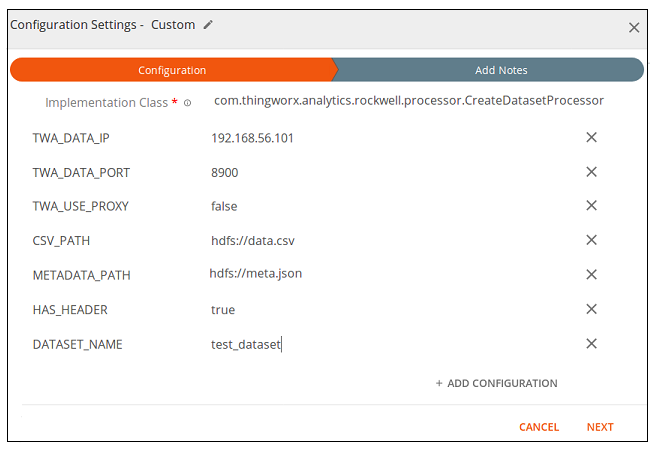
6. On the Configuration tab, enter the following Implementation Class value to identify the Custom processor as the Create Dataset processor:
com.thingworx.analytics.rockwell.processor.CreateDatasetProcessor
7. Click Add Configuration. A parameter row with two columns is added.
8. In the left column enter a key and in the right column, enter a corresponding value. For a list of the required and optional configuration parameters, see the charts below.
9. Repeat steps 7 and 8 until all necessary parameters are added.
10. After all parameters for the processor are added, click Next. The Add Notes tab is displayed.
11. Add any notes about the configuration and click Save. The processor configuration is saved and the dialog box closes.
Required Configuration Parameters
Key | Value |
Implementation Class | com.thingworx.analytics.rockwell.processor.CreateDatasetProcessor |
TWA_DATA_IP | The IP address of your ThingWorx Analytics Data microserver. |
TWA_DATA_PORT | The port where ThingWorx Analytics Data microserver is connected. To locate the port number, navigate to your ThingWorx Analytics Server installation directory and open the config/system-environment-variables.properties file. Port numbers are listed for each microservice. |
TWA_USE_PROXY | false = not installed behind a reverse proxy, true = is installed behind a reverse proxy |
CSV_PATH* | The location in HDFS and the name of a CSV file that is available for scoring. |
DATASET_NAME* | A name for the dataset you are creating. |
HAS_HEADER | false = the CSV data file does not include a header row, true = the CSV data file includes a header row |
METADATA_PATH | The location and name for a JSON metadata file. The metadata file can be accessed from any location supported by ThingWorx Analytics Server. Example: hdfs://metadata.json |
* These parameters can be provided as configuration parameters or they can be passed to the processor in a message sent from another component. If values for these parameters are provided in both ways, the message processing takes precedence.
Optional Configuration Parameters
Key | Value |
TAGS | String values that can be leveraged for search and filter purposes. Use a comma to separate each tag. |
TWA_DATA_PROXY_PATH | A URL for the reverse proxy, if in use. Optional parameter. Default path is /data. |
TWA_DATA_USE_SSL | false = running on HTTP, true = running on HTTPS |
Processor Input
There are no inputs required for the Create Dataset processor.
Processor Output
The Create Dataset processor outputs a Job ID and a Status URI in the form shown below. This information is returned to your pipeline.
{
"jobId": "",
"statusUri": ""
}
To use the newly-created dataset to train a prediction model, log into
Analytics Builder and navigate to the
Dataset list page. Select the new dataset from the list and click
New. A
New Predictive Model dialog box opens and you can define the training parameters for the predictive model. For more information about the model creation process, see
Creating New Predictive Models in the Analytics Help Center.