Ejemplo 2: Pocas cosas, pocas propiedades y alta frecuencia de escritura
Escenario
Resumen del escenario de nivel superior del ejemplo 2
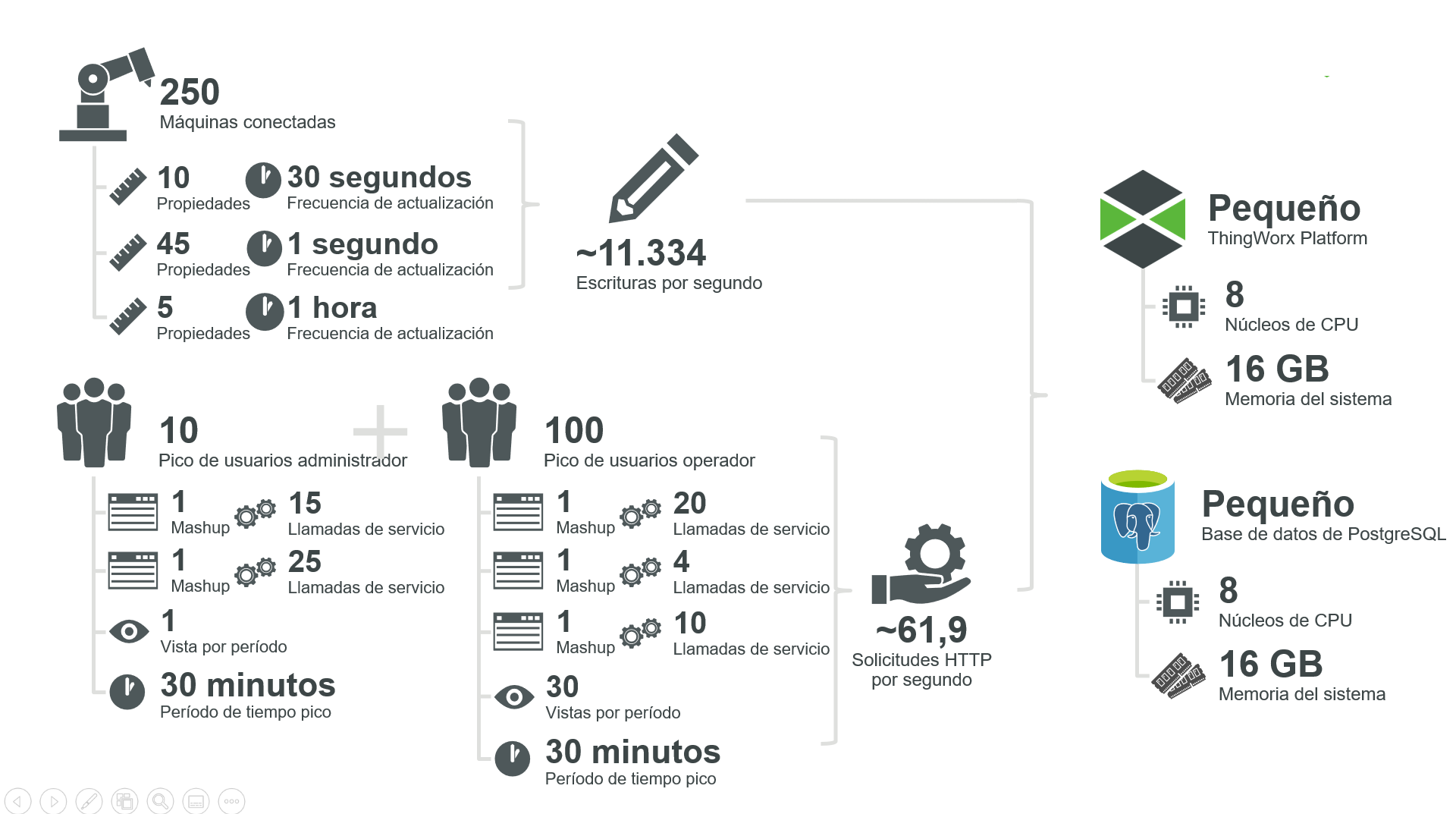
Una fábrica de tamaño medio donde hay 250 máquinas supervisadas y cada una de ellas envía actualizaciones de 60 propiedades a ThingWorx en distintas velocidades (consulte los requisitos).
El período pico de uso es de 30 minutos, momento en que 100 usuarios pueden realizar un número variable de llamadas a 5 mashups únicos, cada uno con un número variable de servicios. En esta configuración se utiliza una base de datos PostgreSQL.
Requisitos
• Número de cosas (T): 250 cosas
• Número de propiedades (P, tres grupos de propiedades diferentes en cada dispositivo):
P1 | P2 | P3 |
|---|---|---|
10 propiedades | 45 propiedades | 5 propiedades |
• Frecuencia de escritura (F):
F1 | F2 | F3 |
|---|---|---|
cada 30 segundos (2.880 por día) | cada segundo (86.400 por día) | cada hora (24 por día) |
• Período pico de uso (t) = 30 minutos o 1.800 segundos
• Número de mashups (M) = 5 mashups
• Número de usuarios (UM):
UM1 | UM2 | UM3 | UM4 | UM5 |
|---|---|---|---|---|
100 usuarios | 100 usuarios | 100 usuarios | 10 usuarios | 10 usuarios |
Nota: Los mashups con un número menor de solicitudes de usuario son comunes para los usuarios administrativos | ||||
• Número de servicios por mashup (SM):
SM1 | SM2 | SM3 | SM4 | SM5 |
|---|---|---|---|---|
20 servicios | 4 servicios | 10 servicios | 15 servicios | 25 servicios |
• Número de veces que los usuarios cargan cada mashup (LM):
LM1 | LM2 | LM3 | LM4 | LM5 |
|---|---|---|---|---|
30 veces | 30 veces | 30 veces | 1 vez | 1 vez |
Nota: 30 veces indica que los mashups 1, 2 y 3 se vuelven a cargar cada minuto durante los 30 minutos del período pico, probablemente mediante una renovación automática. | ||||
Cálculos
• Ingesta de datos:
WPS = T × [(P1 × F1) + (P2 × F2) + (P3 × F3)]
= 250× [(10 × 1/30) + (45 × 1) + (5 × 1/3600)]
≈ 11,334 writes per second
= 250× [(10 × 1/30) + (45 × 1) + (5 × 1/3600)]
≈ 11,334 writes per second
Esto es un poco más complejo, ya que hay propiedades que se escriben a diferentes velocidades. Recuerde que se puede dividir FD por 86.400 para su conversión a segundos si es necesario.
No se olvide de calcular también el valor de CS:
CS = T / 100,000
= 250/ 100,000
= 0.0025 Connection Servers
= 250/ 100,000
= 0.0025 Connection Servers
• Visualización de datos:
R = [(SM + 1) × UM × LM ] / t
R1 = [(20 + 1) × 100 × 30 ] / 1800
≈ 35 requests per second
R2 = [(4 + 1) × 100 × 30 ] / 1800
≈ 8.33 requests per second
R3 = [(10 + 1) × 100 × 30 ] / 1800
≈ 18.33 requests per second
R4 = [(15 + 1) × 10 × 1 ] / 1800
≈ 0.09 requests per second
R5 = [(25 + 1) × 10 × 1 ] / 1800
≈ 0.14 requests per second
R = R1 + R2 + R3 + R4 + R5
≈ 61.89 requests per second
R1 = [(20 + 1) × 100 × 30 ] / 1800
≈ 35 requests per second
R2 = [(4 + 1) × 100 × 30 ] / 1800
≈ 8.33 requests per second
R3 = [(10 + 1) × 100 × 30 ] / 1800
≈ 18.33 requests per second
R4 = [(15 + 1) × 10 × 1 ] / 1800
≈ 0.09 requests per second
R5 = [(25 + 1) × 10 × 1 ] / 1800
≈ 0.14 requests per second
R = R1 + R2 + R3 + R4 + R5
≈ 61.89 requests per second
En este escenario, cada mashup tiene un número diferente de servicios, mientras que a otros los llaman un número menor de usuarios. Además, algunos se renuevan cada minuto, mientras que otros solo se pueden cargar una vez.
En esta situación, debe asegurarse de no pasar por alto LM. Las llamadas de servicio adicionales para un mashup con la renovación automática pueden tener un impacto significativo en el tamaño del sistema.
Aunque este cálculo tiene más partes, el desglose de la ecuación para cada mashup y la adición de los resultados (ilustrados arriba) es sencilla.
Comparación de criterios
• T = 250 -> plataforma "extra-pequeña" (o grande, con PostgreSQL)
• CS = 0,0025 -> no se necesitan servidores de conexión
• WPS = 11.334 -> tamaño "pequeño" de plataforma (o mayor)
• R = 61,89 -> tamaño "mediano" de la plataforma (o mayor)
Tamaño
Dado que se necesita un sistema ThingWorx "mediano" para satisfacer todos los criterios, se debe tener en cuenta el siguiente tamaño, según el tipo de hosting:
Tamaño | Máquina virtual de Azure | EC2 de AWS | CPU Núcleos | Memoria (GiB) |
|---|---|---|---|---|
ThingWorx Platform: mediana | F16s v2 | C5d.4xlarge | 16 | 32 |
BD de PostgreSQL: mediana | F16s v2 | C5d.4xlarge | 16 | 32 |
Comparación de los resultados calculados y observados
En el ejemplo 2, la simulación imita una aplicación real con varios mashups que realizan diversas llamadas de servicio a distintas velocidades de renovación cada una, junto con cosas remotas simuladas que envían datos a la plataforma a velocidades variables.
Desde el punto de vista de la infraestructura, la plataforma se ha ejecutado correctamente, con un promedio del 34,8 % de uso de CPU y 3,1 GB de memoria. El promedio de PostgreSQL fue del 35,1 % de uso de CPU y 8,1 GB de memoria.
Desde el punto de vista de la plataforma, el promedio de la velocidad de las solicitudes HTTP fue de 63 operaciones por segundo, en línea con las 62 operaciones esperadas, y las escrituras de la cola de flujo de valor por segundo fueron estables, alrededor de 12.000 WPS en la práctica: cerca de las 11.300 WPS esperadas.
Resultados observados de la implementación simulada del ejemplo 2
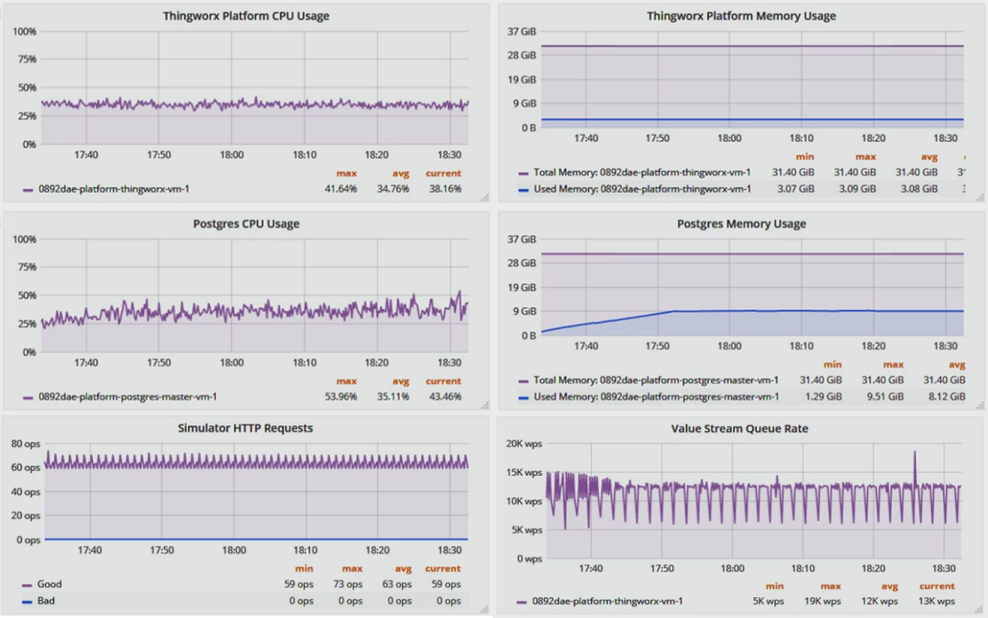
Desde el punto de vista de una aplicación o usuario, los simuladores de usuario o de dispositivo observaron que no hay errores, problemas de rendimiento o solicitudes/respuestas incorrectas. Todas las solicitudes nuevas se procesaron de manera oportuna.
Tal como se muestra en los gráficos anteriores, la implementación tiene suficientes recursos de reserva tanto para una carga de trabajo simulada y en régimen permanente, como para más picos del mundo real en la actividad de dispositivo y/o usuario.