PostgreSQL High Availability
PostgreSQL 11 must synchronize its data across all nodes for each node to be current when it receives read or write requests. There is no single solution to eliminate potential synchronization problems, so there are many HA options to consider. A comparison of HA solutions for PostgreSQL 11 is available as a list in table format here: https://www.postgresql.org/docs/11/different-replication-solutions.htmll.
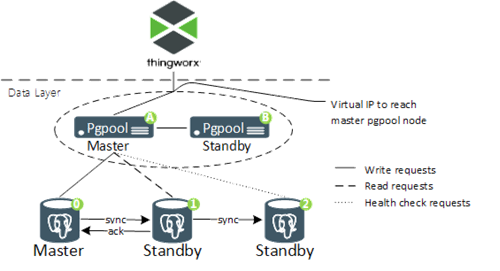
The following diagram illustrates PTC’s recommended configuration for a PostgreSQL HA deployment.
PostgreSQL
ThingWorx can write a large amount of content to its database, and it is important to keep the write sequence intact across all PostgreSQL nodes. PTC recommends that you configure all PostgreSQL nodes for synchronous replication within a cascading replication architecture, working with the limitations it places on synchronous replication. This option has the following requirements:
• Three equal sized PostgreSQL server nodes must be deployed.
◦ One node to be the master with write requests directed to it. The master streams WAL records to a standby node and will only commit transactions when the standby node has acknowledged it.
◦ One standby node to receive the streaming content from the master. It will also stream its content to a second standby node.
◦ One additional standby node to receive the streaming content from the first standby node. In the event of a node failure or one node going offline, this node will be one of the two remaining and still completes the master-standby acknowledged streaming process.
Pgpool-II
To complete the PostgreSQL HA configuration, write and read requests must be directed to the proper node, node health needs to be monitored, and unhealthy nodes need to be taken offline and repaired. PTC recommends Pgpool-II to accomplish these tasks. This option has the following requirements:
• Two equal sized Pgpool server nodes must be deployed. They operate in an active/passive mode.
◦ One node operates as the master. It directs write traffic to the PostgreSQL master node and read traffic to the PostgreSQL standby node.
◦ One node to operate as the standby. It will take over traffic distribution upon failure of the Pgpool master node.
• One virtual IP address to be managed by the Pgpool-II nodes. The master will use this address to receive PostgreSQL traffic from clients.
Notes on Pgpool-II:
• Pgpool-II is not supported in a Windows environment.
• Cloud implementations of PostgreSQL might use a direct DNS failover mechanism instead of Pgpool-II.
• You can run a Pgpool-II process on the same server as the ThingWorx application to reduce the total number of servers in a HA environment.
• PTC does not recommend using Pgpool-II for managing PostgreSQL replication. The guidance provided in this document uses PostgreSQL's streaming replication and Pgpool-II for traffic routing, node health monitoring, and failover automation.