ThingWorx Foundation Deployment Components
ThingWorx components can be thought about in three layers – Client, Application, and Data. The following image shows a basic starting point for any ThingWorx solution:
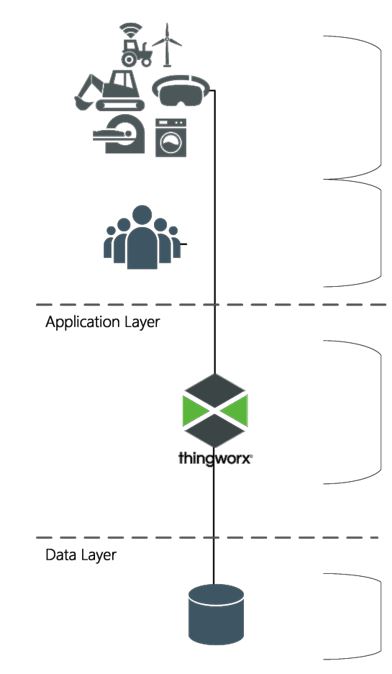 |
Things/Devices: This layer contains the things, devices, agents, and other assets that connect with, send data to, and receive content from the ThingWorx platform.
Users/Clients: This layer contains the products (primarily Web browsers) that people use to access the ThingWorx platform.
|
|
Platform: The platform layer (or application tier) is where ThingWorx Foundation resides, serving as the hub of a ThingWorx system. This layer provides connectivity to the client layer, performs authentication and authorization checks, ingests/processes/ analyzes content, and reacts to conditions like sending alerts.
|
|
|
Database: The database layer maintains ThingWorx runtime model metadata and system data:
• Model metadata includes ThingWorx entity definitions, Thing definitions, and their associated property definitions.
• Run time data ingested against the ThingWorx model. The data could be either tabular or time-series data that is persisted by the ThingWorx model as rows of content in blogs, wikis, streams, value streams, and data tables.
|
With the growth of the ThingWorx solution in capability and complexity, the architectural needs within each tier grow.
The following sections introduce each component of a ThingWorx solution within the tier or layer in which the component operates.
User/Client Components
The user or client accessing the ThingWorx platform through ThingWorx Composer or through run time mashups is required to have a modern browser that supports HTML/HTML5 (examples: Microsoft Edge, Firefox, Safari, or Chrome).
Thing/Device Components
• ThingWorx Edge MicroServer - The ThingWorx Edge MicroServer (EMS) works with edge devices or data stores that need to connect to the ThingWorx server over the internet. It enables devices and data stores that are behind firewalls to securely communicate with the ThingWorx server and be full participants in the solution landscape. ThingWorx EMS is not a simple connector but allows intelligence and pre-processing of data to be moved to the edge.
• ThingWorx Edge SDKs - ThingWorx Edge SDKs are collections of classes, objects, functions, methods, and variables that provide a framework for creating applications that can send data securely from edge devices to the ThingWorx platform. ThingWorx Edge SDKs provide tools for developers experienced in C, .NET, and Java programming languages.
ThingWorx EMS and ThingWorx Edge SDKs support connections through proxies. The process of managing the proxy configuration and associated change management varies by customer and/or project. ThingWorx Edge SDKs provide ultimate flexibility because the SDK libraries can be included or referenced by any custom edge component—and therefore can be updated based on the design of the solution.
Platform Components
• ThingWorx Connection Server - The ThingWorx Connection Server is a server application that facilitates the connection of remote devices and handles all message routing to and from the devices. The ThingWorx Connection Server provides scalable connectivity over WebSockets using the ThingWorx AlwaysOn communication protocol. PTC recommends using connection servers when there are more than 25,000 assets to offload managing connections from the ThingWorx Foundation server. Connection Servers are required in High Availability configurations in order to distribute device connections across the active cluster nodes. PTC also recommends at least one connection server for every 100,000 simultaneous connections to the ThingWorx Foundation server. This ratio of devices-to-connection server may change depending on many factors, such as the following:
◦ The number of devices
◦ The frequency of write submissions from the devices
• Tomcat - Apache Tomcat is an open-source servlet container developed by the Apache Software Foundation (ASF). Tomcat implements the Java Servlet and Java Server Pages (JSP) specifications from Oracle Corporation and provides a pure Java HTTP Web server environment for Java code to run.
• ThingWorx Foundation Server - ThingWorx Foundation provides a complete design, runtime, and intelligence environment for Machine-to-Machine (M2M) and IoT applications. ThingWorx Foundation is designed to efficiently build, run, and grow applications that control and report data from remote assets, such as connected devices, machines, sensors, and industrial equipment.
ThingWorx Foundation serves as the hub of your ThingWorx environment. It includes tool sets that help you develop applications to define the behavior of remote assets (or devices) deployed in your environment and relationships between the assets.
Once the assets have been modelled, they can register and communicate with ThingWorx Foundation, allowing you to monitor and manage the physical devices and collect data from them.
Database Components
The ThingWorx platform offers a pluggable data store model which allows each customer to choose the database that best suits their requirements - from small implementations for demo or training environments to highly available, high volume databases that support thousands of transactions per second.
Value streams, streams, data tables, blogs, and wikis are defined as data providers for ThingWorx. Data providers are considered databases that store runtime data. Runtime data is data that is persisted once the Things are composed and are used by connected devices to store their data (such as temperature, humidity, or position). Model providers are used to store metadata about the Things.
Persistence providers can contain a data provider, a model provider, or both.
For details on database options, refer to Persistence Providers.
High Availability Components
High availability is a critical consideration for business continuity. High-availability components must be applied at both the application and database layers to be effective.
Starting with the 9.0 release, ThingWorx can be deployed in a cluster configuration with multiple active server nodes processing business logic and user requests. This configuration replaces the active-passive failover configuration provided in prior releases.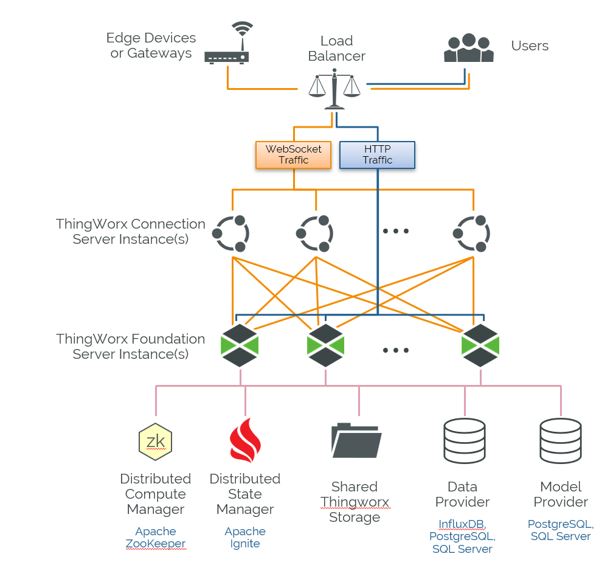
In a clustered configuration, Connection Servers are required in order to distribute device connections across the active cluster nodes.
The ThingWorx application layer requires Apache ZooKeeper and Apache Ignite as additional components. High Availability database layer requirements depend on the needs of the data provider(s) selected.
High Availability will have considerations beyond the software stack to be truly effective. Redundant infrastructure such as power supplies, hard disks, and network infrastructure (routers, load balancers, firewalls etc.) should also be evaluated. |
• ZooKeeper - Apache ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. It is a coordination service for distributed application that enables synchronization across a cluster. Specific to ThingWorx, ZooKeeper is used to monitor cluster node availability and elects a new ThingWorx Foundation leader node in the event of a failure.
• Ignite - Apache Ignite is an open-source distributed database, caching and processing platform designed to store and compute on large volumes of data across a cluster of nodes. In a clustered ThingWorx deployment, Ignite is used to store and maintain a shared cache for device data across all nodes in the cluster.
HA Deployment with Minimal Footprint
Ignite can be run embedded within the ThingWorx Foundation process, which does not require a separate installation. Embedded Ignite should only be used when the environment footprint is more important than performance. It should be used for small environments that only need high availability and not scaling. It is not scalable or a solution for performance issues.
In an embedded Ignite two-server scenario, the only advantage is with read. Ignite will mark some data as primary on server A, some data as primary on server B, and the other server as the backup for the data. Normally, all reads will go to the primary server for the data. This may or may not be a remote call. In embedded Ignite, the main difference is you can set read from backup to true. In that case, reads do not network hop.
Writes may or may not go to the same machine and will cause a backup to the other machine. Therefore, there is no performance benefit for writes.
Running embedded Ignite can reduce performance depending on the size of the machine. A single-server ThingWorx setup and an Ignite server instance in an HA cluster are different:
• Memory is shared with the platform. Ignite adds additional queues and other things in addition to storing property memory.
• A JVM has a limited number of threads that can be active at any time based on the number of CPUs. Ignite requires many threads to process requests, back up data, and for some exception tasks. A single server does not have this load.
• All objects going to and from the cache are serialized in and out of the cache in an HA system, which is not true with the caffeine cache layer in a single server setup.
Database High Availability features
• PostgreSQL - ThingWorx supports use of PostgreSQL high availability as the data solution. High availability offers the option to set up separate servers to capture reads and writes for data if a failure occurs on the primary server. For more information, refer to PostgreSQL High Availability.
• SQL Server - Generally, SQL Standard Edition is suitable for production use as it supports most of the features required. For production settings that require high-availability features, In-Memory OLTP, or table and index partitioning, SQL Enterprise Edition is recommended. For more information, refer to Microsoft SQL Server High Availability.
• InfluxDB Enterprise - Provides a clustered version of the InfluxDB database. Clustering enables data to be shared across nodes to support both high availability and horizontal scale, allowing reads and queries to run through different servers to increase scalability of the entire system. The number of data nodes can easily be expanded to support new workloads. For more information, refer to Using InfluxDB as the Persistence Provider.