Creo Elements/Direct Modeling の Unicode 対応
Unicode 対応により、単一の文字列にほとんどの言語の文字を混在させることができます。
Creo Elements/Direct Modeling では、メモリに保持された文字列およびテキストデータに対し、UTF-16 エンコーディングを使用します。このため、Creo Elements/Direct Modeling は世界中のさまざまな文字をサポートし、処理できます。より正確には、Unicode の基本多言語面 (Basic Multilingual Plane: BME) の全文字 (コードポイント U+0000 から U+FFFF まで) をサポートしています。
たとえば、ドイツ語、日本語、中国語、ヘブライ語、およびロシア語の文字列を同じセッションで使用することができます。さらに、1 つの文字列にこれらすべての言語の文字を混在させることも可能です。
Creo Elements/Direct Modeling はこれらの言語の文字をサポートしていますが、すべての言語でのローカライズバージョンが用意されているわけではありません。
Creo Elements/Direct Modeling のすべてのファイルフォーマットで、Unicode 文字列がサポートされています。
使用できるパーセル名
ユーザインターフェイス
オブジェクト名にはすべての種類の文字を含めることができます。このため、Creo Elements/Direct Modeling はアルゴリズムを使用して、グラフィカルユーザインターフェイス用のデフォルトフォントを設定します。
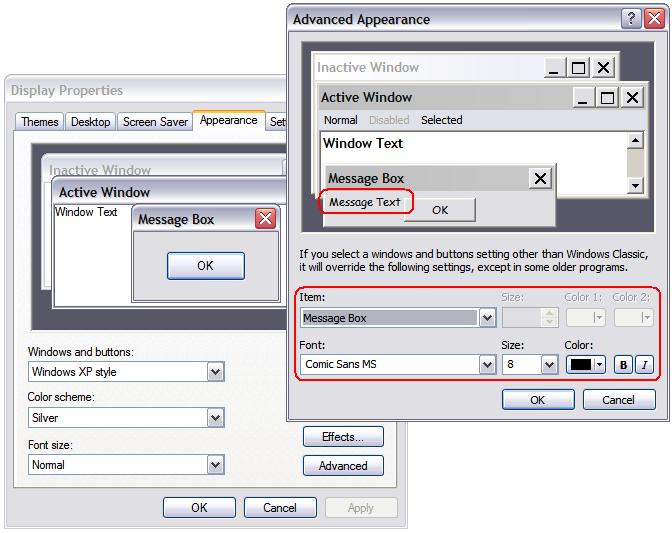
UI 要素フォント用のデフォルト設定は Windows により提供されます。Creo Elements/Direct Modeling の起動時に、このデフォルト設定が照会され、ユーザインターフェイスに使用されます。このデフォルト設定は、Windows の「デザインの詳細」ダイアログボックス ( > > > の順にクリックして、「デザイン」タブの「詳細設定」をクリック) で確認および変更できます。
Creo Elements/Direct Modeling では、ユーザインターフェイスのさまざまな要素で表示するフォントを、次のようにオペレーティングシステムから取得します。
Windows フォントタイプ | Creo Elements/Direct Modeling の UI 要素 |
|---|
メッセージボックス | ダイアログおよび一覧内のすべての UI コントロール (複数行編集フィールドを除く) |
メニュー | アプリケーションメニューバー、ポップアップメニュー |
ヒント | ツールのヒント、ステータスバー |
複数行編集の制御のデフォルトフォントは、日本語版の Creo Elements/Direct Modeling の場合は「MS ゴシック」、その他の場合は「Courier New」です。初期サイズはメッセージボックスフォントのサイズが使用されます。これを変更するには、 > > の順にクリックします。「UI 設定」ダイアログボックスが開きます。「制御」パネルで「編集」ボタンをクリックしてフォントを変更します。
既定では、Windows で選択されたデフォルトフォントが、オペレーティングシステムの言語のすべての文字に適用されます。ドイツ語版または日本語版の Windows を実行している場合、問題なくドイツ語または日本語のテキストが使用できるよう、デフォルトフォントがすでに設定されています。
出力ボックス
出力ウィンドウでは、Unicode サポートに関連する次の 3 つの右クリックメニューオプションを利用できます。
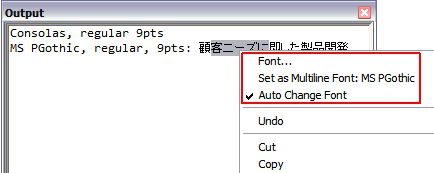
• フォント: 現在選択されているテキストのフォントを設定します。テキストを選択していない場合、Creo Elements/Direct Modeling により、続いて入力されるテキストに、指定したフォントが適用されます。
• 複数行フォントとして設定: (フォント名)
このショートカットは、複数行編集の制御のデフォルトフォントを変更する際に役立ちます ( > > と同様。「UI 設定」ダイアログボックスが開きます。「制御」パネルで、「複数行入力フィールドフォント」の下の「編集」ボタンをクリックします)。このコンテキストメニューエントリは、選択されたテキストが単一のフォントを使用している場合にのみ表示されます。
• フォント自動変更:このオプションはデフォルトで有効になっています。ユーザがテキストを追加すると、出力ウィンドウで現在のフォントが自動的に変更されます。たとえば、アクティブフォントに日本語の文字定義が含まれていない場合に日本語のテキストを入力すると、日本語を表示できるフォントが出力ウィンドウで自動的に選択されます。このオプションが無効になっている場合は、出力ウィンドウでグローバルな複数行編集の制御フォントが使用されます。
これらのメニューエントリは、汎用テキストエディタで示されるコンテキストメニューから利用することもできます。
汎用テキストエディタ
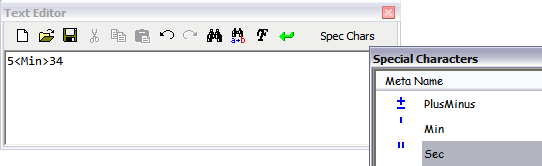
汎用テキストエディタでは、エディタウィンドウの上部に配置されているツールバーから編集機能を使用することができます。エディタを開始するコマンドによって異なる、特別な用途の追加ボタンがツールバーの右端に表示されます。たとえば、Creo Elements/Direct Annotation テキストコマンドの場合、「特殊文字」というタイトルがこのボタンに表示され、ボタンを押すと特殊文字テーブルが開きます。
このエディタで、Unicode またはレガシーエンコーディングのテキストファイルをロードできます。このエディタでテキストを保管すると、ファイルは常に UTF-8 でエンコードされ、ファイルの最初に UTF-8 BOM が追加されます。
ラベルとフォント
Creo Elements/Direct Modeling では、3D および 2D ビューポート内のラベルおよび Annotation の表示 (つまり、3D Documentation および Creo Elements/Direct Annotation の両方) に、ストロークフォントが使用されます。デフォルトのストロークフォントの名前は、osd_default です。このフォントは、hp_i3098_v、hp_hangul_c、hp_kanj2_c フォントをまとめて統合したフォントです。したがって、このフォントは西ヨーロッパおよび日本語の文字に対応しています。Creo Elements/Direct Annotation では、次の 2 つのデフォルトフォントが利用可能です。
• osd_default2 combines hp_i3098_c, hp_hangul_c,and hp_kanj2_c.
• osd_default3 combines hp_d17_v, hp_hangul_c,and hp_kanj2_c.
Creo Elements/Direct Modeling では、1 バイトと 2 バイトフォントの区別はありません。
Unicode 文字に広く対応するため、Creo Elements/Direct Modeling では Windows TrueType フォントの使用をサポートしています。Creo Elements/Direct Modeling により、インストールされている TrueType フォントが自動で検出され、ストロークフォント形式に変換されます。フォントを選択できるダイアログに、Creo Elements/Direct から提供されるストロークフォントと TrueType フォントから変換したストロークフォントの両方がリストされます。したがって、たとえば中国語の 3D Annotation を表示する必要がある場合は、漢字に割り当てられた Unicode コードポイントに対応している Windows TrueType フォント (MS Mincho など) をインストールすることができます。インストール後、Creo Elements/Direct Modeling により、このフォントから 3D Annotation で使用できるストロークフォントが作成されます。
統合されたフォント (osd_default など) が割り当てられている 3D Annotation を、古い下位互換性のある Creo Elements/Direct Modeling 形式で保存した場合、Creo Elements/Direct Modeling により、統合されたフォントの構成要素のうち、いずれかのフォントが Annotation ラベルに割り当てられます。正確なフォントの選択は、現在の言語によって変わります。現在の言語が日本語である場合は 2 バイトのサブフォントが使用され、そうでない場合は 1 バイトのサブフォントが使用されます。
シンボルには、個別のシンボルフォントが使用されます (hp_symbols、hp_symbols2)。
ファイル名の変換
言語の設定
ファイルの下位互換性
Creo Elements/Direct Modeling の 2007 以前のバージョンでは、Unicode 文字が完全にはサポートされておらず、文字列に対していろいろなエンコーディングが適用されていました。これは、Creo Elements/Direct Modeling のエクスポートデータを使用できる一部のアプリケーションでも同様です。これらのアプリケーションにデータをエクスポートする場合は、Creo Elements/Direct Modeling により、文字列が内部の UTF-16 表現から外部の文字セットおよびエンコーディングに変換される必要があります。しかし、対象となるアプリケーションでは Unicode 範囲の全体がサポートされているとは限らないため、この変換プロセスでは、一部の文字が転送できない場合があります。たとえば、ロシア語は Creo Elements/Direct Modeling 2006 以前ではサポートされていないため、Creo Elements/Direct Modeling のこのバージョンからロシア語の文字をエクスポートすると、部分的にデータが損なわれる場合があります。
ファイル形式の表では、
Creo Elements/Direct Modeling の各種エクスポートおよびインポート機能で使用およびサポートされているエンコーディングを記載しています。データを交換するアプリケーションの種類に応じて、
Creo Elements/Direct Modeling および対象アプリケーションの両方でサポートされている Unicode 文字のサブセットを使用するようにします。
以下は、この点に関する 2 つの例です。
• Creo Elements/Direct Modeling の現在のバージョンのドイツ語版を実行し、ドイツ語の文字と漢字をともに含むモデルを作成するとします。CoCreate Modeling 2006 を使用している開発パートナーとデータ交換を行うため、下位互換性のあるモードでモデルを保存します。ドイツ語版の CoCreate Modeling 2006 は、HP-Roman8 というエンコーディングで文字列内の文字をエンコードします。そのため、Creo Elements/Direct Modeling のご使用のバージョンにより、モデルのエンコーディングは HP-Roman8 に変換されます。しかし、HP-Roman8 は、英語およびヨーロッパ言語の文字のみに対応しており、漢字には対応していません。そのため、CoCreate Modeling 2006 ファイル形式に書き出す場合、漢字が変換されません。
• VRML 1.0 ファイルでは、文字列が US-ASCII でエンコードされるため、この形式でデータを保存する場合は、必ず英語の文字のみを使用するようにします。
下位互換性のあるモードで Creo Elements/Direct Modeling データ (*.sd フォーマット) を保存する場合、文字列と名前をレガシーエンコーディングに変換する必要があります。構造一覧に表示されるオブジェクト名は、特定のレガシーエンコーディングで変換されない文字を含むことができます。固有性を保つため、これらの文字は 16 進法の Unicode 表現 (U+XXXX) で置き換えられます。この特別な処理は、オブジェクト名にのみ適用されます。その他の要素 (3D 注記など) では、変換できない文字はアンダースコア文字に置き換えられます。
| このようなファイルを Creo Elements/Direct Modeling の現在のバージョンに再度ロードしても、U+XXXX 形式での表現は、元の対応する Unicode 文字に変換されません。 |
以前のファイルをロードする場合、Creo Elements/Direct Modeling により文字列が自動で内部の UTF-16 エンコーディングに変換されます。ソースエンコーディングは次のように決定されます。
• 以前のファイルに、ファイル内の文字列に用いる言語についての情報が含まれている場合 (リリース 14.50 以降)、この情報からソースエンコーディングが判別されます。たとえば、西ヨーロッパ言語のデータには HP-Roman8 、日本語のデータには Shift-JIS が想定されます。
• こうした情報が存在しない場合 (多くの場合は、CoCreate Modeling 2006/v14.0x までのリリース)、Creo Elements/Direct Modeling では、ロードされたファイルに現在の Creo Elements/Direct Modeling の言語と同じ言語が含まれていると想定されます。そのため、たとえば CoCreate Modeling 2004 ファイルを Creo Elements/Direct Modeling のドイツ語版にロードすると、Creo Elements/Direct Modeling はこのファイルにドイツ語の文字列が含まれていると想定し、HP-Roman8 エンコーディングを使用します。
これは、基本的に古いバージョンの Creo Elements/Direct Modeling での想定と同じです。ただし、Roman8 または Shift-JIS からの明示的な変換はレガシーデータを Creo Elements/Direct Modeling にロードする際に実行されるため、ここでの想定は実際的な因果関係を持ちます。サポートされていない方法 (日本語データを英語バージョンにロードするなど) で異なるレガシーエンコーディングを組み合わせようとした場合、データが失われることがあります。
• ファイル一覧オプションには、自動エンコーディングの検出と変換を明示的にオーバーライドするオプションもあります。このオプションは、たとえば日本語のレガシーファイルをドイツ語版の CoCreate Modeling 2007 にロードする場合などに便利です。
Unicode テキストファイルの編集
すべてのテキストエディタで Unicode テキストファイルが正しく処理できるわけではありません。たとえば、ワードパッド (Windows に添付されている write.exe) では 4094 バイトより大きな UTF-8 ファイルのデータが壊れる可能性があります。Microsoft ではこの問題に対する
ホットフィックスを、リンク先で公開しています。ただし、UTF-8 ファイルの編集にワードパッドを使用することはお勧めできません。
Creo Elements/Direct Modeling にはオープンソースの優れたエディタである Notepad++ のカスタマイズバージョンが同梱されていて、UTF-8 および UTF-16 でエンコードされているファイルの両方を正しく処理できます。また、Creo Elements/Direct Modeling Lisp および Creo Elements/Direct Drafting マクロ言語用の構文ハイライタファイルも同梱されています。ご使用のシステムに Notepad++ がインストールされている場合は、Creo Elements/Direct Modeling でデフォルトの外部エディタとして使用されます。
その他、下記のようなエディタを推奨します。
• XEmacs 21.5 以降
• Emacs 22 以降
• Microsoft Visual Studio
• Microsoft のメモ帳も使用することができます。ただし、メモ帳では UNIX 形式の行末が正しく処理されないため、編集前にファイルを DOS 形式の行末に変換しておく必要があります。