Speaker Recognition
Azure Speaker Recognition を使用すると、話者を識別したり、音声を使用してユーザーを認証したりできます。詳細については、
Azure Speaker Recognition を参照してください。
「Speaker Recognition」操作は、話者を識別または認証するために使用します。
ワークフローで「Speaker Recognition」操作を使用するには、次の手順を完了します。
1. 「Azure」の下の「Speaker Recognition」操作をキャンバスにドラッグし、この操作にマウスポインタを合わせて  をクリックするか、この操作をダブルクリックします。
をクリックするか、この操作をダブルクリックします。
をクリックするか、この操作をダブルクリックします。「Speaker Recognition」ウィンドウが開きます。
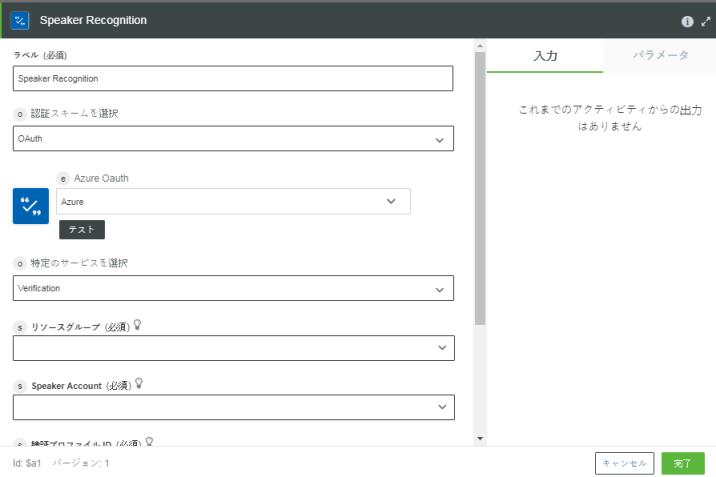
2. 必要に応じて、「ラベル」を編集します。デフォルトでは、ラベル名は操作名と同じです。
Azure の認証スキームを事前に追加している場合、リストから選択します。
4. 「特定のサービスを選択」リストで、次のいずれかのオプションを選択して、次の操作を行います。
◦ 「検証」を選択し、次の操作を実行します。
1. 「リソースグループ」リストで、Azure サブスクリプションで定義されている適切なリソースグループを選択します。
2. 「話者のアカウント」リストで、適切な Speaker Recognition アカウントを選択します。
3. 「検証プロファイル ID」リストで、Speaker Recognition アカウントのプロファイル ID を選択します。
4. 「オーディオファイル」フィールドで、前の操作の出力をマッピングしてオーディオファイルのパスを指定します。
◦ 「識別」を選択し、次の操作を実行します。
1. 「リソースグループ」リストで、Azure サブスクリプションで定義されている適切なリソースグループを選択します。
2. 「話者のアカウント」リストで、適切な Speaker Recognition アカウントを選択します。
3. 「オーディオファイル」フィールドで、前の操作の出力をマッピングしてオーディオファイルのパスを指定します。
4. 「話者」グループの「識別プロファイル ID」リストで、Speaker Recognition アカウントのプロファイル ID を選択します。
複数のプロファイル ID を追加するには、「追加」をクリックします。または、 をクリックしてプロファイル ID を削除します。
をクリックしてプロファイル ID を削除します。
をクリックしてプロファイル ID を削除します。5. 「完了」をクリックします。
出力スキーマ
「Speaker Recognition」操作の出力スキーマは、信頼水準およびフレーズを含む結果を返します。
「検証」に対する「結果」は、承認または却下であり、「フレーズ」は話者が話す文章です。
「識別」の「結果」は、その人物の ID です。Speaker Recognition API が一致するプロファイル ID を見つけられない場合、「結果」として Null 値が返されます。この操作では、「フレーズ」フィールドに Null 値が返されます。
以下の図にサンプル出力スキーマを示します。
