Computer Vision
Azure Computer Vision を使用することで、開発者はイメージを処理して情報を返す高度なアルゴリズムを使用できます。イメージを分析するには、イメージをアップロードするかイメージの URL を指定します。処理アルゴリズムは、さまざまな視覚的特徴に応じて、イメージのコンテンツをさまざまな方法で分析できます。たとえば、Computer Vision はイメージ内の人の顔をすべて検索できます。詳細については、
Azure Computer Vision を参照してください。
「Computer Vision」操作は、イメージを分析したり、イメージをドメインによって分析したりして、イメージについて説明し、イメージの視覚的特徴や特性を検出して知見を得るときに使用します。
イメージが次の要件を満たしていることを確認します。
• フォーマット: JPEG、PNG、GIF、または BMP
• ファイルサイズ: 4 MB 未満
• 寸法: 50 x 50 ピクセルから 4200 x 4200 ピクセルの範囲内
• サイズ: 10 メガピクセル以下
ワークフロー内で「Computer Vision」操作を使用するには、次の手順を完了します。
1. 「Azure」コネクタの下の「Computer Vision」操作をキャンバスにドラッグし、この操作にマウスポインタを合わせて  をクリックするか、この操作をダブルクリックします。
をクリックするか、この操作をダブルクリックします。
をクリックするか、この操作をダブルクリックします。「Computer Vision」ウィンドウが開きます。
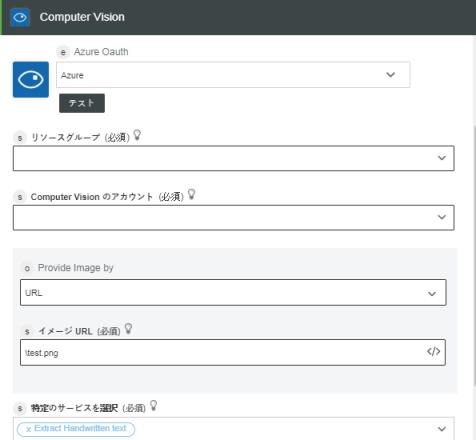
2. 必要に応じて、「ラベル」を編集します。デフォルトでは、ラベル名は操作名と同じです。
Azure の認証スキームを事前に追加している場合、リストから選択します。
4. 「リソースグループ」リストで、Azure サブスクリプションで定義されている適切なリソースグループを選択します。
5. 「Computer Vision アカウント」フィールドで、適切な Computer Vision アカウントを選択します。
6. 「イメージの指定方法」リストで、次のいずれかのオプションを選択して、次の操作を行います。
◦ 「URL」を選択し、「イメージ URL」フィールドでパブリックアクセスが可能なイメージ URL を指定します。
◦ 「ファイルをアップロード」を選択し、「イメージファイルのパス」フィールドで、前の操作の出力をマッピングしてイメージのパスを指定します。
7. 「特定のサービスを選択」リストで、実行するイメージ解析の種類に応じて次のいずれかの Computer Vision サービスを選択し、各タスクを実行します。
サービス | タスク |
|---|---|
「イメージを分析」 - イメージからさまざまな視覚的特徴を抽出します。 | a. 「ビジュアル機能」リストで、イメージ分析に使用する機能を選択します。 ◦ 「カテゴリ」 - カテゴリに従ってイメージのコンテンツを分類します。 ◦ 「説明」 - イメージのコンテンツを完全な英語の文章で説明します。 ◦ 「色」 - イメージが白黒またはカラーのどちらかを示し、カラーの場合はドミナントカラーとアクセント色を検出します。 ◦ 「タグ」 - イメージに、イメージのコンテンツに関連する単語の詳細なリストをタグ付けします。 ◦ 「顔」 - イメージ内に顔が存在するかどうかを検出します。 ◦ 「イメージタイプ」 - イメージがクリップアートか線画かを検出します。 ◦ 「成人向け」 - イメージがポルノの類であるかや、イメージが性的なものを想起させるコンテンツを描写しているかどうかを検出します。 ◦ 「オブジェクト」 - イメージ内の各種オブジェクトを検出します。 複数のビジュアル機能を追加するには、「追加」をクリックします。または、  をクリックして、追加した任意のビジュアル機能を削除します。 をクリックして、追加した任意のビジュアル機能を削除します。b. 「詳細」で「追加」をクリックし、次のうち、いずれのドメイン固有の詳細を含めるかを選択します。 ◦ 「有名人」 - イメージ内で検出された有名人を特定します。 ◦ 「ランドマーク」 - イメージ内の著名なランドマークを特定します。 複数の詳細を追加するには、「追加」をクリックします。または、 をクリックして、追加した詳細を削除します。 |
「ドメインによってイメージを分析」 - ドメイン固有のモデルを適用することで、イメージからコンテンツを認識します。 | a. 「モデル」フィールドで、イメージ分析に使用する必要のあるドメイン固有モデルを指定します。 b. 「言語」フィールドで、出力を生成する言語を選択します。デフォルトでは、「英語」が選択されています。 |
「イメージを説明」 - イメージのコンテンツを、人間が判読可能な完全な文章で説明します。 | a. 「最大候補数」フィールドで、サービスが返す候補の説明の最大数を入力します。 b. 「言語」リストで、出力を生成する言語を選択します。デフォルトでは、「英語」が選択されています。 |
「オブジェクトを検出」 - イメージに対してオブジェクト検出を実行します。 | – |
「サムネイルを生成」 - 指定されたイメージのサムネイルイメージを生成します。 | a. 「幅」フィールドで、サムネイルの幅を 1 から 1024 ピクセルの間で指定します。50 以上の値を指定することをお勧めします。 b. 「高さ」フィールドで、サムネイルの高さを 1 から 1024 ピクセルの間で指定します。50 以上の値を指定することをお勧めします。 c. 「スマートトリミング」リストで、「真」を選択してスマートトリミングを有効にします。 スマートトリミングを有効にしない場合、「偽」を選択します。 |
「印刷されたテキストを抽出 (OCR)」 - イメージ内のテキストを検出し、認識された文字をマシンで使用可能な文字ストリーム内に抽出します。 | a. 「言語」リストで、イメージ内のテキストの言語を選択します。デフォルトでは、「不明」が選択されています。 b. イメージ内のテキストの方向を検出して修正してから以降の処理を行うには、「方向を検出」リストで「真」を選択します。 イメージ内のテキストの方向を検出しない場合、「偽」を選択します。 |
「手書きのテキストを抽出」 - イメージから手書きのテキストを抽出します。 | – |
「タグイメージ」 - イメージのコンテンツに関連するタグのリストを生成します。 | a. 「言語」リストで、出力を生成する言語を選択します。デフォルトでは、「英語」が選択されています。 |
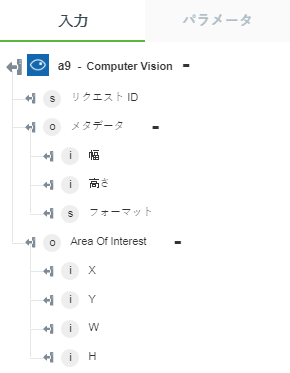
「興味のある分野を取得」 - イメージの最も重要な領域を囲む境界ボックスを返します。 | – |
8. 「完了」をクリックします。
出力スキーマ
各「Computer Vision」サービスに独自の出力スキーマがあります。
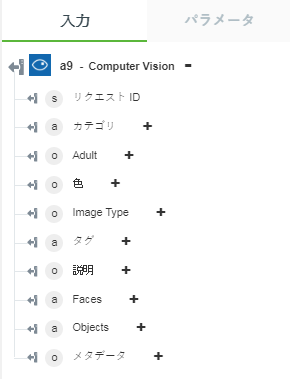
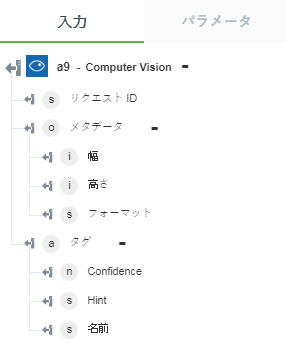
• 「イメージを分析」 - 選択されたビジュアル機能を返します。
以下の図にサンプル出力スキーマを示します。
• 「ドメインによってイメージを分析」 - イメージ内で認識されたコンテンツを返します。
以下の図にサンプル出力スキーマを示します。

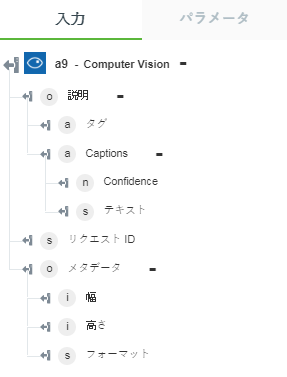
• 「イメージを説明」 - イメージの説明を返します。
以下の図にサンプル出力スキーマを示します。
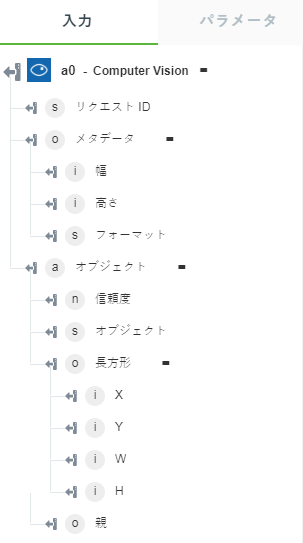
• 「オブジェクトを検出」 - オブジェクトとその座標を返します。
以下の図にサンプル出力スキーマを示します。
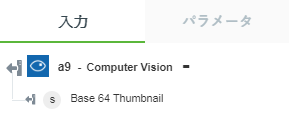
• 「サムネイルを生成」 - サムネイルイメージを返します。
以下の図にサンプル出力スキーマを示します。
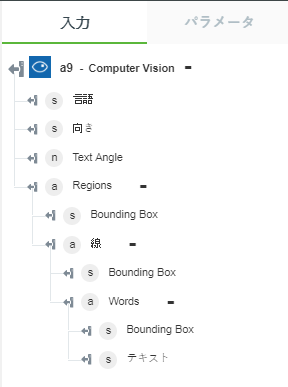
• 「印刷されたテキストを抽出 (OCR)」 - イメージ内から抽出したテキストを返します。
以下の図にサンプル出力スキーマを示します。
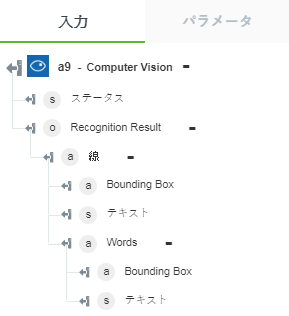
• 「手書きのテキストを抽出」 - イメージ内の手書きのテキストを返します。
以下の図にサンプル出力スキーマを示します。
• 「タグイメージ」 - 検出されたイメージのタグを返します。
以下の図にサンプル出力スキーマを示します。
• 「興味のある分野を取得」 - 最も重要な領域を囲む座標を返します。
以下の図にサンプル出力スキーマを示します。