Services de table de données
Il existe un certain nombre de services intégrés permettant d'insérer et d'extraire des données des tables de données qui sont spécifiques à la forme de table de données. Ils se présentent comme suit :
• AddDataTableEntry (TAGS tags, VALUES values) : transmet le paramètre VALUES et, facultativement, tags. Le retour booléen indique si l'opération a réussi ou non.
• AddDataTableEntries
: ajoute plusieurs entrées de table de données.
• AddOrUpdateDataTableEntry ((TAGS tags, VALUES values)) : transmet le paramètre VALUES et, facultativement, tags. Renvoie une valeur TEXTE du streamID de l'entrée nouvelle ou actualisée de la table de données. Met à jour une ligne si elle existe, sinon une ligne est ajoutée.
• AddOrUpdateDataTableEntries : ajoute ou met à jour plusieurs entrées de table de données. Met à jour une ligne si elle existe, sinon une ligne est ajoutée. Les clés primaires doivent correspondre pour que la mise à jour ait lieu.
• AssignDataTableEntries : remplace des entrées existantes de la table de données.
• DeleteDataTableEntry (STRING keyvalue) : supprime une entrée unique compte tenu de la valeur de clé. Le retour booléen indique si l'opération a réussi ou non.
|
|
La spécification d'une clé primaire est nécessaire pour la suppression d'une entrée.
|
• DeleteDataTableEntries : supprime plusieurs entrées correspondant à la première ligne de valeurs fournie dans le paramètre d'entrée de table d'informations. Par exemple, prenons une table de données possédant un champ nommé Int01 et trois entrées dont le champ Int01 est défini sur 10. Au moment de son exécution, DeleteDataTableEntries supprimera les trois entrées en question si 10 est spécifié comme critère de suppression.
|
|
Une erreur "Invalid Number of values provided to DeleteDataTableEntries in thingName" s'affiche si plusieurs lignes de valeurs sont fournies dans le paramètre d'entrée de table d'informations.
|
• FindDataTableEntries : effectue une recherche sur les index uniquement. Cette solution peut donc s'avérer plus rapide que le service QueryDataTableEntries.
|
|
Si plusieurs index sont définis dans la configuration de la table de données, l'index utilisé pour la recherche est pondéré en fonction des champs que vous avez désignés comme étant soumis aux recherches dans le paramètre Values que vous transmettez à FindDataTableEntries. Par exemple, supposons que vous avez quatre propriétés (ENTIER, BOOLEEN, CHAINE et TEXTE) et que vous avez créé deux index (un pour BOOLEEN et CHAINE, et un pour TEXTE). Si vous spécifiez une valeur à rechercher uniquement pour la propriété TEXTE, une pondération plus forte sera associée à cet index par rapport à l'index de BOOLEEN/CHAINE, car vous avez fourni pour cet index une valeur sur laquelle faire porter la recherche.
|
• GetDataTableEntries (NUMBER maxItems) : renvoie les dernières entrées jusqu'au nombre maximum d'éléments demandé.
• GetDataTableEntry (STRING keyvalue) : renvoie une table d'informations d'une ligne avec l'entrée correspondante.
• GetFieldNames : renvoie une liste de noms de champ associés à cette table de données.
• PurgeDataTableEntries : supprime toutes les entrées pour cette table de données. Le retour booléen indique si l'opération a réussi ou non.
• QueryDataTableEntries (NUMBER maxItems, STRING queryExpression, TAGS tags, VALUES query) : renvoie une table d'informations des enregistrements qui correspondent aux paramètres de la requête.
• SearchDataTableEntries : renvoie toutes les entrées de la table de données qui correspondent aux paramètres de requête. L'expression de recherche searchExpression est la clé de ce service ; elle inclut une recherche en texte intégral sur les champs CHAINE et TEXTE uniquement. Les filtres suivants peuvent être utilisés dans l'expression searchExpression : + (signe plus), sensibilité à la casse, ? (point d'interrogation), % (signe pourcentage), AND et OR.
• UpdateDataTableEntry (TAGS tags, VALUES values) : transmet le paramètre values et, facultativement, tags. Le retour booléen indique si l'opération a réussi ou non. Met à jour une ligne si elle existe.
Définition de la sensibilité à la casse dans les recherches en table de données
Vous pouvez définir la sensibilité à la casse dans les recherches en table de données en utilisant un filtre dans le paramètre query.
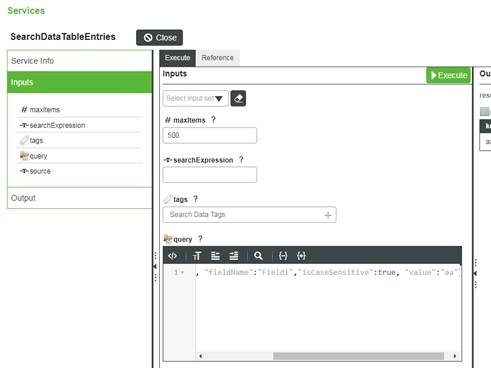
Par exemple, au moyen du service SearchDataTableEntries avec les entrées suivantes :

Vous pouvez définir un filtre pour le paramètre query afin que soient renvoyés des résultats sensibles à la casse. Par exemple :
{"filters":{"type":"EQ", "fieldName":"Field1","isCaseSensitive":true, "value":"AA"}}
Avec la requête ci-dessus, les résultats suivants s'affichent :

Dans un autre exemple avec le même service, en utilisant le filtre suivant dans le paramètre query :
{"filters":{"type":"EQ", "fieldName":"Field1","isCaseSensitive":true, "value":"aa"}}
La recherche renvoie les résultats suivants :
