|
Riga
|
Descrizione
|
|
1
|
Deviazione standard di Y.
|
|
2, 3, 4
|
R2, R2 adattato e R2 previsto.
|
|
5
|
PRESS (Prediction Error Sum of Squares), ovvero la somma dei quadrati degli errori di previsione, utile per i residui.
|
|
6
|
Statistica del test di Durbin-Watson per l'autocorrelazione.
|
|
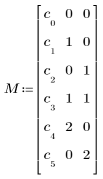
7
|
Matrice di coefficienti di regressione restituita da polyfitc.
|
|
8
|
Matrice di ANOVA per il modello di regressione con colonne identiche a quelle della tabella dei risultati restituiti da anova e con le righe indicate di seguito.
• Regressione - Subtotale, che viene quindi suddiviso in modo da indicare il dettaglio per ogni termine (esclusa l'intercetta).
• Residuo (errore) - Subtotale, che viene quindi suddiviso tra mancanza di fit (Lack of Fit) ed errore sperimentale puro.
• Totale per il modello di regressione.
|
|
9
|
Matrice di diagnostica che include le colonne indicate di seguito.
1. Numerazione di ogni esecuzione o punto dati.
2. Risultati osservati di ogni esecuzione o punto dati.
3. Risultato previsto dal modello di regressione esaminato.
4. Residuo - Differenza tra il risultato osservato e quello previsto.
5. Influenza - Distanza tra il risultato osservato e il punto al centro di tutti i risultati osservati.
6. Residuo rapportato agli studenti - Valore residuo diviso per la varianza basata sul risultato osservato.
7. R-studente - Valore residuo diviso per la varianza basata su un insieme di dati da cui è stato rimosso il risultato osservato.
8. Distanza di Cook - Misura dell'influenza del risultato osservato su tutti gli altri punti dati.
9. DFFITS - Differenza tra il risultato previsto da un modello di regressione basato su un insieme di dati che include il risultato osservato e il risultato previsto da un altro modello in cui il risultato osservato è stato rimosso.
|