Ranked Regression Method
The ranked regression method is based on the use of probability paper. The scales on probability paper are changed in such a manner that the cumulative distribution function associated with a given family of distributions becomes a straight line when plotted on the paper.
If F(t;θ) is a parametric family of cumulative distribution functions where is θ is the parameter vector and y = F(t;θ) can be written as:  and y is invertible, then the transformation readily changes y = F(t;θ) into a family of straight lines, Y = aX + b.
and y is invertible, then the transformation readily changes y = F(t;θ) into a family of straight lines, Y = aX + b.
and y is invertible, then the transformation readily changes y = F(t;θ) into a family of straight lines, Y = aX + b.For example, in the case of a two-parameter Weibull distribution:

Here:

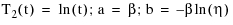
Estimation of parameters of the distribution can be made after fitting a straight line to the data. In the manual procedure, fitting the straight line can be done using personal judgment. To get accurate and consistent results, the regression method based on the least squares is generally used for fitting the data. This is primarily due to its good statistical properties (to judge the fitness) and its simplicity.
Regression can be done in two ways:
• X on Y, which minimizes the sum of the square of the residual variation in the X direction.
• Y on X, which minimizes the sum of the square of the residual variation in the Y direction.
For parameter estimation, most people prefer the X on Y line because the X variable (time-to-failure) is generally more scattered and erroneous than the Y variable.
Once the data points t1s (I = 1, 2, ..., n) are known, you must calculate the corresponding Yi and Xi values. The calculation of Xi is straightforward. The calculation of Yi is based on two methods:
• Mean ranks, which is based on the percentage of cumulative failures.
• Median ranks, which is based on the 50% confidence level.
The exact method of calculating median rank uses binomial distribution. Due to the complexity of the binomial distribution, Drs. Hazen and Benard proposed that approximate formulas be used to calculate median ranks. Because ranks are used in calculating the F(t), this method is known as the ranked regression method. Based on the types of ranks used, ranked regression methods can be classified as mean ranked regression, binomial ranked regression, Benard ranked regression, and Hazen ranked regression. Bernard and Hazen ranked regression methods are approximations to the binomial ranked regression method.
The default method of regression is X on Y. If regression is performed using Y on X, then these methods are called special ranked regression methods.