Managing the Execution of Info*Engine Tasks
Info*Engine tasks control the retrieval and manipulation of data. Tasks consist of the following:
• Invocation of other Info*Engine tasks using nested Info*Engine tags.
• Other custom tags, which can be either supplied as part of the product or customized.
• Embedded Java source code (scriptlets or method declarations).
Info*Engine tasks are always stored as text documents within the Info*Engine task root. There are several ways to execute tasks, including the following:
• A standard HTTP request through the IE servlet, made directly from a web browser.
• Processing a JMS Topic of Queue subscription.
• An external Simple Object Access Protocol (SOAP) request.
• Using Java source code, typically either from a custom SAK application or from a Windchill workflow expression robot.
The decisions about how and where to execute Info*Engine tasks depend on your system requirements. For example, if you have a dedicated environment where one system contains both your Info*Engine application and all of the required software components, and the tasks to execute do not require any complex processing, you may choose to execute your tasks from within JSP pages that are also used to display the results. In this case, the environment used could be similar to the following:
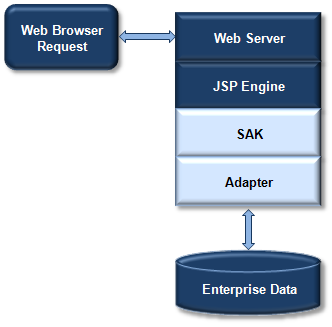
The JSP engine depicted in the diagram instantiates an instance of the SAK within the JVM of the JSP engine. The SAK is then used to process the Info*Engine custom tags. Some of the Info*Engine tags can execute webjects that extract data from enterprise systems through an adapter, while others can display the data. In this example, all of the webjects are contained in the same JSP page.
In a more complex environment where you have a large Java application that executes complex tasks, you can manage the tasks more efficiently by separating them into individual documents, rather than coding them directly in the application. When a task is contained in its own document, it is called a standalone task. For a standalone task, the following processing options are available:
• You can specify where you want a standalone task to execute, whether it is in the same JVM as the application or in the JVM of any Info*Engine server that is part of your environment.
• You can specify how you want to execute standalone tasks that do not execute in the same JVM as the application. There are three ways to execute these standalone tasks:
◦ Requesting, through a TCP/IP connection, that the task executes in a specific Info*Engine server. Each Info*Engine server listens for task requests and executes them upon arrival.
◦ Implementing a specific event that executes tasks. Establishing events through an Info*Engine Web Event Service allows you to execute tasks based on specific actions that can occur in your environment.
◦ Queuing a task for execution. After you queue a task, you can disconnect from your application. Any results are queued for later retrieval either by you or others. By queuing a task, you can also guarantee that the task will be completed, even if it is interrupted due to a system problem.
By performing the basic Windchill installation, the Info*Engine server is set up to receive task requests. To use either queues or events for executing tasks, you must install and configure additional Message-Oriented Middleware (MOM) software and then update your Info*Engine configuration.