CSV ファイルからの分類構造のインポート
分類構造をインポートするには、その分類構造が XML ファイルで示されている必要があります。インポートする前に XML ファイルを修正できますが、構造が複雑な場合は簡単にはいきません。
代わりに、CSV ファイルを管理するほうがずっと簡単です。構造をインポートする準備ができたときに、CSVToXMLGenerator ユーティリティを使用して CSV ファイルをインポート可能な XML ファイルに変換できます。
|
|
分類構造を最初に作成する場合は、このユーティリティを使用することをお勧めします。既存の構造の更新には使用しないでください。CSV ファイルに表示されていない既存の構造のデータはすべて上書きされ、その結果として除去されます。
|
CSV ファイルを XML に変換するには、Windchill シェルで次のコマンドを実行します。
Windchill com.ptc.windchill.csm.csvtoxml.CSVToXMLGenerator <CSV ファイルへのパス> -verbose
ここで、
• <CSV ファイルへのパス> はローカルマシンの CSV ファイルへのパスです。
• verbose パラメータはオプションです。デバッグを目的として使用します。
XML ファイルが、CSV ファイルと同じ名前で同じ場所に生成されます。
開始する前に
• CSVToXMLGenerator ユーティリティは、Windchill サーバーが動作していなくても使用できます。
• インポートされた CSV ファイルは一意な形式でなければなりません。これは、「分類ツリー」テーブルから使用できる「CSV 形式でエクスポート」操作を使用して生成された CSV ファイルと同じ形式ではありません。
• 生成された XML ファイルを読み込む前に、Windchill には次のものがすでに存在していなければなりません (エクスポートされた ZIP ファイルまたは JAR ファイルをインポートする場合には当てはまりません)。
◦ グローバル列挙
◦ 再利用可能な属性
◦ 測定数量
• 生成された XML ファイルをインポートするには、ZIP ファイルに圧縮します。分類ツリーで > の順に選択します。
インポートエラーとサポートされる値
ファイルを Windchill にインポートすると、データの検証が発生します。XML ファイルに無効なデータまたは値が含まれている場合、インポート操作中にエラーが表示されます。
CSV ファイルのほうが扱いやすいですが、CSVToXMLGenerator ユーティリティで受け入れ可能な形式にはいくつかの制限があります。たとえば、回路図または画像はインポートできません。また、自動ネーミング規則を指定することもできません。
属性または制約が下記のテーブルにリストされていない場合、それらはサポートされておらず、インポート中にエラーが発生します。
CSV のフォーマット規則
• 単一の値にコンマが含まれる場合は、二重引用符で囲まなければなりません。例:
香港, ベルリン, "ニューヨーク, NY", ロンドン
• 二重引用符には二重引用符を重ねてエスケープ処理します。例:
""駆動システム"" カタログで使用可能な部品
ノードと属性で共有される列
ノードの情報または属性の情報を含む列が 7 つあります。これらの列は、次のフォーマットを使用します。
ノード/属性
スラッシュの前のタイトルは分類ノードを示し、スラッシュの後のタイトルは分類属性を示します。
|
列名
|
ノード値
|
属性値
|
||
|---|---|---|---|---|
|
Node/Attribute
|
この列では、分類ノードを含む行と分類属性を含む行が識別されます。
次のいずれかの値を入力します。
• ノード
• 属性
|
|||
|
ParentIntName/NodeIntName
|
親ノードの内部名。
|
属性が定義されているノードの内部名。
|
||
|
NodeIntName/AttributeIntName
|
ノードの内部名。
|
属性の内部名。
|
||
|
DisplayName/DisplayName
|
ノードの表示名。
|
属性の表示名。
|
||
|
Description/IBAName
|
ノードの「説明」フィールドに入力する値。
|
再利用可能な属性の名前。
|
||
|
Keywords/DataType
|
ノードの「キーワード」フィールドに入力する値。
|
属性のデータタイプ。
次の値を使用できます。
wt.units.FloatingPointWithUnits
java.lang.Boolean
java.sql.Timestamp
java.lang.Long
java.lang.String
com.ptc.core.meta.common.Hyperlink
com.ptc.core.meta.common.FloatingPoint
|
||
|
名前空間
|
名前空間の名前セット
|
|||
|
IsInstantiable/Description
|
ノードの「インスタンス化」フィールドに入力する値。
次の値を使用できます。
TRUE
FALSE
|
属性の「説明」フィールドに入力する値。
|
||
たとえば、"Node" 行に次の値が設定された CSV ファイルを作成したとします。

CSV ファイル内の列の配置は上記のスクリーンショットに示されているものと同じでなければなりません。 |
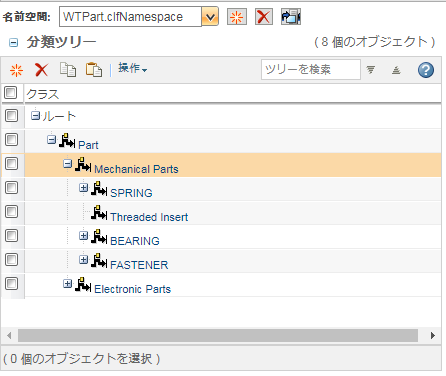
CSV を XML に変換してインポートした後は、構造は次のようになります。
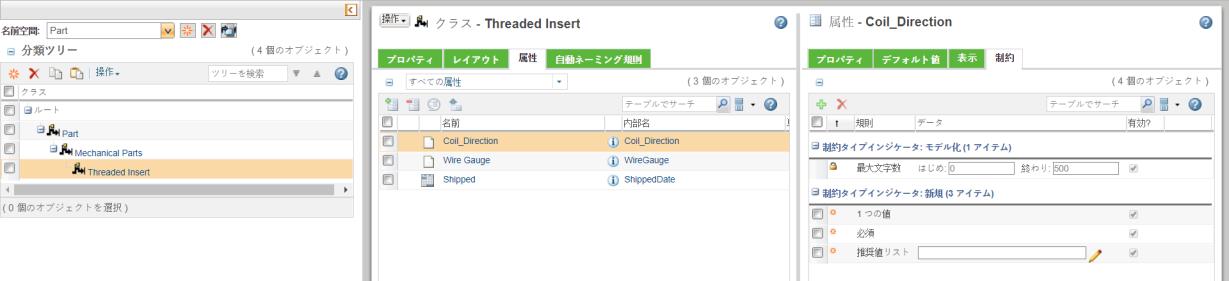
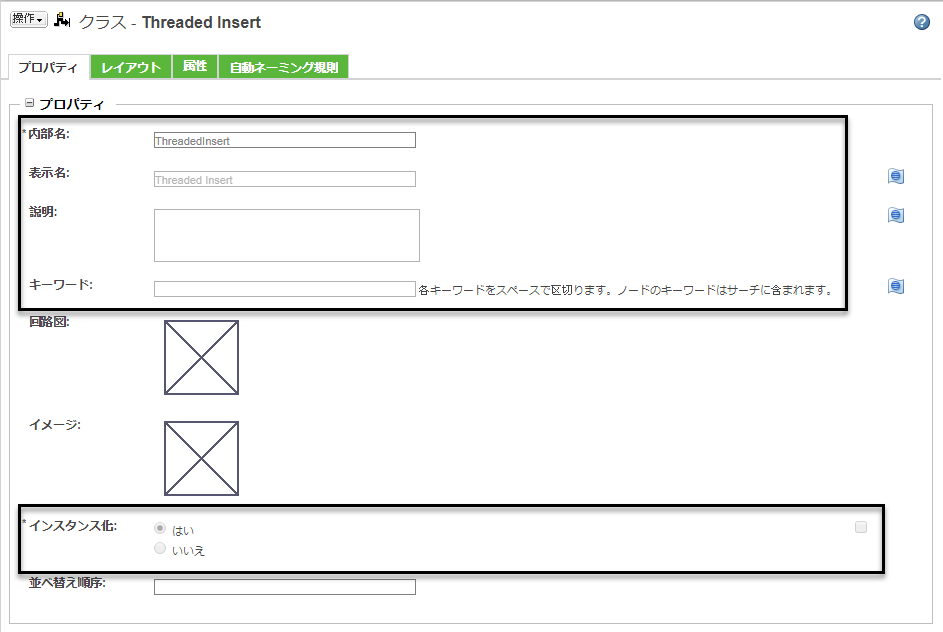
"Threaded Insert" ノードには次の値が定義されています。
属性列
次の列は "Attribute" 行にのみ適用されます。
列名 | 可能な値 | ||
|---|---|---|---|
DefaultValue | 属性のデフォルト値。 デフォルト値が複数ある場合、コンマを使用してリストを区切ります。例: 0.0 m, 1.5 m http://google.com(Google), http://ptc.com(PTC) | ||
IsSingleValued | 属性が単一値属性かどうかを指定します。 可能な値は次のとおりです。 「真」 「偽」 | ||
IsRequired | 属性が必須かどうかを指定します。 可能な値は次のとおりです。 「真」 「偽」 | ||
StringLength | 文字列値に対して長さ制約を指定します。 フォーマットは、[下限,上限] です。 例: [2,5] - 文字列は 2 文字から 5 文字まででなければなりません。 [NULL,50] - 文字列は 50 文字を超えてはなりません。 [10,NULL] - 文字列は最低 10 文字でなければなりません。 | ||
Lowercase | 大文字を小文字に変換します。 可能な値は次のとおりです。 「真」 「偽」 | ||
Uppercase | 小文字を大文字に変換します。 可能な値は次のとおりです。 「真」 「偽」 | ||
LegalValueList | 可能な値のリスト。 パイプ文字 ( | ) を使用して値を区切ります。例: 1.0 m|1.5 m|2.0 m 銅|アルミ|鉄 | ||
EnumeratedList | 列挙値リスト。ローカル列挙値リストまたはグローバル列挙値リストを設定できます。 ローカル列挙の制約には、次のフォーマットを使用します。 LOCAL##<並べ替えタイプ>##<内部名>##<表示名>~~<内部名>##<表示名> ここで、 • <並べ替えタイプ> - 並べ替えタイプの値は Automatic_Sort または Manual_Sort です。 • <内部名>##<表示名> - 列挙エントリの内部名と表示名を識別します。 • ~~ - 複数のエントリは 2 つのチルド文字を使用して区切ります。 例: LOCAL##Manual_Sort##red1##Light Red~~red2##Dark Red~~green1##Light Green グローバル列挙の制約には、次のフォーマットを使用します。 GLOBAL##<列挙>##<親列挙>##<組織>##<組織名>##/<ドメイン> ここで、 • <列挙> - 列挙の内部名 • <親列挙> - 列挙がサブ列挙の場合、親列挙の内部名を指定します。列挙に親列挙がない場合は、このフィールドを空白のままにします。 • <組織> - 列挙の「オーナー組織」の値。 • <組織名> - 列挙を保持するオーガナイザーの内部名。 • /<ドメイン> - 列挙の「ドメイン」の値。 例: GLOBAL##Countries##LocaleCodes##Site##Org_Locales##/System GLOBAL##LocaleCodes####Site##Org_Locales##/System
|
たとえば、"属性" 列に次の値を含む CSV ファイルを作成します。

CSV ファイル内の列の配置は上記のスクリーンショットに示されているものと同じでなければなりません。 |
"スレッド挿入" ノードには次の属性が定義されます。