Setting Up Connections Through Adapters
Adapters provide a connection between the Info*Engine server and information systems. One side of the adapter communicates with the Info*Engine server and the other side communicates with the information system. The adapter translates Info*Engine server requests into information system requests.
Info*Engine provides two types of adapters:
• Native adapters are implemented in the Java language and conform to the formal Info*Engine interface specification. For example, the JDBC and JNDI adapters are native adapters.
• Non-native adapters are implemented in a non-Java language or do not conform to the formal Info*Engine interface specification. Because the implementation is different from Info*Engine, you must also define a gateway for each non-native adapter you install. Gateways translate Info*Engine requests so the adapters can process them. After an adapter receives a request, the adapter sends it to the associated database or data repository. The adapter also returns any information obtained from the data repository to the gateway where it is translated and passed back to the Info*Engine server.
The adapters you use are determined by the information systems from which you want to retrieve information. Info*Engine provides a unique adapter for each information system.
Native adapters can be installed as follows:
• Residing in the same Java Virtual Machine as the Info*Engine webject that accesses the adapter (known as in-process adapters).
• Distributed in their own Java Virtual Machine on the same hardware system or on remote hardware systems (known as out-of-process adapters).
How to install native adapters is determined by your site:
• Gateways usually reside in the same Java Virtual Machine as the calling webject since the code for gateways is installed as part of Info*Engine.
• Non-native adapters are always distributed in their own environment and are run as out-of-process adapters.
The following sections expand on the installation options.
Using In-Process Adapters and Gateways
In-process adapters and gateways are installed and run in the same Java Virtual Machine (JVM) as the calling webject. Only native adapters and gateways can be configured to run in the same JVM as the calling webject. The SAK determines which classes are required when processing webjects for an in-process adapter or gateway, and instantiates the classes in the JVM. Therefore, the communication between the webject and the adapter or gateway is very efficient.
Configuring in-process adapters and gateways minimizes communication delays and resource usage; however, the total resource usage of the machine hosting the Info*Engine code may be increased because of the additional load of running the adapter or gateway.
When an adapter is configured to be an in-process adapter, the adapter classes can be instantiated by any SAK that executes adapter webjects. The following diagram shows adapter classes residing in the JVM of a custom Java application, the web server, and the Info*Engine server:
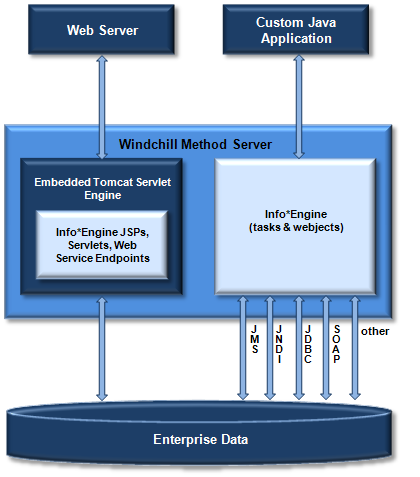
As shown in the diagram, no external communication is needed between the SAK and the adapter when the adapter is in the same process.
Running in-process native adapters and gateways is generally the preferred configuration if the resource usage on a single system is not excessive.
Using Out-of-Process Adapters and Gateways
Distributing adapters across multiple hardware systems reduces the overall resource usage on the machine hosting the Info*Engine code; however, it does introduce some delay and resource usage associated with using a TCP/IP connection for communicating between Info*Engine components and each adapter.
The following diagram shows the communication lines that are used when three adapters and one gateway are distributed.
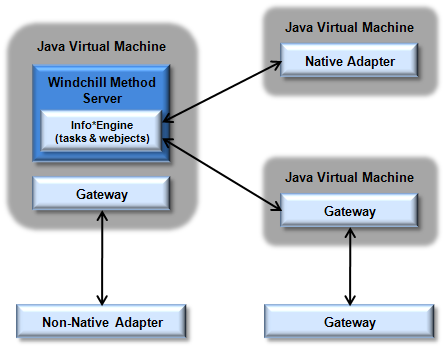
Distributed native adapters and gateways are installed and run in their own Java Virtual Machine (JVM). These virtual machines can be on the same hardware system as the Info*Engine server or on a different hardware system. Non-native adapters can only be configured as out-of-process adapters, and they always run as separate processes. Although gateways for non-native adapters are typically configured as in-process gateways to minimize the communication delays, they do not need to be in the same process.
The deployment of distributed adapters at your site may be determined by a company policy that requires the adapter to be located near the application it accesses, or it may be based on administrative reasons. One reason for running a native adapter in its own Java Virtual Machine could be to better manage the resource usage of the virtual machine.