The Data Loading Process
The data loading process is fluid and changes depending on the data requirements. The flow chart below shows a typical data loading process beginning with analysis of the legacy system, continuing with data cleansing and extraction of a sample data, and finishing with loading data on to the live system. The steps in this process are color coded to show the relationship between the customer and PTC’s Global Service representatives.
|
|
Prior to loading data:
• It is strongly recommended that PTC review the raw data prior to loading. This ensures that resource bundles are properly prepared and data is of expected format and length. When possible, data should be reviewed and evaluated prior to engagement activities. This also allows for proper time and resource estimates to be created.
• If Windchill Index Search is installed, disable indexing using the property wt.index.enabled=false. This pauses indexing and disables indexed keyword searches. Once the bulk loading operation is complete, re-enable indexing and use the Bulk Index Tool to populate your indexes with the new data.
|
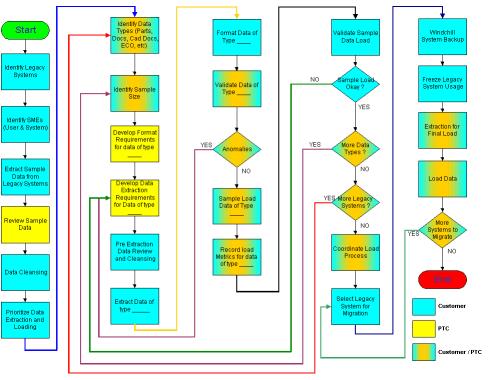
In this process, there is a built-in review process before the data is loaded. For example, a data file of parts can be examined to produce a unique list of part types. This list should be compared against the PartTypeRB.rbInfo file. Similarly, a unique list of part quantities can be compared to the QuantityUnitRB.rbInfo file.
|
|
Data lengths should be examined as well. Verifying that the Title field on the Document Data load file is fewer than the maximum of 60 characters is one example of checking data lengths.
|
The review process and data cleansing typically require the use of a tool to examine the data. The following section reviews the tools options for data cleansing.