JADK Structures and APIs
The JADK package provides you with a rich set of APIs that you can use to write your own adapter webjects. The adapter written with JADK conforms to the architecture requirements with
Info*Engine. Depending on whether you would like to invoke the adapter with the JADK main class or with
Info*Engine, you can run the adapter either in co-resident mode or standalone mode. For more information about running an adapter with
Info*Engine in either of these modes, see the section
Info*Engine User’s Guide.
Adapters written with JADK can take advantage of existing APIs provided by JADK RequestContext class. For example, RequestContext enables you to easily input and output data or streams between Info*Engine and the back-end system you use to develop your adapter. In the case of data input and output, a data structure is provided to assist your input and output data with a group. This data structure is described in the section Input and Output with Data in this topic.
User-Defined Sections
An adapter written with JADK includes some comments inside JADK code that indicate user-defined sections. These comments are there to remind you to add your custom code when writing your adapter. For example, if you write the adapter webject by copying the sample program to IeQueryObjects.java, you can fill in the user-defined section inside the init and processWebject methods.
Input and Output with Data
JADK provides data structures that enable you to quickly read or write metadata from a group-in or to a group-out without the internal structure of the data.
There are two common data structures used by the JADK to provide you metadata input and output. These structures can be used to store a table or your metadata pairs:
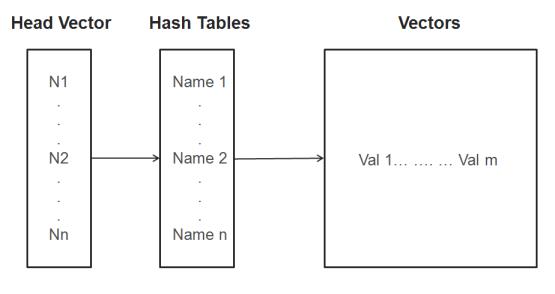
Vector-Hashtable-Vector
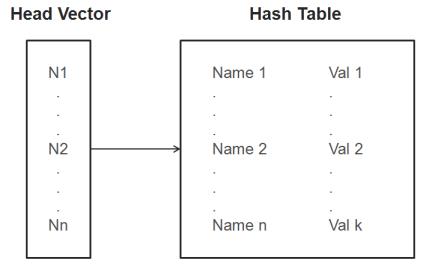
Vector-Hashtable
The first vector denotes the head vector that can store one or more nodes. A node is equivalent to a record or a row with one or more attributes, and is represented by a hashtable that contains a set of keys and corresponding values. In the first internal structure, each field of the record or row can contain one or more sub values. These values are stored inside the tail vector that corresponds the key within the hashtable. The second internal structure is more commonly used, where only one value is associated with each key in a record or a row.
To use the JADK to read data from an input group or send data to an output group, convert your data into these common internal structures and then call the appropriate RequestContext APIs for input/output data. For example, if you plan to send data to Info*Engine with the vector-hashtable-vector structure, you must use one of the writeGroupOut methods in RequestContext. You can use the writeGroupOut2 method if you use the second internal structure for your output.
If you only input or output one node or some metadata with a group, you do not need a head vector class. There are APIs that only work with the hashtables for input and output. For more information, see the RequestContext API Java documentation included with your JADK package.
You do not have to use the internal data structures provided with JADK if you understand the group structure well and would like to directly read and write data with the group-in and group-out. The new JADK allows you to create a group and directly add or remove them from the Virtual Database (VDB) created by Info*Engine for your data manipulation. PTC recommends using the internal structures provided rather than manipulating a group.
Input and Output with Streams
You cannot use group-in and group-out to handle binary data such as those that represent BLOB or bulk streams. Your adapter written with the JADK can read and write these types of data with the proper use of the APIs defined with the RequestContext class.
The writeBlobStream method takes an input stream from your adapter and writes it back to the Info*Engine output stream, thereby sending it to your web browser.
The readBlobStream method reads a BLOB or a file from the Info*Engine input stream and writes it into the adapter specific output stream that you passed.