データ読み込みプロセス
データ読み込みプロセスは流動的で、データの要件によって変化します。以下のフローチャートは、一般的なデータ読み込みプロセスを示しています。このプロセスではまずレガシーシステムを分析し、次にデータのクレンジングとサンプルデータの抽出を行い、最後にデータを稼働中のシステムに読み込みます。このプロセスの手順は色分けされており、顧客と PTC Global Service 担当者との関係が示されています。
|
|
データを読み込む前に、次を行います。
• 生のデータは読み込み前に必ず確認してください。それによって、リソースバンドルが適切に準備され、データが予期されたフォーマットと長さを持っていることが確実になります。可能なかぎり、アクティビティを実施する前にデータを見直して評価してください。これも、時間とリソースを正確に見積もる上で役立ちます。
• Windchill インデックスサーチがインストールされている場合は、プロパティ wt.index.enabled=false を使用してインデックシングを無効にします。これにより、インデックシングが一時停止し、キーワードのインデックスサーチが無効になります。バルクロード操作が完了した後で、インデックシングを再度有効にして、バルクインデックシングツールを使用してインデックスに新しいデータを取り込みます。
|
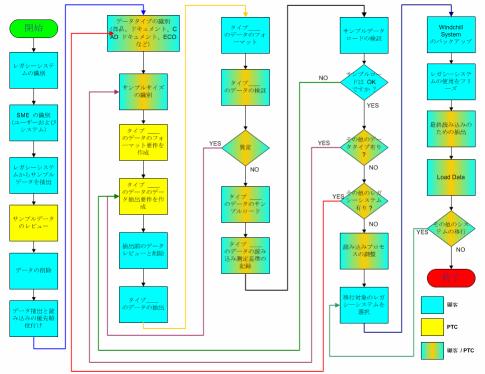
このプロセスには、データの読み込みの前に、レビュープロセスが組み込まれています。たとえば、部品のデータファイルを確認し、部品タイプの一意のリストを作成できます。このリストは次に PartTypeRB.rbInfo ファイルと比較する必要があります。同様に、部品数量の一意のリストは QuantityUnitRB.rbInfo ファイルと比較します。
|
|
データ長も確認が必要です。たとえばデータ長のチェックでは、ドキュメントデータロードファイルの「タイトル」フィールドが 60 文字以下であるかどうかを確認します。
|
確認プロセスとデータクレンジングでは通常、データを検査するためのツールが必要です。以下のセクションでは、データクレンジングのためのツールオプションについて見ていきます。