Data Sources
It’s an infrastructure for holding the data and streaming the data to the client. It will enable faster page loads as well as the potential for asynchronous server processing of results. The basic strategy is to return large result sets to clients in chunks, along with an ID that can be used to get more chunks. From the UI perspective it looks like the data is streaming into the client. This approach is different from DB paging, where we persist the big result set in the database. With DataSources, the result lives in memory only for as long as it takes the client to request it in chunks. In addition, there will be support for the server to add chunks to the datasource in a separate thread, so one can request the datasource and spin off a thread to work on getting data for it, without the client waiting.
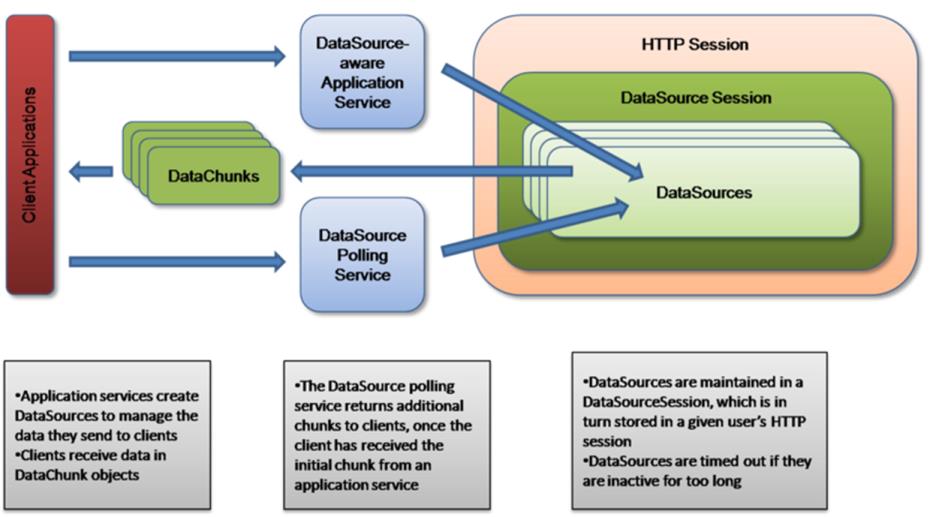
Some of the benefits of using DataSources are
• Display data without overly consuming client- and server-side resources.
• Allow users to interact with the page while data is loading.
• Improve perceived performance.
• Provide messaging and feedback while data is loading.
Modes of Data Sources
Synchronous: This is useful if you have all the data that need to be send to client with you already and want to put the data in DataSource so that it can be send to the clients in chunks. The DataSource session takes in a list of objects that you want sent to the client and returns you a DataChunk object, which contains the first chunk of data to be send to the client. If the List of data could fit in one chunk, then the session doesn't even create a DataSource, it just returns you the chunk. Otherwise a DataSource is created with the data, which can be polled later for additional chunks. The DataSource will be closed so that no more data can be added.
Asynchronous: In this case, you haven't got your data yet. You want to submit a task to get the data in a background thread and have the data returned to the client later. We leverage the capabilities of Executor framework provided by Java.(for more details refer JavaDoc of Executor) To create an asynchronous DataSource, the DataSource session takes a DataSourceTask which will be run by in a background thread sometime in the future. It returns a DataSourceFuture object, so that you have a way to access the DataSource information.
Disabled: Not DataSource enabled
DataSources with Data Acquisition
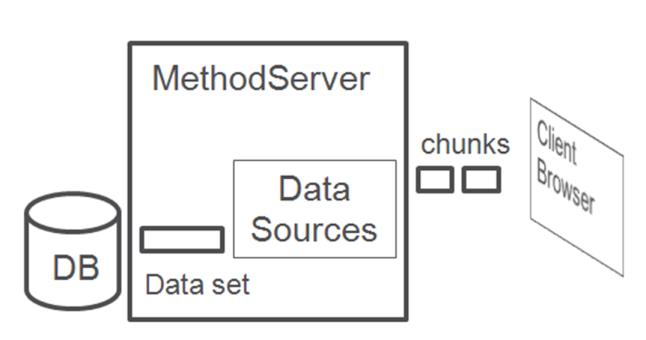
Synchronous data sources with Synchronous data acquisition: Uses synchronous data acquisition (all data comes from the database in one chunk) and streams chunks to the client. No blank chunk is sent, so the component is not rendered until the first data chunk is received. Currently we don’t support this for Tree components.
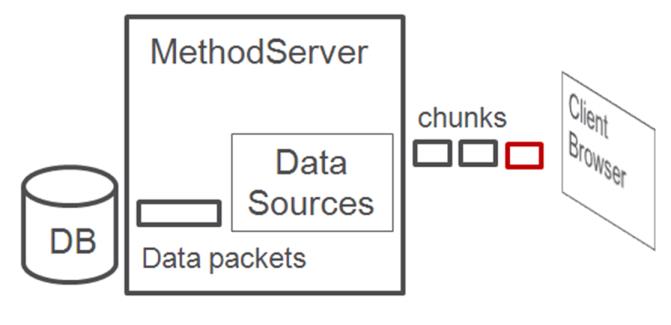
Asynchronous data sources with Synchronous data acquisition: Uses synchronous data acquisition (all data comes from the database in one chunk) and streams chunks to the client. The first chunk sent to the client contains no table data but enables the table to be rendered before a full data chunk is available. This gives the user control of the table and some of its actions sooner. The data chunks then stream in behind the blank chunk as they are processed.
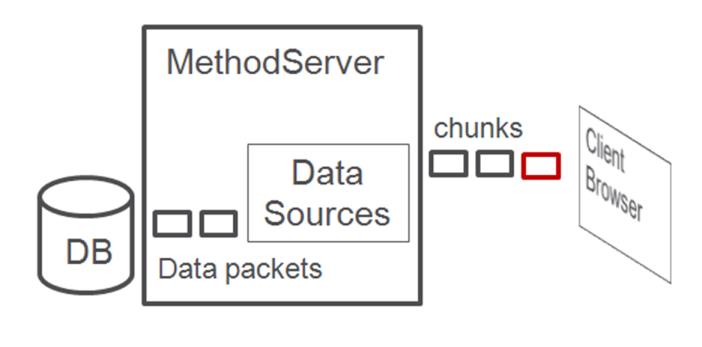
Asynchronous data sources with Asynchronous data acquisition: Uses asynchronous data acquisition (data is obtained from the database in chunks) and streams chunks to the client. The first chunk sent to the client contains no table data but enables the table to be rendered before a full data chunk is available. This gives the user control of the table and some of its actions sooner. The data chunks then stream in behind the blank chunk as they are processed. In this case, we have the potential to see chunks of data rendered in the client while data is still being acquired from the database.
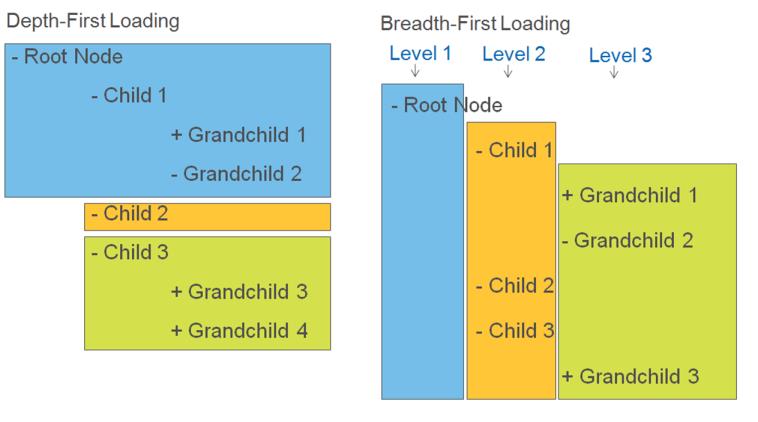
There is change in loading behavior in case of Trees. In Windchill 9.x, we had followed the depth first loading approach where by each node was expanded till its leaf node, before starting to expand it sibling. In Windchill 10, with DataSource, we have moved the Breadth first loading approach. Nodes are loaded per level.
Monitoring Data Sources
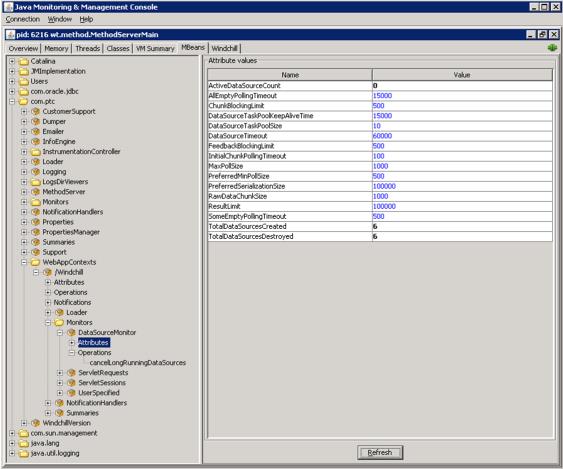
DataSourceMonitor MBean can be used to monitor and configure various properties. To find the monitor
• From windchill shell, run “jconsole”
• Select MethodServerMain
• Select MBeans tab
• MBean located at com.ptc>WebAppContexts>${WEBAPP_NAME}>Monitors>DataSourceMonitor
MBean monitoring
Parameter | Description |
|---|---|
ActiveDataSourceCount | The number of datasources that currently are active in all user sessions |
TotalDataSourcesCreated | The total number of DataSources that have been created for all user sessions |
TotalDataSourcesDestroyed | The total number of DataSources that have been destroyed for all user sessions |
MBean operations
Parameter | Description |
|---|---|
cancelLongRunningDataSources | Cancel any datasources that have been running for at least the given amount of milliseconds, in all user sessions. This will cancel both active and inactive DataSources |
MBean configuration
Parameter | Description |
|---|---|
AllEmptyPollingTimeout | The timeout in milliseconds to wait for data chunks when the client polls for chunks and none of the ids it asked for have chunks available |
ChunkBlockingLimit | Controls the number of chunks a DataSource can hold before it blocks the addition of more items until something polls it or it times out. The actual number of items this resolves to is ChunkBlockingLimit*MaxChunkSize. |
DataSourceTaskPoolKeepAliveTime | The amount of time in milliseconds to keep idle threads alive in the DataSource task pool |
DataSourceTaskPoolSize | The maximum number of threads allowed in the DataSource task pool |
DataSourceTimeout | The amount of time in milliseconds to keep idle DataSources alive |
FeedbackBlockingLimit | The number of feedback items a DataSource can hold before it blocks the addition of more feedback until something polls it or it times out |
InitialChunkPollingTimeout | The amount of time in milliseconds to wait to for the initial chunk of data to be available, when using asynchronous datasources. This enables components to try and display some data in the table on initial rendering if possible |
MaxPollSize | The maximum size of data that is returned by a DataSource for each poll. |
PreferredMinPollSize | The minimum size of data for a poll. This is used when polling asynchronous datasources, to allow the server to decide whether to wait for more data or not |
PreferredSerializationSize | The preferred size in bytes of the total response to a polling request. If the initial chunks do not reach this size limit, then additional chunks are added until they are over the limit. This property is not currently used. |
ResultLimit | The total number of items that can be added to a DataSource before it fails. |
SomeEmptyPollingTimeout | The timeout in milliseconds to wait for data chunks when the client polls for chunks and some of the ids it asked for have chunks available, but not all of them |
TreeChildNodeFetchTimeout | The timeout in miliseconds to wait for child data for the tree. The OOTB value is 180000 ms and can be increased to avoid time out errors. |
Persisting the updated MBean Configuration values
It is possible to persist the updated configuration values of "DataSourceMonotor" MBean in the XML.
• Open Jconsole and change any of the configurable value of "DataSourceMonitor" MBean.
• Click on the "DataSourceMonitor" MBean. From the MBeanInfo, copy the "ObjectName".
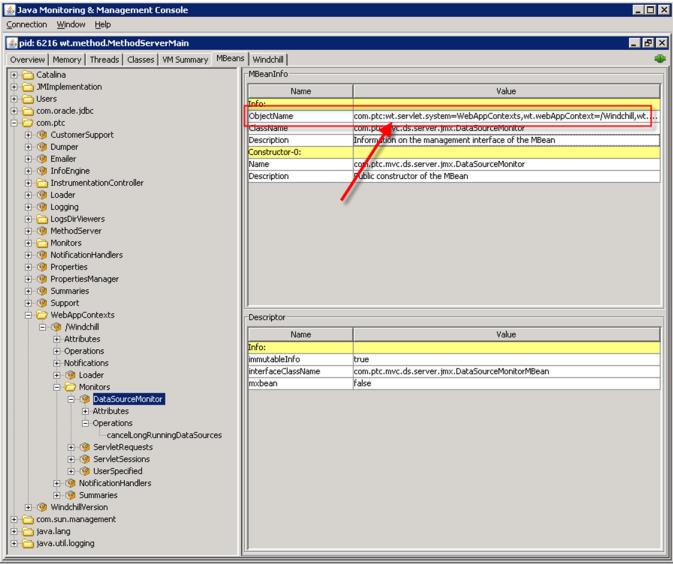
• Open the Loader MBean com.ptc > WebAppContexts >${WEBAPP_NAME}
• Got to its "Operation invocation" tab.
• Paste the "ObjectName" as a parameter for "addInjectionTargetMBean" method and click on the "addInjectionTargetMBean" button.
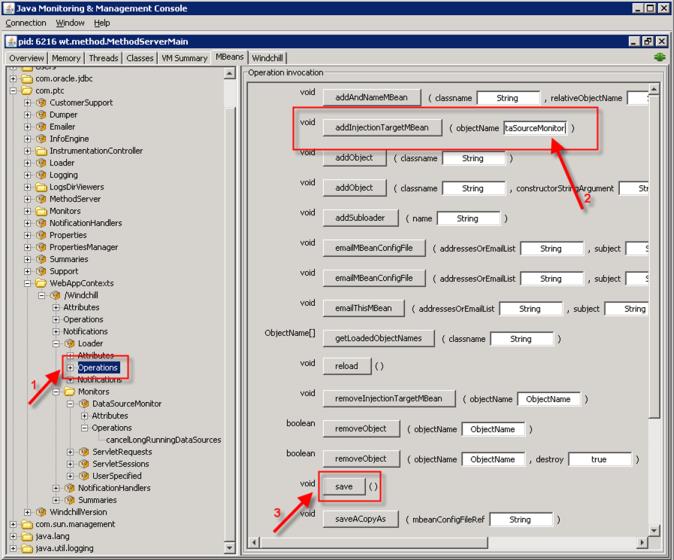
• Now click the "Save" button. The changed value of the "DataSourceMonitor" MBean will get persisted in the <WTHome>/codebase/WEB-INF/wtWebAppMBeans.xml file. On any subsequent server restart, the last saved value will show up the in "DataSourceMonitor" MBean.
• Configurable properties can be reverted back to the default values by invoking "removeInjectionTargetMBean" method with the "ObjectName", followed by a “save” operation.
Performance concerns
• Threads Per Components
In addition to the MBean properties to adjust different sizes and timeouts, the property numberOfThreadsPerComponent can have an effect on overall performance of a component. This property is used to modify the maximum number of threads allowed by any component to process data out of the database through the Data Utilities. These threads process data of size of the RawDataChunkSize MBean value and are short lived. Increasing the number will not likely help further because the data coming from the database will not be fast enough to need more threads. In most of the cases, the maximum count of threads running concurrently will be two. Given below is an example of the property showing default value: com.ptc.core.components.factory.dataUtilities.numberOfThreadsPerComponent=3
• WAN clients and MaxPollSize
For WAN clients, the maxPollSize attribute might work a little better set to a higher number. LAN clients will work faster with a smaller value because there is a smaller latency penalty for making requests. A balanced value of 500 should work well in both scenarios. The client browser should be using multiple Ajax requests to download the data. This has been limited to three concurrent requests as more requests do not improve download speeds because the data is not available any faster. This property is not configurable (PTC.jca.DataSourceRegistry.MAX_REQUESTS) at this point.
Parent topic