WBM 워크플로 프로세스와 단계
이 항목에서는 Windchill Bulk Migrator(WBM) 워크플로 프로세스 및 다양한 WBM 단계에 대해 설명합니다.
WBM 워크플로 프로세스
다음 워크플로 다이어그램은 WBM 마이그레이션의 실행을 보여줍니다.
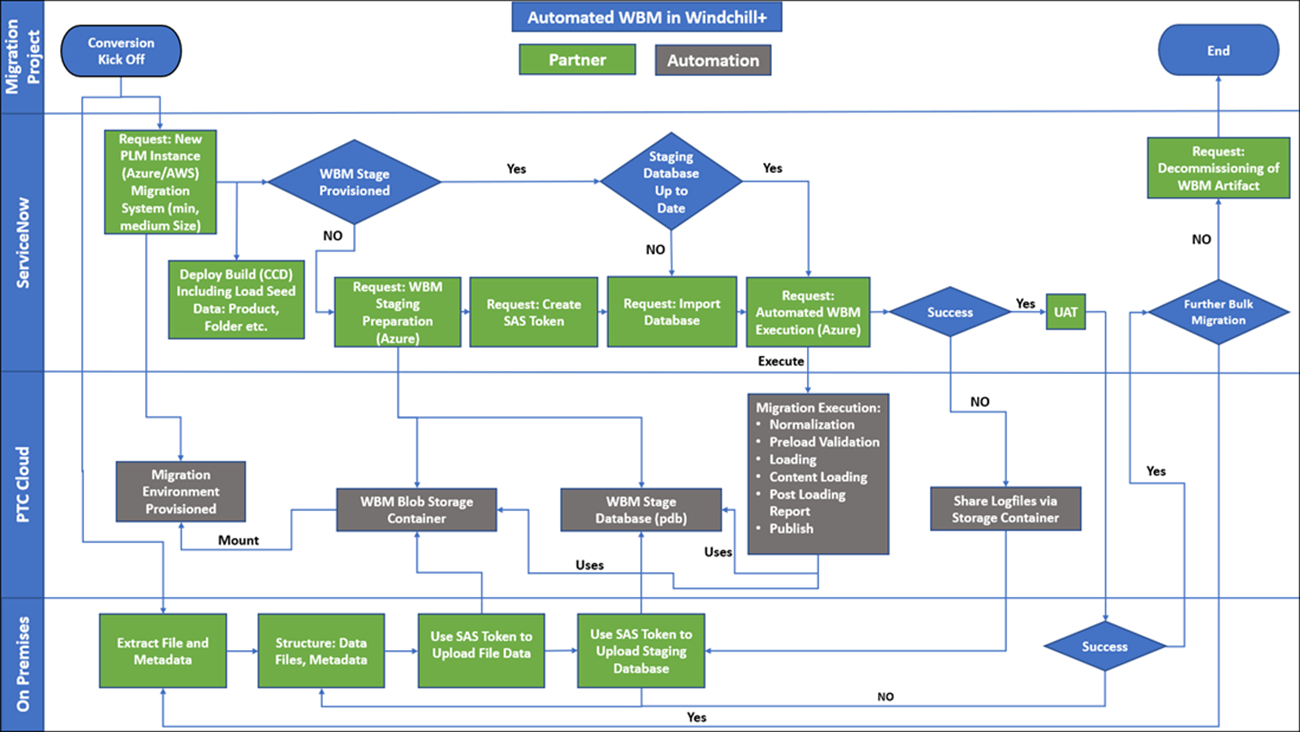
온프레미스 준비 데이터베이스
데이터 마이그레이션은 일반적으로 반복 프로세스입니다. 첫 번째 단계에서는 일반적으로 소스 시스템에서 파일 및 메타데이터를 추출합니다. 마이그레이션 메타데이터를 구조화하려면 준비 데이터베이스가 필요합니다. 여러 데이터 변환을 제거하기 위해 온프레미스 준비 데이터베이스가 사용된다고 가정합니다. 자세한 내용은 https://support.ptc.com을 참조하십시오.
• Windchill 버전 요구 사항에 따라 데이터베이스는 Oracle이어야 합니다. • 데이터베이스 구조는 Windchill WBM 준비 데이터베이스 요구 사항을 준수해야 합니다. |
Windchill WBM 준비 데이터베이스 작성
이 절차에서는 기존 개발 환경이 있다고 가정합니다.
WBM이 시스템에 설치되어 있는지 확인합니다. |
1. 개발 환경에서 WT_HOME 디렉터리부터 시작합니다.
2. 다음 명령을 실행합니다.
WT_HOME/bin/wbmgen
이렇게 하면 모듈 세트 및 Windchill 구성에 따라 준비 구조가 작성되고 준비됩니다.
3. Oracle 데이터베이스에서 새 스키마 사용자를 작성하려면 create_user.sql 스크립트를 사용합니다. 다음 단계를 따릅니다.
a. DBA 역할을 가진 사용자 또는 SYSTEM 사용자 등 관리 권한이 있는 계정을 사용하여 Oracle 데이터베이스에 로그인합니다.
b. 다음 스크립트를 실행하여 준비 사용자를 만듭니다.
@db/sql(3)/create_user.sql
c. 이전에 작성된 준비 사용자를 사용하여 Oracle 데이터베이스에 로그인합니다.
d. 다음 스크립트를 실행하여 준비 스키마를 작성합니다.
@db/sql(3)/wbm/create_staging_schema.sql
e. 다음 스크립트를 실행하여 감사 테이블을 작성합니다.
@@db/sql(3)/wbm/create_audit_schema.sql
자세한 내용은 WBM Install and Usage Guide의 Configuring the Loading Infrastructure and Object loaders 항목을 참조하십시오.
Oracle Data Pump Export(expdp)를 통해 데이터베이스 덤프 내보내기
expdp(export data pump) 및 impdpm(import data pump)라고도 하는 Oracle Data Pump는 고속 데이터 및 메타데이터 작업을 수행하기 위해 Oracle 데이터베이스에서 제공하는 명령줄 유틸리티 세트입니다. 이러한 유틸리티는 데이터 내보내기, 데이터 가져오기 및 데이터 마이그레이션과 같은 작업에 사용됩니다. 자세한 내용은 다음을 참조하십시오.Azure Storage 계정
다음 단원에서는 Oracle Data Pump를 사용하여 덤프 파일을 생성하고 expdp를 사용하여 데이터를 내보내는 방법에 대해 설명합니다.
Oracle Data Pump를 사용한 덤프 파일 생성
다음 단계에 따라 Oracle Data Pump를 사용하여 덤프 파일을 생성합니다.
덤프는 Windchill 시스템에서 추출됩니다. 추출 프로세스 중 Windchill이 종료되었는지 확인합니다. |
1. Windows 또는 Linux에서 Windchill 셸이나 명령 프롬프트를 열고 다음 명령을 실행하여 시스템에 데이터 펌프 파일을 저장할 디렉터리를 만듭니다.
mkdir <directory name>
예를 들면 다음과 같습니다.
mkdir D:\datapump
Windchill 데이터베이스 사용자 스키마를 저장할 충분한 공간이 있는지 확인합니다. |
2. Windchill 셸 또는 명령 프롬프트에서 sqlplus에 로그인하고 다음 명령을 실행하여 Oracle 논리적 디렉터리 객체를 만듭니다.
sql> create directory EXP_DIR as '<path to operating system directory created previous step>';
이 객체는 이전 단계에서 생성된 물리적 디렉터리를 가리켜야 합니다. |
예를 들면 다음과 같습니다.
sql> create directory EXP_DIR as 'D:\datapump';
3. 동일한 sqlplus 세션에서 다음 명령을 실행하여 사용자에게 논리적 디렉터리 객체를 내보낼 수 있는 권한을 부여합니다.
sql> grant all on directory EXP_DIR to <user performing the export dump>;
예를 들면 다음과 같습니다.
sql> grant all on directory EXP_DIR to pdmadmin;
• 데이터 펌프 가져오기는 항상 하위 호환 버전을 읽을 수 있습니다. • Oracle 11g에서 지원되는 Windchill 11.0 M030의 경우 덤프는 19c Oracle 가져오기와 호환됩니다. |
4. 다음 명령을 실행하여 Windchill 데이터베이스 사용자를 내보냅니다.
expdp userid=system/<password> directory=EXP_DIR
dumpfile=<dump_file_name>%u.dmp logfile=<log_file_name>.log
schemas=<staging db user> filesize=<size>M
dumpfile=<dump_file_name>%u.dmp logfile=<log_file_name>.log
schemas=<staging db user> filesize=<size>M
• <staging db user>에서는 WBM 데이터 마이그레이션 준비에 사용되는 로컬 온프레미스 준비 데이터베이스의 사용자 이름을 지정합니다. • <size>에서 생성된 각 DMP 파일의 원하는 크기를 지정합니다. • 덤프 파일에 스키마 정보를 포함하려면 시스템 사용자와 같은 권한이 있는 사용자가 내보내기를 수행해야 합니다. |
5. 주어진 SQL 스크립트를 실행하여 테이블 공간 크기 조정 정보가 포함된 LST 파일을 작성합니다. 출력 ${PDB_NAME?}.lst 파일을 PTC에 제공해야 합니다.
사전 요구 사항
◦ Windchill 호환 스크립트를 사용하여 준비 데이터베이스가 생성되었는지 확인합니다.
◦ SQL 스크립트를 실행하기 전에 필요한 권한이 있는지 확인합니다. 예를 들어, 준비 데이터베이스 사용자는 질의할 권한이 있어야 합니다.
SQL 스크립트:
read -p "Please, provide PDB_NAME: " PDB_NAME
export PDB_NAME
export LST_FILE_NAME=${PDB_NAME?}.lst
echo "
SET FEEDBACK off;
SET HEADING off;
SET TRIMSPOOL ON
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=${PDB_NAME?};
SPOOL ${LST_FILE_NAME?};
SELECT tablespace_name || '*' || ceil((USED_SPACE*8192*1.2)/(34359738368)) files_required
FROM dba_tablespace_usage_metrics
WHERE tablespace_name NOT IN ('TEMP','SYSTEM','SYSAUX','UNDOTBS1');
" | sqlplus -s / as sysdba
ls -l ${LST_FILE_NAME?}
export PDB_NAME
export LST_FILE_NAME=${PDB_NAME?}.lst
echo "
SET FEEDBACK off;
SET HEADING off;
SET TRIMSPOOL ON
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=${PDB_NAME?};
SPOOL ${LST_FILE_NAME?};
SELECT tablespace_name || '*' || ceil((USED_SPACE*8192*1.2)/(34359738368)) files_required
FROM dba_tablespace_usage_metrics
WHERE tablespace_name NOT IN ('TEMP','SYSTEM','SYSAUX','UNDOTBS1');
" | sqlplus -s / as sysdba
ls -l ${LST_FILE_NAME?}
6. 주어진 SQL 스크립트를 실행하여 데이터베이스 메타데이터 정보가 포함된 MDT 파일을 작성합니다. 출력 ${PDB_NAME?}.mdt 파일을 PTC에 제공해야 합니다.
사전 요구 사항
◦ Windchill 호환 스크립트를 사용하여 준비 데이터베이스가 생성되었는지 확인합니다.
◦ SQL 스크립트를 실행하기 전에 필수 권한이 있는지 확인합니다. 예를 들어, 준비 데이터베이스 사용자에게는 관련 데이터베이스 보기를 쿼리할 권한이 있어야 합니다. 아니면 DBA 또는 SELECT_CATALOG_ROLE 권한이 있는 계정을 사용할 수 있습니다.
SQL 스크립트(db_metadata.sql):
SET verify OFF echo OFF feedback OFF heading OFF trimspool ON pagesize 0
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=&1;
SPOOL &1..mdt
SELECT 'DB:NAME:'||sys_context('USERENV','DB_NAME') FROM dual;
SELECT 'DB:VERSION:' || REGEXP_SUBSTR(version_full, '^\d+\.\d+') FROM v$instance;
SELECT 'DB:COMPATIBLE:' || value FROM database_compatible_level;
SELECT 'DB:TIMEZONE_VERSION:' || version FROM v$timezone_file;
SELECT 'DB:TS_TOTAL_SIZE_GB:' || (SELECT CEIL(SUM(bytes)/1024/1024/1024) FROM (SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files))
FROM dual;
SELECT 'NLS:CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_CHARACTERSET';
SELECT 'NLS:NCHAR_CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_NCHAR_CHARACTERSET';
SELECT 'SCHEMA:NAME:'||UPPER('&2') FROM dual;
SELECT 'SCHEMA:TOTAL_OBJECT_COUNT:' || (SELECT COUNT(*) FROM dba_objects WHERE UPPER(owner)=UPPER('&2')) FROM dual;
SELECT 'SCHEMA:DATA_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2') AND segment_type NOT LIKE '%INDEX%') FROM dual;
SELECT 'SCHEMA:TOTAL_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2')) FROM dual;
SELECT 'EXPORT:DB_REQUIRED_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE UPPER(owner) = UPPER('&2')) FROM dual;
PROMPT # Tablespace Summary:
PROMPT # Format: TS:<TYPE>:<TABLESPACE_NAME>:<USED_GB>:<ALLOCATED_GB>:<FILE_COUNT>:<MAX_GB>
SELECT 'TS:' || CASE
WHEN ts.tablespace_name IN ('SYSTEM', 'SYSAUX') THEN ts.tablespace_name
WHEN ts.contents = 'UNDO' THEN 'UNDO'
WHEN ts.contents = 'TEMPORARY' THEN 'TEMPORARY'
ELSE 'USER'
END || ':' ||
ts.tablespace_name || ':' ||
CEIL(NVL(seg.segment_size_gb, 0)) || ':' ||
CEIL(df.total_size_gb) || ':' ||
df.file_count || ':' ||
CEIL(df.max_size_gb)
FROM (
SELECT tablespace_name,
COUNT(*) AS file_count,
CEIL(SUM(bytes)/1024/1024/1024) AS total_size_gb,
CEIL(SUM(DECODE(maxbytes, 0, bytes, maxbytes))/1024/1024/1024) AS max_size_gb
FROM (
SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files
)
GROUP BY tablespace_name
) df
LEFT JOIN (
SELECT tablespace_name,
CEIL(SUM(bytes)/1024/1024/1024) AS segment_size_gb
FROM dba_segments
GROUP BY tablespace_name
) seg
ON df.tablespace_name = seg.tablespace_name
JOIN dba_tablespaces ts
ON df.tablespace_name = ts.tablespace_name
ORDER BY 1
/
EXIT
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=&1;
SPOOL &1..mdt
SELECT 'DB:NAME:'||sys_context('USERENV','DB_NAME') FROM dual;
SELECT 'DB:VERSION:' || REGEXP_SUBSTR(version_full, '^\d+\.\d+') FROM v$instance;
SELECT 'DB:COMPATIBLE:' || value FROM database_compatible_level;
SELECT 'DB:TIMEZONE_VERSION:' || version FROM v$timezone_file;
SELECT 'DB:TS_TOTAL_SIZE_GB:' || (SELECT CEIL(SUM(bytes)/1024/1024/1024) FROM (SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files))
FROM dual;
SELECT 'NLS:CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_CHARACTERSET';
SELECT 'NLS:NCHAR_CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_NCHAR_CHARACTERSET';
SELECT 'SCHEMA:NAME:'||UPPER('&2') FROM dual;
SELECT 'SCHEMA:TOTAL_OBJECT_COUNT:' || (SELECT COUNT(*) FROM dba_objects WHERE UPPER(owner)=UPPER('&2')) FROM dual;
SELECT 'SCHEMA:DATA_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2') AND segment_type NOT LIKE '%INDEX%') FROM dual;
SELECT 'SCHEMA:TOTAL_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2')) FROM dual;
SELECT 'EXPORT:DB_REQUIRED_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE UPPER(owner) = UPPER('&2')) FROM dual;
PROMPT # Tablespace Summary:
PROMPT # Format: TS:<TYPE>:<TABLESPACE_NAME>:<USED_GB>:<ALLOCATED_GB>:<FILE_COUNT>:<MAX_GB>
SELECT 'TS:' || CASE
WHEN ts.tablespace_name IN ('SYSTEM', 'SYSAUX') THEN ts.tablespace_name
WHEN ts.contents = 'UNDO' THEN 'UNDO'
WHEN ts.contents = 'TEMPORARY' THEN 'TEMPORARY'
ELSE 'USER'
END || ':' ||
ts.tablespace_name || ':' ||
CEIL(NVL(seg.segment_size_gb, 0)) || ':' ||
CEIL(df.total_size_gb) || ':' ||
df.file_count || ':' ||
CEIL(df.max_size_gb)
FROM (
SELECT tablespace_name,
COUNT(*) AS file_count,
CEIL(SUM(bytes)/1024/1024/1024) AS total_size_gb,
CEIL(SUM(DECODE(maxbytes, 0, bytes, maxbytes))/1024/1024/1024) AS max_size_gb
FROM (
SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files
)
GROUP BY tablespace_name
) df
LEFT JOIN (
SELECT tablespace_name,
CEIL(SUM(bytes)/1024/1024/1024) AS segment_size_gb
FROM dba_segments
GROUP BY tablespace_name
) seg
ON df.tablespace_name = seg.tablespace_name
JOIN dba_tablespaces ts
ON df.tablespace_name = ts.tablespace_name
ORDER BY 1
/
EXIT
SQL 스크립트(db_metadata.sh) 시작을 위한 Bash 스크립트:
read -p "Please, provide PDB_NAME: " PDB_NAME
read -p "Please, provide Staging DB User Name: " SCHEMA_NAME
export MDT_FILE_NAME=${PDB_NAME?}.mdt
sqlplus -s / as sysdba @db_metadata.sql "${PDB_NAME?}" "${SCHEMA_NAME?}"
ls -l ${MDT_FILE_NAME?}
read -p "Please, provide Staging DB User Name: " SCHEMA_NAME
export MDT_FILE_NAME=${PDB_NAME?}.mdt
sqlplus -s / as sysdba @db_metadata.sql "${PDB_NAME?}" "${SCHEMA_NAME?}"
ls -l ${MDT_FILE_NAME?}
7. 덤프 파일 및 테이블 공간 세부 정보(LST 파일) 및 메타데이터 파일(MDT 파일)을 <고객 저장소 계정>/container data/database 디렉터리에 업로드합니다.
Oracle Data Pump Export(expdp) 사용
expdp 명령은 Oracle 데이터베이스의 데이터 및 메타데이터를 이진 파일로 내보내는 데 사용됩니다. 이 이진 파일은 데이터베이스 간 백업, 데이터 마이그레이션 또는 데이터 전송과 같은 다양한 용도로 사용할 수 있습니다. 다음 단계에 따라 expdp을 사용합니다.
1. Oracle 데이터베이스가 설치된 컴퓨터에서 명령 프롬프트 또는 터미널 창을 엽니다.
2. 권한 있는 계정을 사용하여 Oracle 데이터베이스에 로그인합니다. 예를 들어, DBA 역할을 가진 사용자 또는 시스템 사용자입니다.
sqlplus username/password
3. 데이터베이스에 연결되면 expdp 명령을 사용하여 데이터를 내보낼 수 있습니다. 기본 구문은 다음과 같습니다.
expdp username/password@database_name DIRECTORY=directory_name DUMPFILE=dumpfile_name [other options]
여기에서
◦ username/password - 사용자의 Oracle 데이터베이스 자격 증명입니다.
◦ database_name - 데이터를 내보낼 데이터베이스의 이름입니다.
◦ DIRECTORY - 내보내기 파일이 작성되는 데이터베이스의 디렉터리 객체를 지정합니다.
◦ DUMPFILE - 내보내기 덤프 파일의 이름을 지정합니다.
4. 요구 사항에 따라 내보내기 프로세스를 사용자 정의하는 다양한 옵션을 포함할 수 있습니다. 다음은 일반적으로 사용되는 몇 가지 옵션입니다.
◦ TABLES: 특정 테이블 또는 스키마를 내보냅니다.
◦ SCHEMAS: 특정 스키마에서 데이터를 내보냅니다.
◦ INCLUDE: 내보내기(예: 테이블, 색인, 제약 조건)에 포함할 항목을 지정합니다.
◦ EXCLUDE: 내보내기에서 제외할 내용을 지정합니다.
◦ PARALLEL: 내보내기를 병렬로 수행하여 성능을 향상시킵니다.
◦ COMPRESSION: 내보내는 동안 데이터 압축을 활성화합니다.
◦ LOGFILE: 내보내기 관련 정보를 기록할 로그 파일을 지정합니다.
예: expdp HR/password@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=hr_export.dmp SCHEMAS=HR
5. Enter 키를 눌러 expdp 명령을 실행합니다. 내보내기의 크기와 복잡성에 따라 프로세스를 완료하는 데 시간이 걸릴 수 있습니다.
6. 내보내기를 마치면 지정된 디렉터리에서 이진 덤프 파일을 볼 수 있습니다.
Oracle Data Pump Import(impdp) 사용
impdp 명령은 이진 덤프 파일의 데이터 및 메타데이터를 Oracle 데이터베이스로 가져오는 데 사용됩니다. 이 이진 파일은 데이터베이스 간 백업, 데이터 마이그레이션 또는 데이터 전송과 같은 다양한 용도로 사용할 수 있습니다. 전체 데이터 및 메타데이터를 한 번에 가져오거나 데이터 및 메타데이터를 증분 방식으로 로드할 수 있습니다. 다음 단계에 따라 impdp을 사용합니다.
1. Oracle 데이터베이스가 설치된 컴퓨터에서 명령 프롬프트 또는 터미널 창을 엽니다.
2. 권한 있는 계정을 사용하여 Oracle 데이터베이스에 로그인합니다. 예를 들어, DBA 역할을 가진 사용자 또는 시스템 사용자입니다.
sqlplus username/password
3. 데이터베이스에 연결되면 impdp 명령을 사용하여 데이터를 가져올 수 있습니다. 기본 구문은 다음과 같습니다.
impdp username/password@database_name DIRECTORY=directory_name DUMPFILE=dumpfile_name [other options]
여기에서
◦ username/password - 사용자의 Oracle 데이터베이스 자격 증명입니다.
◦ database_name - 데이터를 가져올 데이터베이스의 이름입니다.
◦ DIRECTORY - 가져오기 파일이 작성되는 데이터베이스의 디렉터리 객체를 지정합니다.
◦ DUMPFILE - 가져오기 덤프 파일의 이름을 지정합니다.
4. 요구 사항에 따라 가져오기 프로세스를 사용자 정의하는 다양한 옵션을 포함할 수 있습니다. 다음은 일반적으로 사용되는 몇 가지 옵션입니다.
◦ TABLES: 특정 테이블 또는 스키마를 가져옵니다.
◦ SCHEMAS: 특정 스키마에서 데이터를 가져옵니다.
◦ INCLUDE: 가져오기(예: 테이블, 색인, 제약 조건)에 포함할 항목을 지정합니다.
◦ EXCLUDE: 가져오기에서 제외할 내용을 지정합니다.
◦ PARALLEL: 가져오기를 병렬로 수행하여 성능을 향상시킵니다.
◦ COMPRESSION: 가져오기 중 데이터 압축을 활성화합니다.
◦ LOGFILE: 가져오기 관련 정보를 기록할 로그 파일을 지정합니다.
예: impdp HR/password@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=hr_export.dmp SCHEMAS=HR
5. Enter 키를 눌러 impdp 명령을 실행합니다. 가져오기의 크기와 복잡성에 따라 프로세스를 완료하는 데 시간이 걸릴 수 있습니다.
6. 가져오기를 마치면 지정된 디렉터리에서 이진 덤프 파일을 볼 수 있습니다.