WBM のワークフロープロセスと段階
このトピックでは、Windchill Bulk Migrator (WBM) のワークフロープロセスと WBM の各種段階について説明します。
WBM のワークフロープロセス
次のワークフロー図は、WBM マイグレーションの実行を示しています。
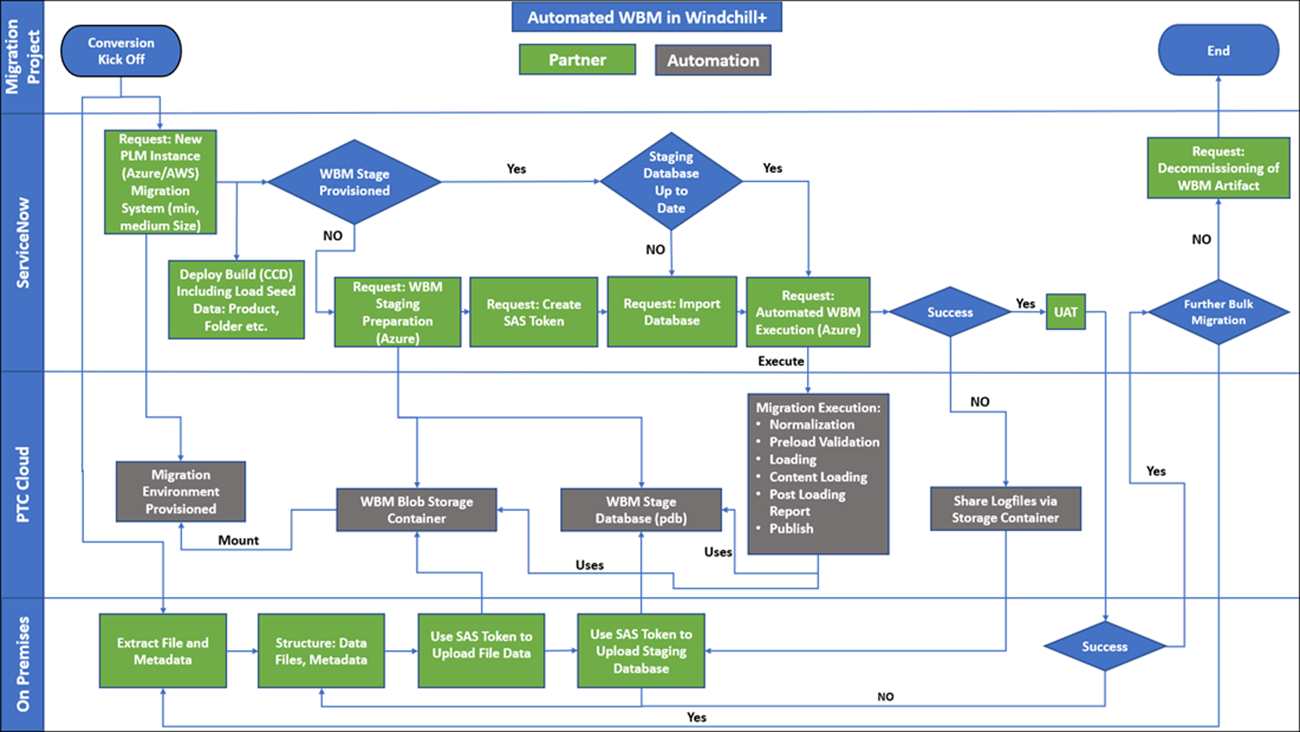
オンプレミスのステージングデータベース
データマイグレーションは、一般に、反復的なプロセスです。最初のフェーズでは、通常、ソースシステムからファイルとメタデータを抽出します。マイグレーションメタデータを構成するには、ステージングデータベースが必要です。複数回のデータ変換を回避するために、オンプレミスのステージングデータベースを使用するものとします。詳細については、https://support.ptc.com を参照してください。
• Windchill バージョンの要件に従って、Oracle データベースを使用する必要があります。 • データベース構造は Windchill WBM ステージングデータベースの要件を満たしている必要があります。 |
Windchill WBM ステージングデータベースの作成
この手順では、開発環境がすでに存在するものとします。
WBM がシステムにインストールされていることを確認します。 |
1. 開発環境で、WT_HOME ディレクトリから開始します。
2. 次のコマンドを実行します。
WT_HOME/bin/wbmgen
モジュールセットと Windchill コンフィギュレーションに従ってステージング構造が生成および準備されます。
3. Oracle データベースに新規スキーマユーザーを作成するには、create_user.sql スクリプトを使用します。以下の手順に従います。
a. DBA 役割が割り当てられているユーザーや SYSTEM ユーザーなど、管理者権限を持つアカウントを使用して Oracle データベースにログインします。
b. 次のスクリプトを実行してステージングユーザーを作成します。
@db/sql(3)/create_user.sql
c. 前の手順で作成したステージングユーザーを使用して Oracle データベースにログインします。
d. 次のスクリプトを実行してステージングスキーマを作成します。
@db/sql(3)/wbm/create_staging_schema.sql
e. 次のスクリプトを実行して監査テーブルを作成します。
@@db/sql(3)/wbm/create_audit_schema.sql
詳細については、WBM Install and Usage Guide の「ローディングインフラストラクチャとオブジェクトローターの設定」のトピックを参照してください。
Oracle Data Pump Export (expdp) を使用したデータベースダンプのエクスポート
Oracle Data Pump (通常は expdp (エクスポートデータポンプ) および impdpm (インポートデータポンプ) と呼ばれる) は、高速データ/メタデータ操作を実行するために Oracle データベースによって提供される一連のコマンドラインユーティリティです。これらのユーティリティは、データのエクスポート、データのインポート、データのマイグレーションなどのタスクに使用されます。詳細については、「Azure Storage アカウント」を参照してください。
以下のセクションでは、Oracle Data Pump を使用してダンプファイルを作成し、expdp を使用してデータをエクスポートする方法について説明します。
Oracle Data Pump を使用したダンプファイルの作成
Oracle Data Pump を使用してダンプファイル作成するには、以下の手順に従います。
ダンプは Windchill システムから抽出されます。抽出プロセス中は Windchill をシャットダウンしておきます。 |
1. Windows または Linux で Windchill シェルまたはコマンドプロンプトを開き、次のコマンドを実行して、データポンプファイルを保存するディレクトリをシステム上に作成します。
mkdir <directory name>
次に例を示します。
mkdir D:\datapump
Windchill データベースユーザースキーマを保存するのに十分な容量があることを確認します。 |
2. Windchill シェルまたはコマンドプロンプトから sqlplus にログインし、次のコマンドを実行して、Oracle に論理ディレクトリオブジェクトを作成します。
sql> create directory EXP_DIR as '<path to operating system directory created previous step>';
このオブジェクトは、前の手順で作成した物理ディレクトリを参照する必要があります。 |
次に例を示します。
sql> create directory EXP_DIR as 'D:\datapump';
3. 同じ sqlplus セッションで、次のコマンドを実行して、論理ディレクトリオブジェクトをエクスポートするアクセス許可をユーザーに付与します。
sql> grant all on directory EXP_DIR to <user performing the export dump>;
次に例を示します。
sql> grant all on directory EXP_DIR to pdmadmin;
• データポンプのインポートでは、互換性のある下位バージョンを常に読み取ることができます。 • Oracle 11g でサポートされている Windchill 11.0 M030 の場合、ダンプは Oracle 19c でのインポートに対応しています。 |
4. 次のコマンドを実行して、Windchill データベースユーザーをエクスポートします。
expdp userid=system/<password> directory=EXP_DIR
dumpfile=<dump_file_name>%u.dmp logfile=<log_file_name>.log
schemas=<staging db user> filesize=<size>M
dumpfile=<dump_file_name>%u.dmp logfile=<log_file_name>.log
schemas=<staging db user> filesize=<size>M
• <staging db user> で、WBM データマイグレーションの準備に使用される、ローカルのオンプレミスステージングデータベースのユーザー名を指定します。 • <size> で、作成される各 DMP ファイルに必要なサイズを指定します。 • スキーマ情報をダンプファイルに含めるには、システムユーザーなど、権限を持つユーザーがエクスポートを実行する必要があります。 |
5. 指定された SQL スクリプトを実行して、テーブルスペースのサイズ情報を含む LST ファイルを作成します。出力 ${PDB_NAME?}.lst ファイルを PTC に提供する必要があります。
必要条件:
◦ Windchill と互換性のあるスクリプトを使用してステージングデータベースが作成されていることを確認します。
◦ SQL スクリプトを実行する前に、必要なアクセス許可が設定されていることを確認します。たとえば、ステージングデータベースユーザーは照会を実行する権限を持つ必要があります。
SQL スクリプト:
read -p "Please, provide PDB_NAME: " PDB_NAME
export PDB_NAME
export LST_FILE_NAME=${PDB_NAME?}.lst
echo "
SET FEEDBACK off;
SET HEADING off;
SET TRIMSPOOL ON
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=${PDB_NAME?};
SPOOL ${LST_FILE_NAME?};
SELECT tablespace_name || '*' || ceil((USED_SPACE*8192*1.2)/(34359738368)) files_required
FROM dba_tablespace_usage_metrics
WHERE tablespace_name NOT IN ('TEMP','SYSTEM','SYSAUX','UNDOTBS1');
" | sqlplus -s / as sysdba
ls -l ${LST_FILE_NAME?}
export PDB_NAME
export LST_FILE_NAME=${PDB_NAME?}.lst
echo "
SET FEEDBACK off;
SET HEADING off;
SET TRIMSPOOL ON
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=${PDB_NAME?};
SPOOL ${LST_FILE_NAME?};
SELECT tablespace_name || '*' || ceil((USED_SPACE*8192*1.2)/(34359738368)) files_required
FROM dba_tablespace_usage_metrics
WHERE tablespace_name NOT IN ('TEMP','SYSTEM','SYSAUX','UNDOTBS1');
" | sqlplus -s / as sysdba
ls -l ${LST_FILE_NAME?}
6. 指定された SQL スクリプトを実行して、データベースのメタデータ情報を含む MDT ファイルを作成します。出力ファイル ${PDB_NAME?}.mdt を PTC に提供する必要があります。
必要条件:
◦ Windchill と互換性のあるスクリプトを使用してステージングデータベースが作成されていることを確認します。
◦ SQL スクリプトを実行する前に、必要なアクセス許可があることを確認します。たとえば、ステージングデータベースユーザーは、すべての関連データベースビューに対してクエリーを実行する権限を持っている必要があります。あるいは、DBA 権限または SELECT_CATALOG_ROLE 権限を持つアカウントを使用することもできます。
SQL スクリプト (db_metadata.sql):
SET verify OFF echo OFF feedback OFF heading OFF trimspool ON pagesize 0
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=&1;
SPOOL &1..mdt
SELECT 'DB:NAME:'||sys_context('USERENV','DB_NAME') FROM dual;
SELECT 'DB:VERSION:' || REGEXP_SUBSTR(version_full, '^\d+\.\d+') FROM v$instance;
SELECT 'DB:COMPATIBLE:' || value FROM database_compatible_level;
SELECT 'DB:TIMEZONE_VERSION:' || version FROM v$timezone_file;
SELECT 'DB:TS_TOTAL_SIZE_GB:' || (SELECT CEIL(SUM(bytes)/1024/1024/1024) FROM (SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files))
FROM dual;
SELECT 'NLS:CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_CHARACTERSET';
SELECT 'NLS:NCHAR_CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_NCHAR_CHARACTERSET';
SELECT 'SCHEMA:NAME:'||UPPER('&2') FROM dual;
SELECT 'SCHEMA:TOTAL_OBJECT_COUNT:' || (SELECT COUNT(*) FROM dba_objects WHERE UPPER(owner)=UPPER('&2')) FROM dual;
SELECT 'SCHEMA:DATA_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2') AND segment_type NOT LIKE '%INDEX%') FROM dual;
SELECT 'SCHEMA:TOTAL_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2')) FROM dual;
SELECT 'EXPORT:DB_REQUIRED_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE UPPER(owner) = UPPER('&2')) FROM dual;
PROMPT # Tablespace Summary:
PROMPT # Format: TS:<TYPE>:<TABLESPACE_NAME>:<USED_GB>:<ALLOCATED_GB>:<FILE_COUNT>:<MAX_GB>
SELECT 'TS:' || CASE
WHEN ts.tablespace_name IN ('SYSTEM', 'SYSAUX') THEN ts.tablespace_name
WHEN ts.contents = 'UNDO' THEN 'UNDO'
WHEN ts.contents = 'TEMPORARY' THEN 'TEMPORARY'
ELSE 'USER'
END || ':' ||
ts.tablespace_name || ':' ||
CEIL(NVL(seg.segment_size_gb, 0)) || ':' ||
CEIL(df.total_size_gb) || ':' ||
df.file_count || ':' ||
CEIL(df.max_size_gb)
FROM (
SELECT tablespace_name,
COUNT(*) AS file_count,
CEIL(SUM(bytes)/1024/1024/1024) AS total_size_gb,
CEIL(SUM(DECODE(maxbytes, 0, bytes, maxbytes))/1024/1024/1024) AS max_size_gb
FROM (
SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files
)
GROUP BY tablespace_name
) df
LEFT JOIN (
SELECT tablespace_name,
CEIL(SUM(bytes)/1024/1024/1024) AS segment_size_gb
FROM dba_segments
GROUP BY tablespace_name
) seg
ON df.tablespace_name = seg.tablespace_name
JOIN dba_tablespaces ts
ON df.tablespace_name = ts.tablespace_name
ORDER BY 1
/
EXIT
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=&1;
SPOOL &1..mdt
SELECT 'DB:NAME:'||sys_context('USERENV','DB_NAME') FROM dual;
SELECT 'DB:VERSION:' || REGEXP_SUBSTR(version_full, '^\d+\.\d+') FROM v$instance;
SELECT 'DB:COMPATIBLE:' || value FROM database_compatible_level;
SELECT 'DB:TIMEZONE_VERSION:' || version FROM v$timezone_file;
SELECT 'DB:TS_TOTAL_SIZE_GB:' || (SELECT CEIL(SUM(bytes)/1024/1024/1024) FROM (SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files))
FROM dual;
SELECT 'NLS:CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_CHARACTERSET';
SELECT 'NLS:NCHAR_CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_NCHAR_CHARACTERSET';
SELECT 'SCHEMA:NAME:'||UPPER('&2') FROM dual;
SELECT 'SCHEMA:TOTAL_OBJECT_COUNT:' || (SELECT COUNT(*) FROM dba_objects WHERE UPPER(owner)=UPPER('&2')) FROM dual;
SELECT 'SCHEMA:DATA_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2') AND segment_type NOT LIKE '%INDEX%') FROM dual;
SELECT 'SCHEMA:TOTAL_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2')) FROM dual;
SELECT 'EXPORT:DB_REQUIRED_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE UPPER(owner) = UPPER('&2')) FROM dual;
PROMPT # Tablespace Summary:
PROMPT # Format: TS:<TYPE>:<TABLESPACE_NAME>:<USED_GB>:<ALLOCATED_GB>:<FILE_COUNT>:<MAX_GB>
SELECT 'TS:' || CASE
WHEN ts.tablespace_name IN ('SYSTEM', 'SYSAUX') THEN ts.tablespace_name
WHEN ts.contents = 'UNDO' THEN 'UNDO'
WHEN ts.contents = 'TEMPORARY' THEN 'TEMPORARY'
ELSE 'USER'
END || ':' ||
ts.tablespace_name || ':' ||
CEIL(NVL(seg.segment_size_gb, 0)) || ':' ||
CEIL(df.total_size_gb) || ':' ||
df.file_count || ':' ||
CEIL(df.max_size_gb)
FROM (
SELECT tablespace_name,
COUNT(*) AS file_count,
CEIL(SUM(bytes)/1024/1024/1024) AS total_size_gb,
CEIL(SUM(DECODE(maxbytes, 0, bytes, maxbytes))/1024/1024/1024) AS max_size_gb
FROM (
SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files
)
GROUP BY tablespace_name
) df
LEFT JOIN (
SELECT tablespace_name,
CEIL(SUM(bytes)/1024/1024/1024) AS segment_size_gb
FROM dba_segments
GROUP BY tablespace_name
) seg
ON df.tablespace_name = seg.tablespace_name
JOIN dba_tablespaces ts
ON df.tablespace_name = ts.tablespace_name
ORDER BY 1
/
EXIT
SQL スクリプトを起動するための bash スクリプト (db_metadata.sh):
read -p "Please, provide PDB_NAME: " PDB_NAME
read -p "Please, provide Staging DB User Name: " SCHEMA_NAME
export MDT_FILE_NAME=${PDB_NAME?}.mdt
sqlplus -s / as sysdba @db_metadata.sql "${PDB_NAME?}" "${SCHEMA_NAME?}"
ls -l ${MDT_FILE_NAME?}
read -p "Please, provide Staging DB User Name: " SCHEMA_NAME
export MDT_FILE_NAME=${PDB_NAME?}.mdt
sqlplus -s / as sysdba @db_metadata.sql "${PDB_NAME?}" "${SCHEMA_NAME?}"
ls -l ${MDT_FILE_NAME?}
7. ダンプファイル、テーブルスペースの詳細 (LST ファイル)、およびメタデータファイル (MDT ファイル) を <お客様のストレージアカウント>/container data/database ディレクトリにアップロードします。
Oracle Data Pump エクスポート (expdp) の使用
expdp コマンドは Oracle データベースからバイナリファイルにデータやメタデータをエクスポートするときに使用し、これはバックアップ、データマイグレーション、データベース間でのデータ転送など、さまざまな目的に使用できます。expdp を使用するには、以下の手順に従います。
1. Oracle データベースがインストールされているマシンでコマンドプロンプトまたはターミナルウィンドウを開きます。
2. 特権アカウントを使用して Oracle データベースにログインします。たとえば、DBA 役割が割り当てられているユーザーやシステムユーザーなどです。
sqlplus username/password
3. データベースに接続した後、expdp コマンドを使用してデータをエクスポートできます。基本構文は以下のとおりです。
expdp username/password@database_name DIRECTORY=directory_name DUMPFILE=dumpfile_name [other options]
ここで、
◦ username/password - Oracle データベースの資格証明。
◦ database_name - データのエクスポート元となるデータベースの名前。
◦ DIRECTORY - エクスポートファイルが書き込まれるデータベース内のディレクトリオブジェクトを指定します。
◦ DUMPFILE - エクスポートダンプファイルの名前を指定します。
4. 各種オプションを追加して、要件に応じてエクスポートプロセスをカスタマイズできます。一般的に使用されるオプションを以下に示します。
◦ TABLES: 特定のテーブルまたはスキーマをエクスポートします。
◦ SCHEMAS: 特定のスキーマからデータをエクスポートします。
◦ INCLUDE: エクスポートに含めるもの (テーブル、インデックス、制約など) を指定します。
◦ EXCLUDE: エクスポートから除外するものを指定します。
◦ PARALLEL: パフォーマンスを向上させるために、エクスポートを同時実行します。
◦ COMPRESSION: エクスポート中のデータ圧縮を有効にします。
◦ LOGFILE: エクスポート関連情報を記録するログファイルを指定します。
例: expdp HR/password@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=hr_export.dmp SCHEMAS=HR
5. Enter キーを押して expdp コマンドを実行します。エクスポートのサイズや複雑度によっては、プロセスの完了に時間がかかる場合があります。
6. エクスポートが完了した後、指定したディレクトリ内にバイナリダンプファイルが表示されます。
Oracle Data Pump インポート (impdp) の使用
impdp コマンドは、バイナリダンプファイルから Oracle データベースにデータやメタデータをインポートするために使用されます。このコマンドは、バックアップ、データマイグレーション、またはデータベース間でのデータ転送など、さまざまな目的で使用できます。完全なデータとメタデータを一度にインポートすることも、データとメタデータを増分的に読み込むこともできます。impdp を使用するには、以下の手順に従います。
1. Oracle データベースがインストールされているマシンでコマンドプロンプトまたはターミナルウィンドウを開きます。
2. 特権アカウントを使用して Oracle データベースにログインします。たとえば、DBA 役割が割り当てられているユーザーやシステムユーザーなどです。
sqlplus username/password
3. データベースに接続した後、impdp コマンドを使用してデータをインポートできます。基本構文は以下のとおりです。
impdp username/password@database_name DIRECTORY=directory_name DUMPFILE=dumpfile_name [other options]
ここで、
◦ username/password - Oracle データベースの資格証明。
◦ database_name - データのインポート元となるデータベースの名前。
◦ DIRECTORY - インポートファイルが書き込まれるデータベース内のディレクトリオブジェクトを指定します。
◦ DUMPFILE - インポートダンプファイルの名前を指定します。
4. 各種オプションを追加して、要件に応じてインポートプロセスをカスタマイズできます。一般的に使用されるオプションを以下に示します。
◦ TABLES: 特定のテーブルまたはスキーマをインポートします。
◦ SCHEMAS: 特定のスキーマからデータをインポートします。
◦ INCLUDE: インポートに含める対象 (テーブル、インデックス、制約など) を指定します。
◦ EXCLUDE: インポートから除外する対象を指定します。
◦ PARALLEL: パフォーマンスを向上させるために、インポートを同時実行します。
◦ COMPRESSION: インポート時のデータ圧縮を有効にします。
◦ LOGFILE: インポート関連情報を記録するログファイルを指定します。
例: impdp HR/password@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=hr_export.dmp SCHEMAS=HR
5. Enter キーを押して impdp コマンドを実行します。インポートのサイズや複雑度によっては、プロセスの完了に時間がかかる場合があります。
6. インポートが完了した後、指定したディレクトリ内にバイナリダンプファイルが表示されます。