Processus et étapes WBM
Cette rubrique décrit le processus Windchill Bulk Migrator (WBM) et les différentes étapes WBM.
Processus WBM
Le diagramme de processus suivant illustre l'exécution de la migration WBM :
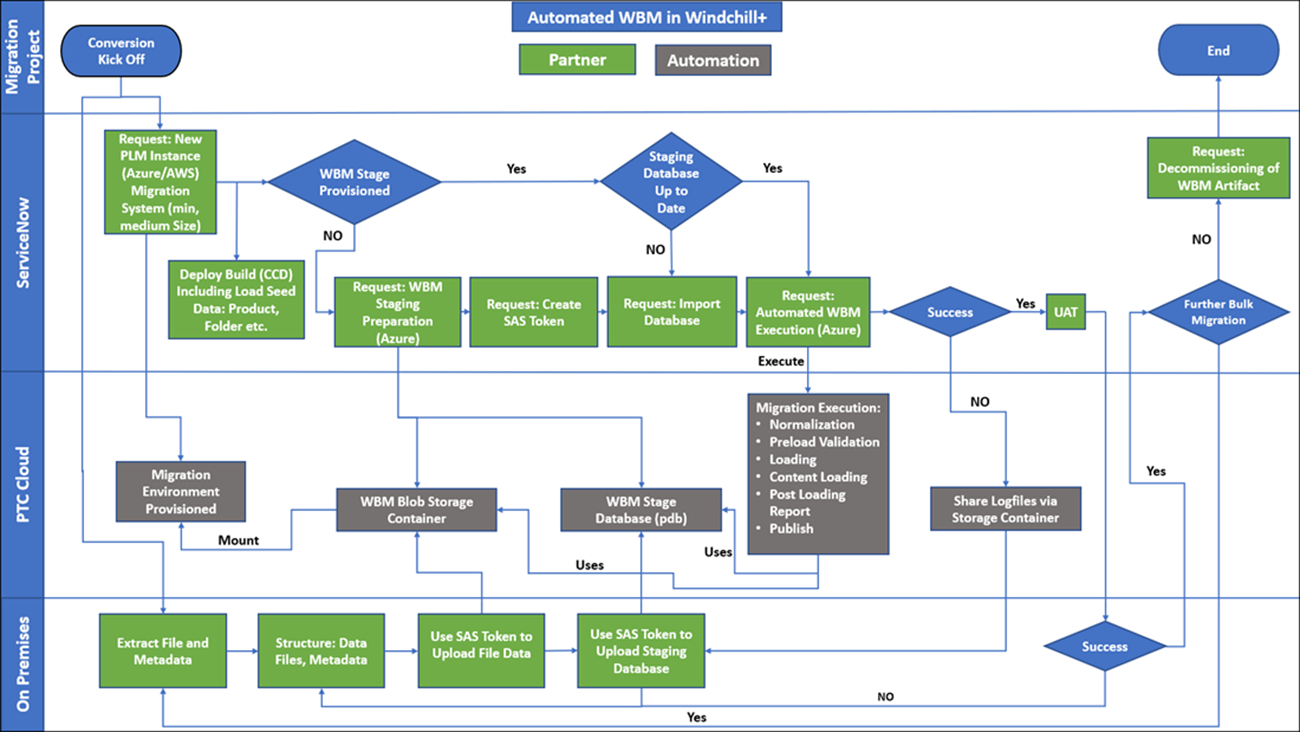
Base de données intermédiaire sur site
La migration des données est généralement un processus itératif. La première phase implique généralement l'extraction de fichiers et de métadonnées à partir d'un système source. Pour structurer les métadonnées de migration, une base de données intermédiaire est nécessaire. Pour éliminer plusieurs transformations de données, il est supposé qu'une base de données intermédiaire sur site est utilisée. Pour plus d'informations, consultez https://support.ptc.com.
• La base de données doit être Oracle conformément aux exigences de version de Windchill. • La structure de base de données doit respecter les exigences de base de données intermédiaire WBM de Windchill. |
Création d'une base de données intermédiaire WBM Windchill
Cette procédure suppose que vous disposez d'un environnement de développement existant.
Assurez-vous que WBM est installé sur votre système. |
1. Dans votre environnement de développement, commencez par le répertoire WT_HOME.
2. Exécutez la commande suivante :
WT_HOME/bin/wbmgen
Cette opération génère et prépare la structure intermédiaire en fonction du jeu de modules et de la configuration de Windchill.
3. Pour créer un nouvel utilisateur de schéma dans une base de données Oracle, utilisez le script create_user.sql. Suivez ces étapes :
a. Connectez-vous à votre base de données Oracle à l'aide d'un compte doté de privilèges d'administration, tels qu'un utilisateur disposant du rôle DBA ou l'utilisateur SYSTEM.
b. Exécutez le script suivant pour créer un utilisateur intermédiaire :
@db/sql(3)/create_user.sql
c. Connectez-vous à votre base de données Oracle à l'aide de l'utilisateur intermédiaire créé précédemment.
d. Exécutez le script suivant pour créer le schéma intermédiaire :
@db/sql(3)/wbm/create_staging_schema.sql
e. Exécutez le script suivant pour créer des tables d'audit :
@@db/sql(3)/wbm/create_audit_schema.sql
Pour plus d'informations, consultez la rubrique Configuring the Loading the Infrastructure and Object Loaders du manuel anglais Windchill Bulk Migrator Installation and Usage Guide (Guide d'installation et d'utilisation de Windchill Bulk Migrator).
Exporter votre vidage de base de données avec Oracle Data Pump Export (expdp)
Oracle Data Pump, souvent appelé expdp (export data pump) et impdpm (import data pump) est un ensemble d'utilitaires de ligne de commande fournis par la base de données Oracle permettant d'effectuer des opérations à grande vitesse sur les données et métadonnées. Ces utilitaires sont utilisés pour des tâches telles que l'exportation, l'importation et la migration des données. Pour plus d'informations, consultez la rubriqueCompte de stockage Azure
La section suivante explique comment créer un fichier de vidage à l'aide de l'utilitaire Oracle Data Pump et comment exporter les données via expdp.
Création d'un fichier de vidage à l'aide d'Oracle Data Pump
Pour créer un fichier de vidage à l'aide d'Oracle Data Pump, procédez comme suit :
Les vidages sont extraits du système Windchill. Assurez-vous que Windchill est arrêté pendant le processus d'extraction. |
1. Ouvrez le shell Windchill ou l'invite de commande dans Windows ou Linux, et exécutez la commande suivante pour créer un répertoire sur votre système, afin de stocker les fichiers de vidage de données :
mkdir <directory name>
Par exemple :
mkdir D:\datapump
Assurez-vous que vous disposez d'un espace de stockage suffisant pour le schéma d'utilisateur de la base de données Windchill. |
2. Connectez-vous à sqlplus à partir du shell Windchill ou de l'invite de commande et exécutez la commande suivante pour créer un objet de répertoire logique dans Oracle :
sql> create directory EXP_DIR as '<path to operating system directory created previous step>';
Cet objet doit pointer vers le répertoire physique créé à l'étape précédente. |
Par exemple :
sql> create directory EXP_DIR as 'D:\datapump';
3. Dans la même session sqlplus, exécutez la commande suivante pour accorder à l'utilisateur la permission d'exporter l'objet de répertoire logique :
sql> grant all on directory EXP_DIR to <user performing the export dump>;
Par exemple :
sql> grant all on directory EXP_DIR to pdmadmin;
• Les importations de données avec Oracle Data Pump peuvent toujours lire les versions compatibles inférieures. • Pour la version Windchill 11.0 M030 prise en charge avec Oracle 11g, le vidage est compatible pour l'importation sur Oracle 19c. |
4. Exécutez la commande suivante pour exporter l'utilisateur de base de données Windchill :
expdp userid=system/<password> directory=EXP_DIR
dumpfile=<dump_file_name>%u.dmp logfile=<log_file_name>.log
schemas=<staging db user> filesize=<size>M
dumpfile=<dump_file_name>%u.dmp logfile=<log_file_name>.log
schemas=<staging db user> filesize=<size>M
• Dans <staging db user>, spécifiez le nom d'utilisateur de la base de données intermédiaire sur site locale utilisée pour la préparation de la migration des données WBM. • Dans <size>, spécifiez la taille souhaitée pour chaque fichier DMP créé. • L'exportation doit être effectuée par un utilisateur disposant de privilèges, tel qu'un utilisateur système, pour inclure les informations de schéma dans le fichier de vidage. |
5. Créez un fichier LST contenant les informations de dimensionnement de l'espace de table en exécutant le script SQL spécifique. Le fichier de sortie ${PDB_NAME?}.lst doit être fourni à PTC.
Configuration requise :
◦ Assurez-vous que la base de données intermédiaire est créée avec des scripts Windchill compatibles.
◦ Avant d'exécuter le script SQL, assurez-vous de disposer des permissions requises. Par exemple, les utilisateurs de la base de données intermédiaire doivent avoir le droit d'interroger.
Script SQL :
read -p "Please, provide PDB_NAME: " PDB_NAME
export PDB_NAME
export LST_FILE_NAME=${PDB_NAME?}.lst
echo "
SET FEEDBACK off;
SET HEADING off;
SET TRIMSPOOL ON
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=${PDB_NAME?};
SPOOL ${LST_FILE_NAME?};
SELECT tablespace_name || '*' || ceil((USED_SPACE*8192*1.2)/(34359738368)) files_required
FROM dba_tablespace_usage_metrics
WHERE tablespace_name NOT IN ('TEMP','SYSTEM','SYSAUX','UNDOTBS1');
" | sqlplus -s / as sysdba
ls -l ${LST_FILE_NAME?}
export PDB_NAME
export LST_FILE_NAME=${PDB_NAME?}.lst
echo "
SET FEEDBACK off;
SET HEADING off;
SET TRIMSPOOL ON
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=${PDB_NAME?};
SPOOL ${LST_FILE_NAME?};
SELECT tablespace_name || '*' || ceil((USED_SPACE*8192*1.2)/(34359738368)) files_required
FROM dba_tablespace_usage_metrics
WHERE tablespace_name NOT IN ('TEMP','SYSTEM','SYSAUX','UNDOTBS1');
" | sqlplus -s / as sysdba
ls -l ${LST_FILE_NAME?}
6. Créez un fichier MDT contenant les informations de métadonnées de base de données en exécutant le script SQL spécifique. Le fichier de sortie ${PDB_NAME?}.mdt doit être fourni à PTC.
Configuration requise :
◦ Assurez-vous que la base de données intermédiaire est créée avec des scripts Windchill compatibles.
◦ Avant d'exécuter le script SQL, assurez-vous de disposer des permissions requises. Par exemple, les utilisateurs de la base de données intermédiaire doivent avoir le droit d'interroger toutes les vues de base de données pertinentes. Vous pouvez également utiliser un compte avec des privilèges DBA ou SELECT_CATALOG_ROLE.
Script SQL (db_metadata.sql) :
SET verify OFF echo OFF feedback OFF heading OFF trimspool ON pagesize 0
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=&1;
SPOOL &1..mdt
SELECT 'DB:NAME:'||sys_context('USERENV','DB_NAME') FROM dual;
SELECT 'DB:VERSION:' || REGEXP_SUBSTR(version_full, '^\d+\.\d+') FROM v$instance;
SELECT 'DB:COMPATIBLE:' || value FROM database_compatible_level;
SELECT 'DB:TIMEZONE_VERSION:' || version FROM v$timezone_file;
SELECT 'DB:TS_TOTAL_SIZE_GB:' || (SELECT CEIL(SUM(bytes)/1024/1024/1024) FROM (SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files))
FROM dual;
SELECT 'NLS:CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_CHARACTERSET';
SELECT 'NLS:NCHAR_CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_NCHAR_CHARACTERSET';
SELECT 'SCHEMA:NAME:'||UPPER('&2') FROM dual;
SELECT 'SCHEMA:TOTAL_OBJECT_COUNT:' || (SELECT COUNT(*) FROM dba_objects WHERE UPPER(owner)=UPPER('&2')) FROM dual;
SELECT 'SCHEMA:DATA_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2') AND segment_type NOT LIKE '%INDEX%') FROM dual;
SELECT 'SCHEMA:TOTAL_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2')) FROM dual;
SELECT 'EXPORT:DB_REQUIRED_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE UPPER(owner) = UPPER('&2')) FROM dual;
PROMPT # Tablespace Summary:
PROMPT # Format: TS:<TYPE>:<TABLESPACE_NAME>:<USED_GB>:<ALLOCATED_GB>:<FILE_COUNT>:<MAX_GB>
SELECT 'TS:' || CASE
WHEN ts.tablespace_name IN ('SYSTEM', 'SYSAUX') THEN ts.tablespace_name
WHEN ts.contents = 'UNDO' THEN 'UNDO'
WHEN ts.contents = 'TEMPORARY' THEN 'TEMPORARY'
ELSE 'USER'
END || ':' ||
ts.tablespace_name || ':' ||
CEIL(NVL(seg.segment_size_gb, 0)) || ':' ||
CEIL(df.total_size_gb) || ':' ||
df.file_count || ':' ||
CEIL(df.max_size_gb)
FROM (
SELECT tablespace_name,
COUNT(*) AS file_count,
CEIL(SUM(bytes)/1024/1024/1024) AS total_size_gb,
CEIL(SUM(DECODE(maxbytes, 0, bytes, maxbytes))/1024/1024/1024) AS max_size_gb
FROM (
SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files
)
GROUP BY tablespace_name
) df
LEFT JOIN (
SELECT tablespace_name,
CEIL(SUM(bytes)/1024/1024/1024) AS segment_size_gb
FROM dba_segments
GROUP BY tablespace_name
) seg
ON df.tablespace_name = seg.tablespace_name
JOIN dba_tablespaces ts
ON df.tablespace_name = ts.tablespace_name
ORDER BY 1
/
EXIT
WHENEVER SQLERROR EXIT SQL.SQLCODE;
ALTER SESSION SET container=&1;
SPOOL &1..mdt
SELECT 'DB:NAME:'||sys_context('USERENV','DB_NAME') FROM dual;
SELECT 'DB:VERSION:' || REGEXP_SUBSTR(version_full, '^\d+\.\d+') FROM v$instance;
SELECT 'DB:COMPATIBLE:' || value FROM database_compatible_level;
SELECT 'DB:TIMEZONE_VERSION:' || version FROM v$timezone_file;
SELECT 'DB:TS_TOTAL_SIZE_GB:' || (SELECT CEIL(SUM(bytes)/1024/1024/1024) FROM (SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files))
FROM dual;
SELECT 'NLS:CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_CHARACTERSET';
SELECT 'NLS:NCHAR_CHARACTERSET:' || value FROM nls_database_parameters WHERE UPPER(parameter) = 'NLS_NCHAR_CHARACTERSET';
SELECT 'SCHEMA:NAME:'||UPPER('&2') FROM dual;
SELECT 'SCHEMA:TOTAL_OBJECT_COUNT:' || (SELECT COUNT(*) FROM dba_objects WHERE UPPER(owner)=UPPER('&2')) FROM dual;
SELECT 'SCHEMA:DATA_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2') AND segment_type NOT LIKE '%INDEX%') FROM dual;
SELECT 'SCHEMA:TOTAL_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE owner=UPPER('&2')) FROM dual;
SELECT 'EXPORT:DB_REQUIRED_SIZE_GB:' || (SELECT TO_CHAR(CEIL(SUM(bytes)/1024/1024/1024)) FROM dba_segments WHERE UPPER(owner) = UPPER('&2')) FROM dual;
PROMPT # Tablespace Summary:
PROMPT # Format: TS:<TYPE>:<TABLESPACE_NAME>:<USED_GB>:<ALLOCATED_GB>:<FILE_COUNT>:<MAX_GB>
SELECT 'TS:' || CASE
WHEN ts.tablespace_name IN ('SYSTEM', 'SYSAUX') THEN ts.tablespace_name
WHEN ts.contents = 'UNDO' THEN 'UNDO'
WHEN ts.contents = 'TEMPORARY' THEN 'TEMPORARY'
ELSE 'USER'
END || ':' ||
ts.tablespace_name || ':' ||
CEIL(NVL(seg.segment_size_gb, 0)) || ':' ||
CEIL(df.total_size_gb) || ':' ||
df.file_count || ':' ||
CEIL(df.max_size_gb)
FROM (
SELECT tablespace_name,
COUNT(*) AS file_count,
CEIL(SUM(bytes)/1024/1024/1024) AS total_size_gb,
CEIL(SUM(DECODE(maxbytes, 0, bytes, maxbytes))/1024/1024/1024) AS max_size_gb
FROM (
SELECT tablespace_name, bytes, maxbytes FROM dba_data_files
UNION ALL
SELECT tablespace_name, bytes, maxbytes FROM dba_temp_files
)
GROUP BY tablespace_name
) df
LEFT JOIN (
SELECT tablespace_name,
CEIL(SUM(bytes)/1024/1024/1024) AS segment_size_gb
FROM dba_segments
GROUP BY tablespace_name
) seg
ON df.tablespace_name = seg.tablespace_name
JOIN dba_tablespaces ts
ON df.tablespace_name = ts.tablespace_name
ORDER BY 1
/
EXIT
Script Bash pour démarrer le script SQL (db_metadata.sh) :
read -p "Please, provide PDB_NAME: " PDB_NAME
read -p "Please, provide Staging DB User Name: " SCHEMA_NAME
export MDT_FILE_NAME=${PDB_NAME?}.mdt
sqlplus -s / as sysdba @db_metadata.sql "${PDB_NAME?}" "${SCHEMA_NAME?}"
ls -l ${MDT_FILE_NAME?}
read -p "Please, provide Staging DB User Name: " SCHEMA_NAME
export MDT_FILE_NAME=${PDB_NAME?}.mdt
sqlplus -s / as sysdba @db_metadata.sql "${PDB_NAME?}" "${SCHEMA_NAME?}"
ls -l ${MDT_FILE_NAME?}
7. Chargez les fichiers de vidage, les détails de l'espace de table (fichier LST) et le fichier de métadonnées (fichier MDT) dans le répertoire <compte de stockage client>/container data/database.
Utilisation d'Oracle Data Pump Export (expdp)
La commande expdp permet d'exporter des données et des métadonnées d'une base de données Oracle vers un fichier binaire, utilisable à diverses fins, telles que la sauvegarde des données, la migration des données ou le transfert de données entre bases de données. Procédez comme suit pour utiliser expdp :
1. Ouvrez l'invite de commande ou la fenêtre système sur la machine sur laquelle la base de données Oracle est installée.
2. Connectez-vous à la base de données Oracle à l'aide d'un compte privilégié. Par exemple, un utilisateur avec le rôle DBA ou l'utilisateur système.
sqlplus username/password
3. Une fois connecté(e) à la base de données, vous pouvez utiliser la commande expdp pour exporter des données. La syntaxe de base est la suivante :
expdp username/password@database_name DIRECTORY=directory_name DUMPFILE=dumpfile_name [other options]
où :
◦ username/password : vos informations d'identification pour la base de données Oracle.
◦ database_name : nom de la base de données à partir de laquelle vous souhaitez exporter des données.
◦ DIRECTORY : désigne l'objet de répertoire dans la base de données dans laquelle le fichier d'exportation est écrit.
◦ DUMPFILE : spécifie le nom du fichier de vidage d'exportation.
4. Vous pouvez inclure différentes options pour personnaliser le processus d'exportation en fonction de vos exigences. Voici quelques options fréquemment utilisées :
◦ TABLES : permet d'exporter des tables ou schémas spécifiques.
◦ SCHEMAS : permet d'exporter des données à partir de schémas spécifiques.
◦ INCLUDE : permet de spécifier les éléments à inclure dans l'exportation (par exemple, les tables, les index, les contraintes).
◦ EXCLUDE : permet de spécifier les éléments à exclure de l'exportation.
◦ PARALLEL : permet d'effectuer l'exportation en parallèle pour améliorer les performances.
◦ COMPRESSION : permet d'activer la compression des données pendant l'exportation.
◦ LOGFILE : permet de spécifier un fichier journal pour enregistrer les informations relatives à l'exportation.
Par exemple : expdp HR/password@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=hr_export.dmp SCHEMAS=HR.
5. Appuyez sur Entrée pour exécuter la commande expdp. Selon la taille et la complexité de l'exportation, l'exécution du processus peut prendre un certain temps.
6. Une fois l'exportation terminée, vous pouvez afficher un fichier de vidage binaire dans le répertoire spécifié.
Utilisation d'Oracle Data Pump Import (impdp)
La commande impdp permet d'importer des données et des métadonnées d'un fichier de vidage binaire vers une base de données Oracle, utilisable à diverses fins, telles que la sauvegarde des données, la migration des données ou le transfert de données entre bases de données. Vous pouvez importer l'ensemble des données et métadonnées en une seule fois ou charger les données et métadonnées de manière incrémentielle. Procédez comme suit pour utiliser impdp :
1. Ouvrez l'invite de commande ou la fenêtre système sur la machine sur laquelle la base de données Oracle est installée.
2. Connectez-vous à la base de données Oracle à l'aide d'un compte privilégié. Par exemple, un utilisateur avec le rôle DBA ou l'utilisateur système.
sqlplus username/password
3. Une fois connecté à la base de données, vous pouvez utiliser la commande impdp pour importer des données. La syntaxe de base est la suivante :
impdp username/password@database_name DIRECTORY=directory_name DUMPFILE=dumpfile_name [other options]
où :
◦ username/password : vos informations d'identification pour la base de données Oracle.
◦ database_name : nom de la base de données à partir de laquelle vous souhaitez importer des données.
◦ DIRECTORY : désigne l'objet de répertoire dans la base de données dans laquelle le fichier d'importation est écrit.
◦ DUMPFILE : spécifie le nom du fichier de vidage d'importation.
4. Vous pouvez inclure différentes options pour personnaliser le processus d'importation en fonction de vos exigences. Voici quelques options fréquemment utilisées :
◦ TABLES : permet d'importer des tableaux ou schémas spécifiques.
◦ SCHEMAS : permet d'importer des données à partir de schémas spécifiques.
◦ INCLUDE : permet de spécifier les éléments à inclure dans l'importation (par exemple, les tables, les index, les contraintes).
◦ EXCLUDE : permet de spécifier les éléments à exclure de l'importation.
◦ PARALLEL : permet d'effectuer l'importation en parallèle pour améliorer les performances.
◦ COMPRESSION : permet d'activer la compression des données pendant l'importation.
◦ LOGFILE : permet de spécifier un fichier journal pour enregistrer les informations relatives à l'importation.
Par exemple : impdp HR/password@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=hr_export.dmp SCHEMAS=HR.
5. Appuyez sur Entrée pour exécuter la commande impdp. Selon la taille et la complexité de l'importation, l'exécution du processus peut prendre un certain temps.
6. Une fois l'importation terminée, vous pouvez afficher un fichier de vidage binaire dans le répertoire spécifié.