The Certainty Parameter
When implementing Anomaly Detection, there are a number of factors to consider. At its most basic, anomaly monitor functionality compares two sets of data, a validation set (collected during the Calibrating phase) and a test set (data streaming from a remote device). The anomaly monitor tries to determine the likelihood that the distribution of values in the test set is from the same distribution of values contained in the validation set. The accuracy of the model plays a large role in this determination, but so does the Certainty parameter, used for the statistical analysis of the two data sets.
What is Certainty?
Certainty is a tunable parameter that you set when you create a new anomaly alert (acceptable values must be greater than 50% and less than 100%). Certainty defines a percentage threshold used by the anomaly monitor to identify whether the comparison between the validation and test data sets shows anomalous values. For instance, a certainty of 99.99 means that you want to be 99.99% certain before indicating an anomaly. Very high certainty values will make the anomaly monitor less likely to initiate a false positive, while lower certainty values will lead to fewer false negatives.
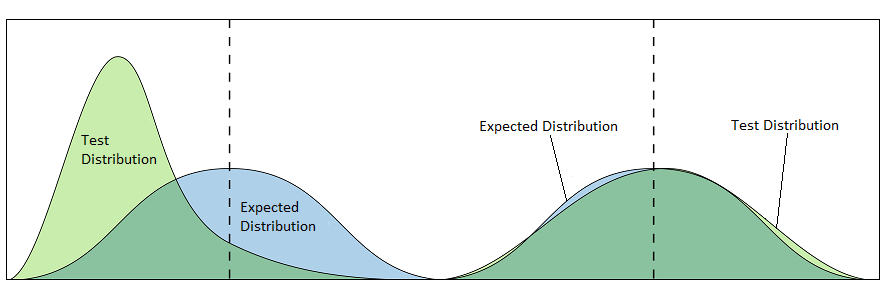
For example, the figure below shows two sets of compared distributions. Each graph displays an expected distribution, built from the validation data collected during the Calibrating state, and a test distribution, representing new incoming data. In the graph on the left, the two distributions are obviously different and will produce a very low probability that the distributions are equivalent. The graph on the right shows two very similar distributions. The probability that these distributions are equivalent is greatly increased. However, the similarity of the distributions does not imply that they are the same. Depending on the Certainty parameter, the anomaly monitor could still indicate an anomaly between the distributions on the right. A very high value for Certainty (eg: 99.9999) will prevent the comparison on the right from triggering an anomaly.
Determining a Certainty Threshold
Selecting the appropriate value for the Certainty parameter is more of an art than a science. It is a subjective decision based on a variety of factors which might require a trial and error approach. If you create an anomaly alert with very high certainty values, the anomaly indicator will be weighted to reduce false positives, possibly at the expense of true positives. Lower certainties will increase the rate of true positives, but might also increase the number of false alarms. The decision about whether to use higher or lower certainty values depends on your environment.
If the risks associated with a failure are great for the device you are monitoring (such as a medical device), you will want to set lower certainty values so that the anomaly alert will detect any possible anomalies. However, if a failure is not mission critical, but the costs are high for false positives (such as sending technicians for a false alarm), you will want to set higher certainty values so that the anomaly alert will detect anomalies only when they are highly likely.
So, why is determining the appropriate Certainty parameter such a subjective decision? For one thing, there is no algorithm to determine an optimal certainty threshold that will balance false positives against false negatives for a given situation. For another, when dealing with streaming data, an anomaly does not always indicate that a failure is imminent. An anomaly indicates that incoming data is different from previous data. It may require observation by a subject matter expert to determine when an anomaly indicates potential failure. In addition, a trained observer may be able to identify a false positive easily, but the nature of streaming data makes a false negative significantly more difficult to identify.
To determine the Certainty parameter that works for your situation, start with a low initial threshold (such as 80%) and stream data for some time to see what type of anomalies are detected. If an unacceptable level of false anomalies are reported, raise the certainty and stream more data. This process might require some time as you move the certainty up and down and observe the results. This is true especially for cases when the streaming data does not contain many examples of anomalous behavior. In some cases, you can try introducing anomalies to monitor the results at a specific certainty. Be careful not to raise the certainty to a point where true anomalies are missed.