Interpreting Predictive Scoring Results
When you download results from a predictive scoring job, they are output in a CSV format. Each row represents a specific results record. The specific columns in the output vary according to the parameters you configure when you launch the scoring job. The following types of columns can be included in prediction results:
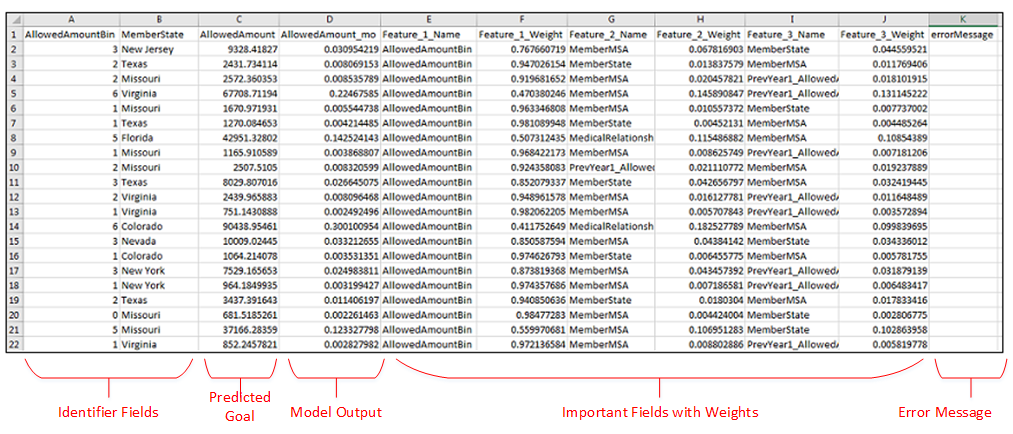
• Identifier Fields – These fields can be added to a scoring job to help identify specific results. They are output in the results with the parameter names you configure in the scoring job.
• Predicted Goal – The predicted value of the goal variable for a specific result record. This column represents the predicted value after the model output has been denormalized or transformed.
• Model Output – The PMML score for the predicted goal, before the value is denormalized or transformed. A suffix of _mo is attached to the column name to identify it as the raw model output score. The meaning of the model output information varies based on the OpType of the goal variable:
◦ Boolean – The model output score indicates an estimated probability that the value is true. However, in several scenarios this value cannot be considered a true probability.
Depending on the model type, you might see _mo values that are greater than one or less than zero. An output transformation converts this value to a predicted goal of true or false.
◦ Continuous – The model output score is simply a normalized goal value. Because the underlying model trains on normalized data the scoring process outputs normalized prediction scores. An output transformation denormalizes this value to report a predicted goal using the original scale.
◦ Categorical – The model output score reports an estimated probability for each available category. As with Boolean data, the model output score may not represent true category probabilities.
Depending on the model type, you might see _mo values that are greater than one or less than zero. An output transformation selects the most probable category as the predicted goal value. This OpType is not available for use in Analytics Builder.
◦ Ordinal – For model training purposes, an ordinal goal (such as xs, s, m, l, xl) is treated like a continuous variable. The model output score represents a normalized version of the goal value. An output transformation converts this value to a predicted goal value using the original ordinal categories. This OpType is not available for use in Analytics Builder.
• Important Fields – The important fields represent which fields have the most influence on the value of the goal variable in each result record. The number of important fields returned is determined by the value you enter in the Return Number of Important Fields parameter when you configure the scoring job.
• Important Field Weights – For each important field, a field weight represents the relative impact of that field on the goal variable. If the field weights for all the fields in a set of training data could be added together for one record, the sum would equal 1. In the sample results shown below, the weights for the important fields across each row sum up to something slightly less than one.
• Error Message – This column displays any errors that occur while trying to score a specific record.
The following sample results were output from an asynchronous predictive scoring job as a CSV string. The scoring job included two identifier fields and three important fields. In the figure below, the results have been opened in an Excel spreadsheet.