永続化プロバイダとしての DataStax Enterprise の使用
概要
|
|
ThingWorx Platform バージョン 8.5.0 より、DSE は販売されなくなり、今後のリリースでサポートされません。詳細については、
販売終了に関するアーティクルを参照してください。
|
モデルが大きなデータスケーラビリティを必要とする場合、ThingWorx での拡張機能のインポートによって、DataStax Enterprise (DSE) を
永続化プロバイダとして使用できます。拡張機能 DsePersistenceProviderPackage.zip は、Solr サーチエンジンが統合されている、Cassandra の DataStax Enterprise エディション (Open Source/Community Edition ではない) を使用するよう構築されています。DSE は Apache Cassandra 上に構築されているビッグデータプラットフォームであり、リアルタイムのアナリティクスおよびエンタープライズサーチデータを管理します。
Cassandra はスケーラブルなオープンソースの NoSQL データベースであり、複数のデータセンターやクラウド間の大量のデータを管理できます。Cassandra では、単一障害点なしで、多数のコモディティサーバー間で継続した可用性、線形スケーラビリティ、運用の簡易性が実現されるとともに、フレキシビリティを最大化して応答時間を短縮するよう設計されたパワフルなデータモデルが提供されています。
|
|
DSE を使用するためには、DSE を登録、インストール、設定する必要があります。このプロセスのほとんどは ThingWorx から独立して実行し、これについてはここに説明があります。
|
DataStax Enterprise の展開を計画するにあたっては、最初にそのアーキテクチャについて、特に、通常のリレーショナルデータベースとの違いについて理解しておく必要があります。Cassandra に不慣れな場合は、DataStax Academy によって提供されている無料のオンラインコースを最初に受講することをお勧めします。具体的には次のとおりです。
以下のセクションではいくつかの具体的な内容について学習できます。
•
http://datastax.com/documentation/cassandra/2.0/cassandra/architecture/architecturePlanningAbout_c.html
DSE および ThingWorx の開始にあたっての全体像
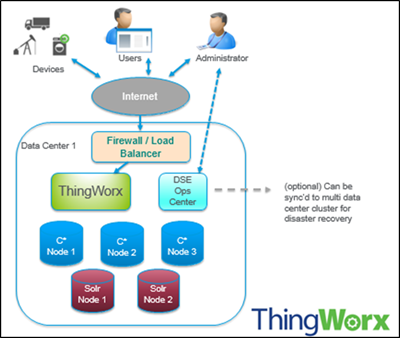
このドキュメンテーションでは、DSE の設定に関して以下の用語が使用されます。
• ノード - データを保管する場所。これは Cassandra の基本的なインフラストラクチャコンポーネントです。
• データセンター - 関連ノードのコレクション。データセンターは物理的なデータセンターの場合と仮想データセンターの場合があります。ワークロードごとに別個の (物理的または仮想) データセンターを使用する必要があります。レプリケーションはデータセンターごとに設定されます。別個のデータセンターを使用することで、Cassandra のトランザクションがほかのワークロードの影響を受けなくなり、リクエストが狭い間隔を維持することで遅延が少なくなります。レプリケーション係数に応じて、データを複数のデータセンターに書き込むことができます。ただし、データセンターが複数の物理的な場所にまたがっていてはなりません。
• クラスタ - クラスタには 1 つ以上のデータセンターが含まれています。これは複数の物理的な場所にまたがっていても構いません。
ThingWorx での DSE の実装プロセスの概要
1. DSE が自分のデータに適したソリューションであるかどうかを判断します。詳細については、サイジングとプランニングのセクションを参照してください。
2. DSE を登録してインストールします。
このプロセスは ThingWorx から独立して実行します。展開例が用意されています。
3. DSE 永続化プロバイダの拡張機能を ThingWorx にインポートします。
4. ThingWorx で DSE データストアを接続する永続化プロバイダインスタンスを作成します。
5. ThingWorx で永続化プロバイダの設定を行います。設定の詳細を以下の表に示します。
ストリーム、値ストリーム、データテーブルで、バケット設定を行えます。これらの設定は DSE 永続化プロバイダのインスタンスコンフィギュレーションをオーバーライドします。 |
名前 | デフォルト値 | 説明 | ||
|---|---|---|---|---|
接続情報 | ||||
Cassandra クラスタホスト | 192.168.234.136,192.168.234.136 | Cassandra クラスタの IP アドレス。Cassandra クラスタをインストールするための DSE のセットアップ中に設定された IP アドレスまたはホスト名。 | ||
Cassandra クラスタポート | 9042 | Cassandra クラスタをインストールするための DSE のセットアップ中に設定された Cassandra クラスタのポート。 | ||
Cassandra ユーザー名 | 該当なし | クラスタでの認証を有効にしない場合は、オプションです。有効にする場合、このフィールドは必須です。
| ||
Cassandra パスワード | 該当なし | クラスタでの認証を有効にしない場合は、オプションです。有効にする場合、このフィールドは必須です (上記を参照)。 | ||
Cassandra キースペース名 | thingworxnd | ThingWorx データの保存場所。リレーショナルデータベースのスキーマとほぼ同じです。
| ||
Solr クラスタ URL | http://localhost | データテーブルが使用されている場合、Cassandra クラスタをインストールするための DSE のセットアップ中に設定された IP または完全修飾ホスト名 (ドメインまたは IP 含む) を指定します。 | ||
Solr クラスタポート | 8983 | データテーブルが使用されている場合、Cassandra クラスタをインストールするための DSE のセットアップ中に設定されたポートを指定します。 | ||
Cassandra キースペース設定 | replication = {'class':'NetworkTopologyStrategy', 'Cassandra':1, 'Solr':1} | DSE のセットアップ中に作成された Cassandra クラスタのコンフィギュレーションによって異なります。主に、使用されるデータセンターと関連するレプリケーションファクタを定義します (詳細については
http://datastax.com/documentation/cql/3.1/cql/cql_reference/create_keyspace_r.html を参照)。管理者がキースペースを手動で作成した場合、手動で作成されたキースペース設定とこれらの設定が一致している必要があります。 | ||
Cassandra 一貫性レベル | {'Cluster' : { 'read' : 'ONE', 'write' : 'ONE' }} | ノード数に関する読み取りと書き込みの一貫性レベル。
| ||
CQL クエリー結果の制限 | 5000 | Cassandra Query Language クエリー結果の制限では、データをクエリーしたときに返される行数を指定します。これにより、大きな結果セットが返されることによってプラットフォームでパフォーマンスの問題が発生することがなくなるので、ThingWorx の安定性が向上します。 | ||
接続を動作中として保持 | true | Cassandra クラスタに接続された状態を維持します。非アクティブな接続が切断される可能性があるファイアウォール越しの接続で特に有用です。
| ||
接続タイムアウト (ミリ秒) | 30000 | 初期接続タイムアウト (単位: ミリ秒)。ThingWorx と Cassandra クラスタの間のネットワーク待ち時間に基づきます。 | ||
圧縮アルゴリズム | none | ThingWorx がクラスタにデータを送信する場合、以下の 3 つのオプションがあります。 • Lz4 圧縮 • Snappy 圧縮 • 圧縮なし ThingWorx と Cassandra クラスタの間のネットワーク帯域幅が狭い場合、圧縮によってスループットが向上します。
| ||
クエリーの最大再試行数 | 3 | クエリーで実行可能な最大再試行数。デフォルトは 3 です。 | ||
ローカルコア接続 | 4 | データを読み書き可能な接続の最小数。 | ||
ローカル最大接続 | 16 | データを読み書き可能な接続の最大数 | ||
リモートコア接続 | 2 | データを読み書き可能なリモート接続の最小数。 | ||
リモート最大接続 | 16 | データを読み書き可能なリモート接続の最大数 | ||
トレースを有効化 | false | ログ作成。デバッグの際に有効にできます。 | ||
最大非同期リクエスト | 1000 | |||
クラシックストリームの設定 | ||||
キャッシュ初期サイズ | 10000 | 初期キャッシュサイズ。これはソースの数に基づきます。
| ||
キャッシュ最大サイズ | 100000 | 最大キャッシュサイズ。メモリ使用量を制御します。 | ||
キャッシュ同時実行 | 24 | 同時にアクセス可能なスレッドの数。最小値には「リモート最大接続」に設定されている値を反映する必要があります。 | ||
クラシックストリームのデフォルト | ||||
ソースのバケット数 | 1000 | ソースをバケットに配置できます。ソースの数は、実行する必要があるクエリーの数と等しくなります。たとえば、100,000 個のソースがある場合、使用されるバケットの数をこのフィールドで指定します。
| ||
時間に基づくバケットサイズ (時間) | 24 | バケットを作成する時間 (単位: 時間)。ソースのバケットサイズがどのように設定されているかに基づきます。たとえば、「時間に基づくバケットサイズ」が 24 に設定されている場合、バケットは 24 時間ごとに作成されます。200 万データポイントを超えないようにすることが目標です。このため、値ストリームまたはクラシックストリームあたりのデータ取得レート (R/秒) に基づいて次の式を使用して求めます: 時間に基づくバケットサイズ = 200 万/(R * 60 * 60)
| ||
データテーブルのデフォルト | ||||
データテーブルのバケット数 | 3 | データテーブルを複数のバケットに分割できます。これにより、データテーブルを複数の DSE ノードに分散させることができます。負荷に応じてノード数が増えたときにデータが分散されるように、クラスタ内のノードの数より大きい値を設定することをお勧めします。考慮すべきその他の要因として、データテーブルで想定される行数があります。バケットあたり 200,000 行に制限するようにしてください。ここでの設定はデフォルトです。バケット数はデータテーブルごとに指定できます。
| ||
値ストリームの設定 | ||||
キャッシュ初期サイズ | 10000 | 初期キャッシュサイズ。これはソースの数にソースのプロパティの数を掛け合わせた値に基づきます。 | ||
キャッシュ最大サイズ | 100000 | 最大キャッシュサイズ。メモリ使用量を制御します。 | ||
キャッシュ同時実行 | 24 | 同時にアクセス可能なスレッドの数。 | ||
値ストリームのデフォルト | ||||
ソースのバケット数 | 1000 | ソースをバケットに配置できます。ソースの数は、実行する必要があるクエリーの数と等しくなります。たとえば、100,000 個のソースがある場合、使用されるバケットの数をこのフィールドで指定します。
| ||
プロパティのバケット数 | 1000 | バケット数は、値ストリームのプロパティの数とクエリーパターンに基づきます。複数のプロパティにまたがるクエリーがある場合、バケットサイズを小さくすることで最適なパフォーマンスが得られます。 | ||
時間に基づくバケットサイズ (時間) | 24 | バケットのサイズ。ソースのバケットサイズがどのように設定されているかに基づきます。たとえば、「時間に基づくバケットサイズ」が 24 に設定されている場合、バケットは 24 時間ごとに作成されます。
| ||
6. 必要な場合、エンティティとデータをマイグレーションします。
7. DSE の実装を監視および保守管理します。適切なメンテナンス計画を作成するための最良事例についてはここに説明があります。