範例 2:少量物件、少量內容與高寫入頻率
情境
範例 2 的高層級情境概觀
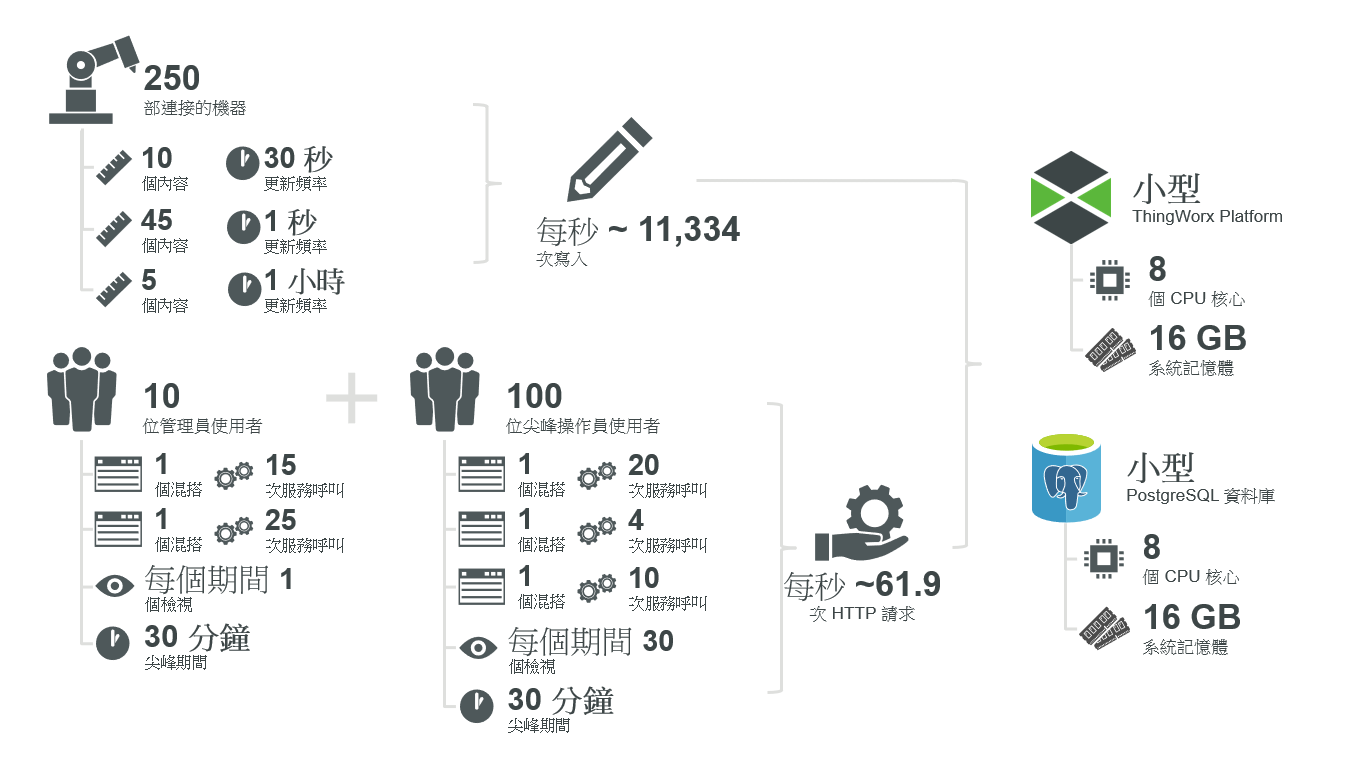
一個中等規模的工廠,有 250 部受監視的機器,每一部都會以不同的速率將 60 個內容更新傳送至 ThingWorx (請參閱需求)。
尖峰使用期間為 30 分鐘長,其間 100 位使用者會對 5 個具唯一性的混搭進行不同數目的呼叫,每一個都有不同的服務數。此組態使用 PostgreSQL 資料庫。
需求
• 物件數 (T):250 個物件
• 內容數 (P,每個裝置上有三個不同的內容群組):
P1 | P2 | P3 |
|---|---|---|
10 個內容 | 45 個內容 | 5 個內容 |
• 寫入頻率 (F):
F1 | F2 | F3 |
|---|---|---|
每 30 秒 (每天 2,880 次) | 每秒 (每天 86,400 次) | 每小時 (每天 24 次) |
• 尖峰使用期 (t) = 30 分鐘,或 1800 秒
• 混搭數 (M):5 個混搭
• 使用者數 (UM):
UM1 | UM2 | UM3 | UM4 | UM5 |
|---|---|---|---|---|
100 位使用者 | 100 位使用者 | 100 位使用者 | 10 位使用者 | 10 位使用者 |
註記:具有較少使用者請求數的混搭對管理使用者而言是常見的 | ||||
• 每個混搭的服務數 (SM):
SM1 | SM2 | SM3 | SM4 | SM5 |
|---|---|---|---|---|
20 個服務 | 4 服務 | 10 個服務 | 15 個服務 | 25 個服務 |
• 使用者載入每個混搭的次數 (LM):
LM1 | LM2 | LM3 | LM4 | LM5 |
|---|---|---|---|---|
30 次 | 30 次 | 30 次 | 1 次 | 1 次 |
註記:30 次表示在 30 分鐘尖峰期間,每分鐘會重新載入混搭 1、2 與 3,可能是透過自動重新整理來完成。 | ||||
計算
• 資料擷取:
WPS = T × [(P1 × F1) + (P2 × F2) + (P3 × F3)]
= 250× [(10 × 1/30) + (45 × 1) + (5 × 1/3600)]
≈ 11,334 writes per second
= 250× [(10 × 1/30) + (45 × 1) + (5 × 1/3600)]
≈ 11,334 writes per second
這有一點複雜,因為內容是以不同的速率寫入。請記住,您可以將 FD 除以86,400,以在有需要時將其轉換成秒。
也不要忘記計算 CS 值:
CS = T / 100,000
= 250/ 100,000
= 0.0025 Connection Servers
= 250/ 100,000
= 0.0025 Connection Servers
• 資料視覺化:
R = [(SM + 1) × UM × LM ] / t
R1 = [(20 + 1) × 100 × 30 ] / 1800
≈ 35 requests per second
R2 = [(4 + 1) × 100 × 30 ] / 1800
≈ 8.33 requests per second
R3 = [(10 + 1) × 100 × 30 ] / 1800
≈ 18.33 requests per second
R4 = [(15 + 1) × 10 × 1 ] / 1800
≈ 0.09 requests per second
R5 = [(25 + 1) × 10 × 1 ] / 1800
≈ 0.14 requests per second
R = R1 + R2 + R3 + R4 + R5
≈ 61.89 requests per second
R1 = [(20 + 1) × 100 × 30 ] / 1800
≈ 35 requests per second
R2 = [(4 + 1) × 100 × 30 ] / 1800
≈ 8.33 requests per second
R3 = [(10 + 1) × 100 × 30 ] / 1800
≈ 18.33 requests per second
R4 = [(15 + 1) × 10 × 1 ] / 1800
≈ 0.09 requests per second
R5 = [(25 + 1) × 10 × 1 ] / 1800
≈ 0.14 requests per second
R = R1 + R2 + R3 + R4 + R5
≈ 61.89 requests per second
在此情況下,每個混搭都有不同數量的服務,而有些混搭則是由較小的使用者計數所呼叫。此外,有些混搭會每分鐘重新整理一次,而有些混搭則只會載入一次。
在這種情況下,請確定不要忽略 LM。自動重新整理的混搭額外服務呼叫可能會對系統大小設定造成明顯的影響。
雖然此計算有更多部份,但分解每個混搭的等式並新增結果 (如上圖所示) 是很簡單的。
條件比較
• T = 250 ->「超小」平台 (或更大,含 PostgreSQL)
• CS = 0.0025 -> 不需要連線伺服器
• WPS = 11,334 ->「小型」平台大小 (或更大)
• R = 61.89 ->「中型」平台大小 (或更大)
大小設定
假設需要有「中型」ThingWorx 系統才能滿足所有條件,應根據代管類型來考慮下列大小設定:
大小 | Azure VM | AWS EC2 | CPU 核心 | 記憶體 (GiB) |
|---|---|---|---|---|
ThingWorx Platform:中型 | F16s v2 | C5d.4xlarge | 16 | 32 |
PostgreSQL 資料庫:中型 | F16s v2 | C5d.4xlarge | 16 | 32 |
比較計算與觀察的結果
針對範例 2,模擬會模仿具有多個混搭的實際應用程式,以不同的重新整理速率發出各種服務呼叫,並透過模擬的遠端物件將資料以不同速率傳送至平台。
從基礎結構的角度來看,平台執行地很好,平均為 34.8% 的 CPU 使用率及 3.1 GB 的記憶體耗用。PostgreSQL 平均為 35.1% 的 CPU 使用率及 8.1 GB 的記憶體。
從平台的角度來看,HTTP 請求率平均為每秒 63 次運算,符合預期的 62 OPS,而每秒「值串流佇列」寫入次數在實際情況下可穩定保持在約 12k WPS,接近預期的 11.3k WPS 以上。
從範例 2 的模擬部署中觀察到的結果
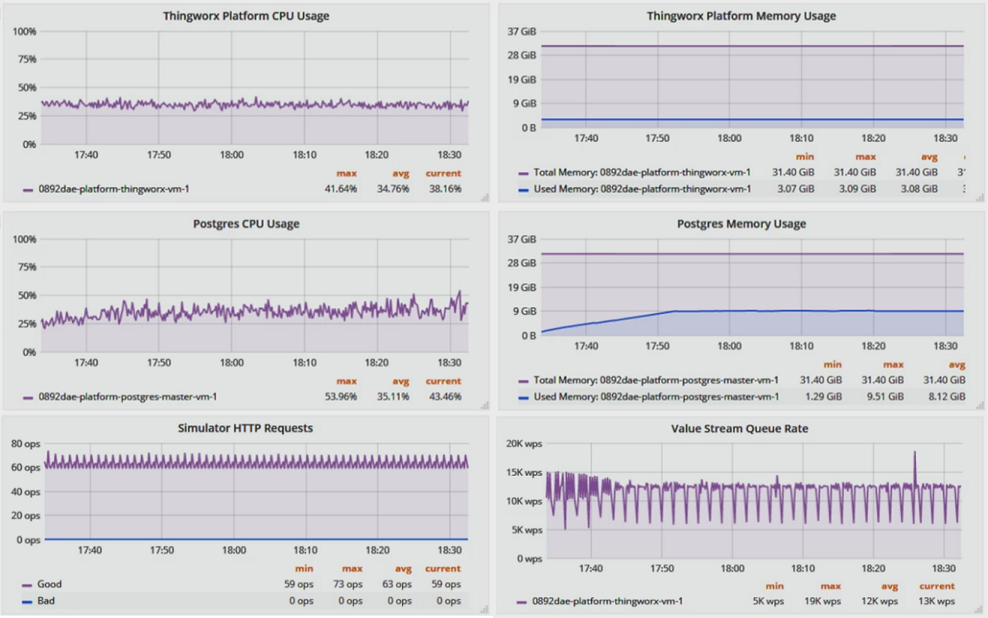
從應用程式或使用者的角度來看,裝置或使用者模擬器看不到任何錯誤、效能問題或不良請求/回應。所有新請求都已及時處理。
如以上圖表所示,針對模擬、穩定狀態的工作負載以及更符合真實情況的裝置與/或使用者活動中的峰值,實行都有足夠的資源可以備用。