資料視覺化
有關從企業應用程式中的使用者經驗 (混搭) 產生之伺服器負載的視覺化焦點系統需求。
與擷取非常相似,來自視覺化的負載不僅取決於混搭的數量,還取決於每個混搭的複雜度,以及預期存取這些混搭的同步使用者數。
|
t
|
尖峰使用者存取期間:呼叫下列混搭與服務的時間長度 (以秒為單位)。
|
|
M
|
具唯一性的混搭:在該期間,使用者預期會存取的具唯一性混搭數。
|
|
SM
|
每個混搭的服務:針對每個具唯一性的混搭,確定呼叫的服務數。
|
|
UM
|
同步使用者數:在此期間,預期同時使用這些混搭的總使用者數。
|
|
LM
|
每個混搭的使用者負載次數:每個個別使用者預期在一段期間存取該混搭的次數。
一般而言,這將始終為至少一次,但請特別注意開啟自動重新整理的混搭。
|
透過這些值,每秒的總 HTTP 請求數 (R) 可確定為每個使用者在該期間內請求的混搭服務呼叫總數 (針對混搭本身加一):
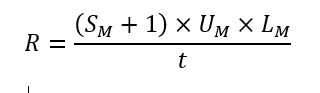
例如,在應用程式中有 3 個具唯一性的混搭 (M),且具有下列參數:
• 尖峰使用者存取時間是一小時長 (t = 3,600 秒)
• 兩個混搭每個會進行 10 次服務呼叫 (S1 和 S2 = 10)
• 第三個混搭會進行 20 次服務呼叫 (S3 = 20)
• 第一個混搭將每小時由 1,000 個使用者存取 (U1 = 1000)
• 其他兩個混搭將每小時由 100 個使用者存取 (U2 和 U3 = 100)
• 任何混搭都不會進行超出此範圍的自動或手動重新整理,這描述了最終使用者在分配的時間範圍內 (在一小時內) 一次耗用一個提供的資訊。
(L1、L2 與 L3 = 1)
計算結果將為:
R = [(SM + 1) × UM × LM ] / t
R1 = [(S1 + 1) × U1 × L1] / t
= [(10 + 1) × 1000 × 1] / 3600
≈ 3.06 requests per second
= [(10 + 1) × 1000 × 1] / 3600
≈ 3.06 requests per second
R2 = [(S2 + 1) × U2 × L2] / t
= [(10 + 1) × 100 × 1] / 3600
≈ 0.31 requests per second
= [(10 + 1) × 100 × 1] / 3600
≈ 0.31 requests per second
R3 = [(S3 + 1) × U3 × L3] / t
= [(20 + 1) × 100 × 1] / 3600
≈ 0.61 requests per second
= [(20 + 1) × 100 × 1] / 3600
≈ 0.61 requests per second
R = R1 + R2 + R3
≈ 3.06 + 0.31 + 0.61
≈ 3.98 requests per second
≈ 3.06 + 0.31 + 0.61
≈ 3.98 requests per second
同樣地,在此情況下,具有簡單資料庫的超小 ThingWorx 系統 (例如 H2) 應可處理此負載,但不建議針對生產使用這樣做。
大多數計算都會更加複雜,可能會有更多具唯一性的混搭,每個都有比此處更多的服務呼叫和同步使用者。
涉及這些計算的範例在此處提供。