ThingWorx Foundation 部署组件
ThingWorx 组件的部署需要考虑三个层 - 客户端、应用程序和数据。下图所示为任何一个 ThingWorx 解决方案的基本起点:
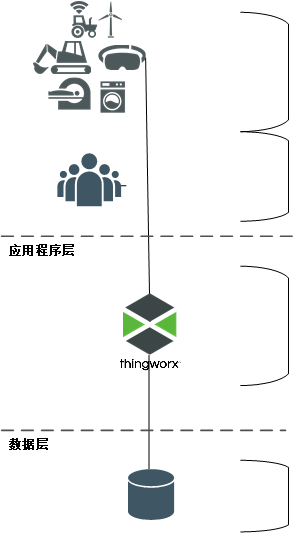 |
事物/设备:该层包含的事物、设备、代理和其他资产可连接至 ThingWorx 平台并向其发送数据和接收内容。
用户/客户端:该层包含了用于访问 ThingWorx 平台的产品 (主要为 Web 浏览器)。
|
|
平台:平台层 (或称应用程序层) 是 ThingWorx Foundation 的所在层,可充当 ThingWorx 系统的中心。该层可提供同客户端层的连接、执行身份验证和授权检查、引入/处理/分析内容以及对发送警报等条件作出响应。
|
|
|
数据库:数据库层负责维护 ThingWorx 运行时模型元数据和系统数据:
• 模型元数据包括 ThingWorx 实体定义、事物定义及其关联的属性定义。
• 针对 ThingWorx 模型引入的运行时数据。数据可以是表格或时间序列数据,这些数据由 ThingWorx 模型保存为博客、Wiki、流、值流和数据表中的内容行。
|
随着 ThingWorx 解决方案在功能和复杂性方面的提高,每个层的结构需求也随之提高。
以下各部分将对组件运行所在层的 ThingWorx 解决方案的每个组件进行一一介绍。
用户/客户端组件
用户或客户端可通过 ThingWorx Composer 或运行时混搭访问 ThingWorx 平台,这必须使用支持 HTML/HTML5 的现代浏览器 (例如:Microsoft Edge、Firefox、Safari 或 Chrome)。
事物/设备组件
• ThingWorx Edge MicroServer - ThingWorx Edge MicroServer (EMS) 与需要通过 Internet 连接到 ThingWorx 服务器的 Edge 设备或数据存储一同使用。它可使得防火墙后方的设备和数据存储能够与 ThingWorx 服务器进行安全通信,并且是解决方案环境中的完整参与者。ThingWorx EMS 不仅是简单的连接器,而且允许对要移动到 Edge 的数据进行智能化和预处理。
• ThingWorx Edge SDK - ThingWorx Edge SDK 是类、对象、函数、方法和变量的集合,用于提供框架来创建可从 Edge 设备安全地向 ThingWorx 平台发送数据的应用程序。ThingWorx Edge SDK 可提供适用于有经验的 C 语言、.NET 和 Java 编程语言开发人员的工具。
ThingWorx EMS 和 ThingWorx Edge SDK 支持通过代理进行连接。代理配置管理以及相关更改管理的流程可能会因为客户和/或项目不同而有所不同。ThingWorx Edge SDK 可提供极大的灵活性,因为 SDK 库可包含在任何自定义 Edge 组件内或由其参考,因此,可根据解决方案设计需要进行更新。
平台组件
• ThingWorx Connection Server - ThingWorx Connection Server 是一种服务器应用程序,可促进远程设备的连接,并处理路由至设备或源自设备的所有消息。ThingWorx Connection Server 通过使用 ThingWorx AlwaysOn 通信协议的 Websocket 提供可扩展连接。PTC 建议在资产数量超过 25,000 的情况下使用连接服务器,以分担 ThingWorx Foundation 服务器中的管理连接。高可用性配置中需要使用连接服务器,以在主动群集节点之间分布设备连接。此外,PTC 还建议针对每 100000 个同时连接到 ThingWorx Foundation 服务器的连接,至少提供一个连接服务器。设备与连接服务器的这一比率可能会受多种不同因素的影响而发生变化,例如:
◦ 设备的数量
◦ 设备的写入提交频率
• Tomcat - Apache Tomcat 是由 Apache Software Foundation (ASF) 开发的开源 servlet 容器。Tomcat 实现了 Oracle 公司的 Java Servlet 和 Java Server Pages (JSP) 规范,并提供了用于 Java 代码运行的纯 Java HTTP Web 服务器环境。
• ThingWorx Foundation 服务器 - ThingWorx Foundation 为机器到机器 (M2M) 和 IoT 应用程序提供了完整的设计、运行时和智能环境。ThingWorx Foundation 旨在有效地构建、运行和扩展可控制和报告远程资产数据的应用程序,其中远程资产为连接的设备、机器、传感器和工业设备。
ThingWorx Foundation 将用作 ThingWorx 环境的集线器。它还包括一些工具集,您可借助此类工具集开发用于定义环境中所部署远程资产 (或设备) 的行为以及资产之间关系的应用程序。
资产建模完成后,即可进行注册并与 ThingWorx Foundation 通信,从而可用于监控和管理物理设备并收集其中的数据。
数据库组件
ThingWorx 平台提供的插入式数据存储模型可让每个客户选择最适合其需求的数据库,范围涵盖用于演示目的小型实施、高可用性的培训环境、支持每秒处理数千项事务的大容量数据库。
已将值流、流、数据表、博客和 wiki 定义为 ThingWorx 的数据提供工具。数据提供工具被视为存储运行时数据的数据库。运行时数据是指组成事物后所保留的数据,而且可由所连接的设备用来存储其数据 (例如温度、湿度或位置)。模型提供工具用于存储有关事物的元数据。
持久化方案提供工具可以包含数据提供工具和/或模型提供工具。
有关数据库选项的详细信息,请参阅持久化方案提供工具。
高可用性组件
高可用性是有关业务连续性的关键因素。高可用性组件必须在应用程序和数据库层同时应用才会生效。
从 9.0 版本开始,可将 ThingWorx 部署到通过多个主动服务器节点处理业务逻辑和用户请求的群集配置中。此配置将取代先前版本中提供的主动-被动故障转移配置。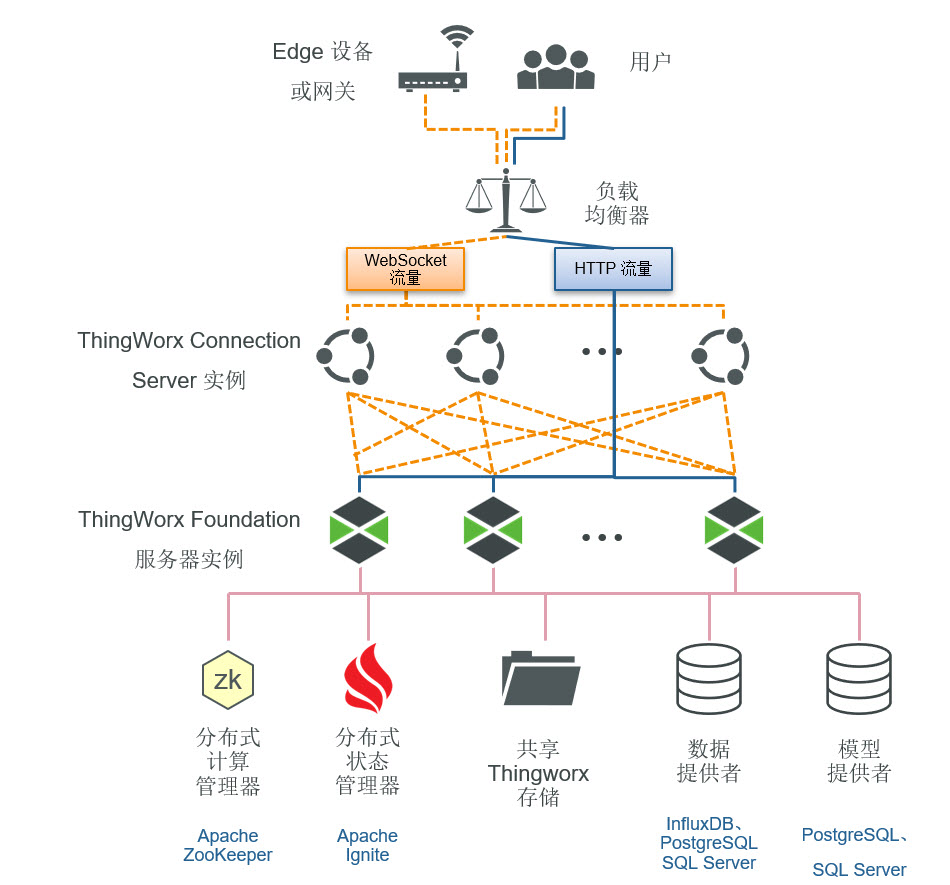
在群集配置中,需要使用连接服务器在主动群集节点之间分布设备连接。
ThingWorx 应用程序层需要 Apache ZooKeeper 和 Apache Ignite 作为附加组件。高可用性数据库层需求取决于所选数据提供工具的需求。
与软件堆栈实际正常运行相比,高可用性需要考虑的因素更多。它还应该评估冗余基础设施,如电源、硬盘和网络基础设施 (路由器、负载平衡器、防火墙等)。 |
• ZooKeeper - Apache ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步以及提供分组服务。它是适用于分布式应用程序的协调服务,其中分布式应用程序可在整个群集内进行同步。对于 ThingWorx 而言,ZooKeeper 用于监控群集节点的可用性,并在出现故障时选择一个新的 ThingWorx Foundation 主导节点。
• Ignite - Apache Ignite 是一种开源分布式数据库、缓存和处理平台,旨在跨节点群集存储和计算大量数据。在群集 ThingWorx 部署中,Ignite 用于存储和维护群集中所有节点上设备数据的共享缓存。
内存占用量最小的 HA 部署
Ignite 可以嵌入在 ThingWorx Foundation 程序中,而无需单独安装。嵌入式 Ignite 应该仅在环境足迹的重要性高于性能时使用。应将其用于仅需要高可用性而无需扩展的小型环境。它不可扩展,且无法解决性能问题。
在嵌入式 Ignite 双服务器方案中,唯一的优势是读取。Ignite 会将一些数据标记为服务器 A 上的主要数据,将一些数据标记为服务器 B 上的主要数据,其他服务器作为这些数据的备份。通常情况下,所有读取都将转至主服务器中的数据。这可能是远程调用,也可能不是。在嵌入式 Ignite 中,主要区别是您可以将从备份读取设置为 true。在这种情况下,读取不会跳跃网络。
可能会写入同一台计算机,也可能不会,这将导致在其他计算机上进行备份。因此,不会提升写入性能。
运行嵌入式 Ignite 可能会降低性能,具体取决于机器的大小。单一服务器 ThingWorx 设置与 HA 群集中的 Ignite 服务器实例有所不同:
• 与平台共享内存。除存储属性内存外,Ignite 还会添加其他队列和其他事物。
• JVM 线程数量有限,可根据 CPU 数量随时启用。Ignite 需要多个线程来处理请求、备份数据以及执行某些异常任务。单一服务器没有此载荷。
• 在 HA 系统中,进入缓存或从缓存中传出的所有对象都将在缓存之内或之外进行序列化,而在单一服务器设置中的 caffeine 缓存层并非如此。
数据库的高可用性功能
• PostgreSQL - ThingWorx 支持使用 PostgreSQL 高可用性作为数据解决方案。高可用性提供了设置单独服务器的选项,以便在主服务器发生故障时捕获数据的读取和写入。有关详细信息,请参阅 PostgreSQL 高可用性。
• SQL Server - SQL Standard Edition 通常适用于生产环境,原因在于它支持生产所需要的大部分功能。对于需要高可用性功能、内存 OLTP 或表和索引分区的生产设置,建议使用 SQL Enterprise Edition。有关详细信息,请参阅 Microsoft SQL Server 高可用性。
• InfluxDB Enterprise - 提供 InfluxDB 数据库的群集版本。群集允许跨节点共享数据以支持高可用性和水平扩展,允许在不同服务器上运行读取和查询以提高整个系统的可扩展性。用户可轻松扩展数据节点的数量以支持新的工作负荷。有关详细信息,请参阅使用 InfluxDB 作为持久化方案提供工具。