Computer Vision
Azure Computer Vision은 개발자에게 이미지를 처리하고 정보를 반환하는 고급 알고리즘을 제공합니다. 이미지를 분석하기 위해 이미지를 업로드하거나 이미지 URL을 지정할 수 있습니다. 처리 알고리즘은 이미지의 콘텐츠를 다양한 시각적 특징에 따라 다양한 방식으로 분석할 수 있습니다. 예를 들어 Computer Vision은 이미지에서 모든 사람 얼굴을 찾을 수 있습니다. 자세한 내용은 Azure Custom Vision을 참조하십시오.
Computer Vision 작업을 사용하면 이미지를 분석하고, 도메인을 기준으로 이미지를 분석하고, 이미지를 설명하고, 이미지의 시각적 특징과 특성에 대한 인사이트를 감지하고 제공할 수 있습니다.
이미지가 다음 요구사항을 충족하는지 확인합니다.
• JPEG, PNG, GIF 또는 BMP 형식입니다.
• 파일 크기가 4MB보다 작습니다.
• 크기가 50 x 50픽셀과 4200 x 4200픽셀 사이입니다.
• 크기가 10메가픽셀보다 크지 않습니다.
워크플로에 Computer Vision 작업을 사용하려면 다음 단계를 완료합니다.
1. Azure에 있는 Computer Vision 작업을 캔버스에 끌어 놓고 마우스 포인터로 작업을 가리킨 다음  을 클릭하거나 작업을 두 번 클릭합니다. Computer Vision 창이 열립니다.
을 클릭하거나 작업을 두 번 클릭합니다. Computer Vision 창이 열립니다.
을 클릭하거나 작업을 두 번 클릭합니다. Computer Vision 창이 열립니다.2. 필요한 경우 레이블을 편집합니다. 기본적으로 레이블 이름은 작업 이름과 동일합니다.
3. Azure 커넥터 유형을 추가하려면 지원되는 Azure 커넥터 유형을 참조하십시오.
이전에 커넥터 유형을 추가한 경우 적절한 커넥터 유형을 선택하고 커넥터 이름 아래에서 커넥터를 선택합니다.
4. 테스트를 클릭하여 커넥터의 유효성을 검사합니다.
5. 맵 커넥터를 클릭하여 입력 필드를 채우는 데 사용한 커넥터와 다른 커넥터를 사용하여 작업을 실행합니다. 런타임 커넥터 필드에서 유효한 Azure 커넥터 이름을 제공합니다. 맵 커넥터에 대한 자세한 내용은 맵 커넥터 사용을 참조하십시오.
커넥터 유형을 없음으로 선택한 경우 맵 커넥터 옵션을 사용할 수 없습니다.
6. 리소스 그룹 목록에서 Azure 구독에 정의된 적절한 리소스 그룹을 선택합니다.
7. Computer Vision 계정 필드에서 적절한 Computer Vision 계정을 선택합니다.
8. 다음으로 이미지 제공 목록에서 다음 옵션 중 하나를 선택하고 다음을 수행합니다.
◦ URL을 선택하고 이미지 URL 필드에서 공개적으로 액세스할 수 있는 이미지 URL을 지정합니다.
◦ 파일 업로드를 선택하고 이미지 파일 경로 필드에서 이전 작업의 출력을 매핑하여 이미지의 경로를 제공합니다.
9. 특정 서비스 선택 목록에서 수행할 이미지 분석의 종류에 따라 다음 Computer Vision 서비스 중 하나를 선택하고 해당 작업을 수행합니다.
서비스 | 작업 |
|---|---|
이미지 분석 - 이미지에서 다양한 시각적 특징 집합을 추출합니다. | a. 시각적 특징 목록에서 이미지 분석에 사용할 특징을 선택합니다. ◦ 카테고리 - 카테고리 분류에 따라 이미지 콘텐츠를 분류합니다. ◦ 설명 - 완전한 영어 문장을 사용하여 이미지 콘텐츠를 설명합니다. ◦ 색 - 이미지가 흑백인지 또는 컬러인지를 결정하며 컬러 이미지의 경우 주조색과 강조색을 감지합니다. ◦ 태그 - 이미지에 이미지 콘텐츠와 관련된 자세한 단어 목록을 태그로 지정합니다. ◦ 얼굴 - 이미지에 얼굴이 있는지 여부를 감지합니다. ◦ 이미지 유형 - 이미지가 클립 아트인지 선 그리기인지 여부를 감지합니다. ◦ 성인 - 이미지가 음란물인지 또는 이미지가 또는 성적으로 암시적인 콘텐츠를 나타내는지 여부를 감지합니다. ◦ 객체 - 이미지의 다양한 객체를 감지합니다. 시각적 특징을 여러 개 추가하려면 추가를 클릭합니다. 추가한 시각적 특징을 삭제하려면  을 클릭합니다. 을 클릭합니다.b. 세부 정보에서 추가를 클릭한 후 다음 도메인 특정 세부 정보 중에서 포함할 항목을 하나 선택합니다. ◦ 유명 인사 - 이미지에서 감지된 유명 인사를 식별합니다. ◦ 랜드마크 - 이미지에서 주목할 만한 랜드마크를 식별합니다. 세부 정보를 여러 개 추가하려면 추가를 클릭합니다. 추가한 세부 정보를 삭제하려면 을 클릭합니다. |
도메인을 기준으로 이미지 분석 도메인 특정 모델을 적용하여 이미지의 콘텐츠를 인식합니다. | a. 모델 필드에서 이미지를 분석하는 데 사용되어야 할 도메인 특정 모델을 지정합니다. b. 언어 필드에서 출력을 생성할 언어를 선택합니다. 기본적으로 영어가 선택됩니다. |
이미지 설명 - 사람이 읽을 수 있는 완전한 문장으로 이미지 콘텐츠에 대해 설명합니다. | a. 최대 후보 필드에 서비스가 반환해야 하는 최대 후보 설명 수를 입력합니다. b. 언어 필드에서 출력을 생성할 언어를 선택합니다. 기본적으로 영어가 선택됩니다. |
객체 감지 - 이미지에서 객체 감지를 수행합니다. | 조치가 필요하지 않습니다. |
축소판 생성 - 지정된 이미지의 축소판 이미지를 생성합니다. | a. 너비 필드에 축소판 너비를 1에서 1024픽셀 사이의 값으로 지정합니다. 50 이상의 값을 지정하는 것이 좋습니다. b. 높이 필드에 축소판 높이를 1에서 1024픽셀 사이의 값으로 지정합니다. 50 이상의 값을 지정하는 것이 좋습니다. c. 스마트 자르기 목록에서 true를 선택하여 스마트 자르기를 활성화합니다. 스마트 자르기를 활성화하지 않으려면 false를 선택합니다. |
인쇄된 텍스트(OCR) 추출 - 이미지에서 텍스트를 감지하고 인식된 문자를 기계가 읽을 수 있는 문자 스트림으로 추출합니다. | a. 언어 목록에서 이미지의 텍스트 언어를 선택합니다. 기본적으로 알 수 없음이 선택되어 있습니다. b. 방향 감지 목록에서 true를 선택하여 이미지의 텍스트 방향을 감지하고 추가 처리를 수행하기 전에 수정합니다. 서비스가 이미지의 텍스트 방향을 감지하지 않도록 하려면 false를 선택합니다. |
손으로 작성한 텍스트 추출 - 이미지에서 손으로 작성한 텍스트를 추출합니다. | 조치가 필요하지 않습니다. |
태그 이미지 이미지의 콘텐츠와 관련된 태그 목록을 생성합니다. | 언어 필드에서 출력을 생성할 언어를 선택합니다. 기본적으로 영어가 선택됩니다. |
관심 영역 가져오기 - 이미지의 가장 중요한 영역 주위의 경계 상자를 반환합니다. | 조치가 필요하지 않습니다. |
10. 완료를 클릭합니다.
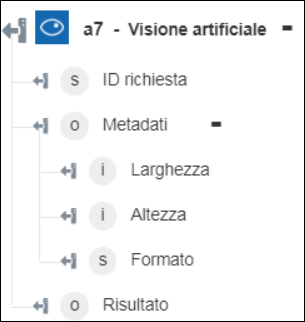
출력 스키마
각 Computer Vision 서비스에는 고유한 출력 스키마가 있습니다.
◦ 이미지 분석 - 선택한 시각적 특징을 반환합니다.
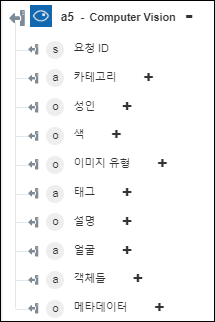
◦ 도메인을 기준으로 이미지 분석 - 이미지에서 인식된 콘텐츠를 반환합니다.
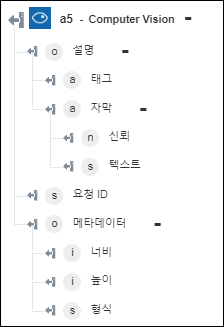
◦ 이미지 설명 - 이미지에 대한 설명을 반환합니다.
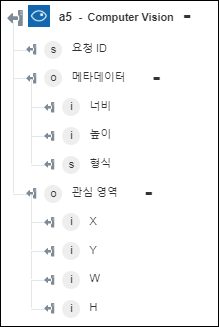
◦ 객체 감지 - 객체 및 해당 좌표를 반환합니다.
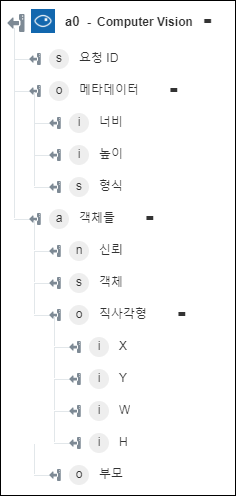
◦ 축소판 생성 - 축소판 이미지를 반환합니다.

◦ 인쇄된 텍스트(OCR) 추출 - 이미지에서 추출된 텍스트를 반환합니다.

◦ 손으로 작성한 텍스트 추출 - 이미지에서 손으로 작성한 텍스트를 추출합니다.
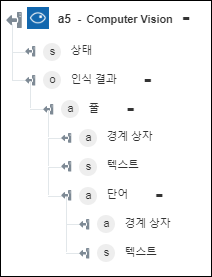
◦ 태그 이미지 - 이미지에 대해 감지된 태그를 반환합니다.
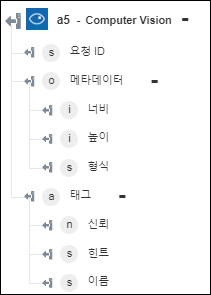
◦ 관심 영역 가져오기는 이미지에서 가장 중요한 영역 주위의 좌표를 반환합니다.