Haute disponibilité ThingWorx
Présentation du clustering haute disponibilité de ThingWorx
Pour réduire la durée des arrêts des systèmes IoT critiques, vous pouvez configurer ThingWorx pour qu'il fonctionne dans un environnement haute disponibilité (HA) en mode cluster. Le clustering offre une évolutivité et une haute disponibilité supplémentaires, en supposant que tous les composants sont configurés correctement.
|
|
Le clustering haute disponibilité ne doit pas être utilisée comme solution de récupération d'urgence.
|
|
|
L'utilisation de plusieurs zones de disponibilité pour un déploiement haute disponibilité n'est pas prise en charge. La latence du réseau entre les zones peut s'avérer trop importante pour une communication constante entre ThingWorx et les noeuds Apache Ignite.
|
Les sections suivantes décrivent l'installation et la configuration d'un environnement de cluster, ainsi que les composants et considérations relatifs à un déploiement de ThingWorx haute disponibilité.
Tous les déploiements haute disponibilité nécessitent des ressources supplémentaires par rapport à un déploiement conçu uniquement pour répondre à des exigences fonctionnelles et de dimensionnement. Ces ressources supplémentaires sont de type matériel (serveurs, disques, équilibreurs de charge, etc.) et logiciel (services de synchronisation et équilibreurs de charge). Les ressources supplémentaires sont ensuite configurées pour s'assurer qu'il n'existe point de défaillance unique dans le déploiement haute disponibilité.
Tous les déploiements haute disponibilité doivent être basés sur un accord de niveau de service (SLA) dans lequel vous avez analysé les exigences de disponibilité de l'application pour votre déploiement. Par exemple, combien d'heures par mois le système peut-il être hors ligne ? Cette période d'indisponibilité est-elle autorisée pour les défaillances système, les mises à niveau d'application ou les deux ? Le nombre de ressources supplémentaires requises pour un système HA dépend du SLA conclu. En général, plus le SLA est exigeant, plus le nombre de ressources requises pour y répondre est élevé.
Glossaire de termes
• haute disponibilité
Système ou composant opérationnel en permanence pendant (de préférence) une longue durée.
• évolutivité
Capacité à augmenter la charge qu'un système peut prendre en charge en augmentant la mémoire, le disque ou le processeur, ou en ajoutant des serveurs.
• cluster
Instances de la même application pouvant fonctionner simultanément. Un cluster offre haute disponibilité et évolutivité.
• singleton
Le serveur singleton désigne un serveur du cluster qui traitera les comportements dans divers clusters, tels que les timers et les planificateurs. Il garantit une exécution unique des tâches dans le cluster.
• adresse IP virtuelle
Adresse IP qui représente une application. Les clients qui utilisent l'adresse IP virtuelle sont généralement routés vers un équilibreur de charge qui dirige ensuite la requête vers le serveur exécutant l'application.
• équilibreur de charge
Périphérique qui reçoit le trafic réseau et le distribue aux applications disponibles.
• basculement
Mode de fonctionnement de secours dans lequel les fonctions d'un composant système (comme un processeur, un serveur, un réseau ou une base de données) sont prises en charge par des composants système secondaires lorsque le composant principal est indisponible en raison d'une défaillance ou d'une période d'arrêt programmée.
• cohérence éventuelle
Les modifications prennent du temps pour se propager à tous les serveurs dans un environnement de cluster. Pour plus d'informations, consultez la rubrique Cohérence éventuelle.
• état partagé
Etat partagé entre plusieurs serveurs du cluster, qui ne change pas, quel que soit le serveur qui l'examine. Les données de propriété sont un exemple d'état partagé, où la valeur de propriété actuelle est la même dans tous les serveurs.
Architecture de référence pour un environnement ThingWorx haute disponibilité
L'image ci-après illustre ThingWorx en configuration de cluster.
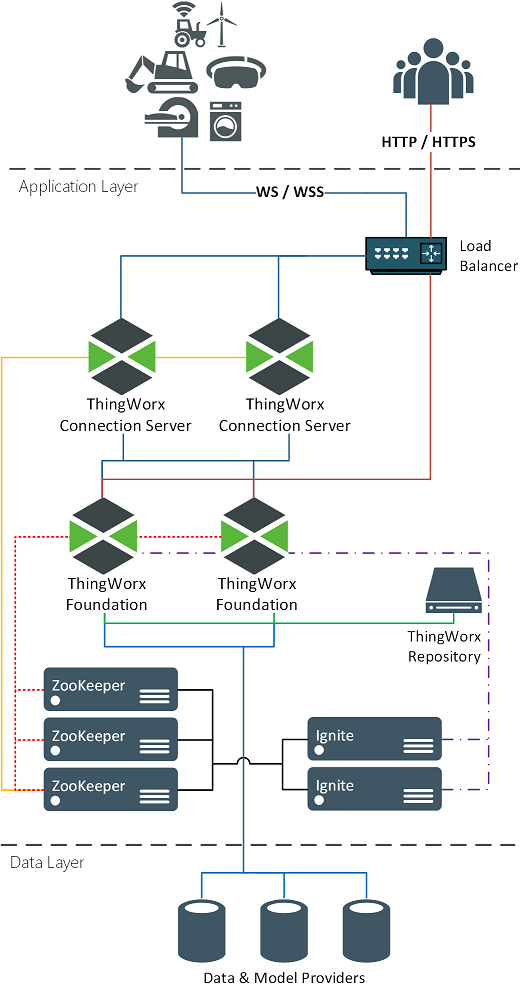
Un déploiement de cluster peut impliquer les composants suivants :
• Utilisateurs et appareils : ces composants ne jouent aucun rôle dans une configuration haute disponibilité. A ce niveau, rien ne change. Les URL et les adresses IP qu'ils utilisent restent inchangées, même en cas de changement de serveur ThingWorx principal.
• Pare-feu : aucune fonction HA ne peut être considérée comme facultative. Les pare-feu sont souvent présents pour répondre aux exigences de sécurité.
• Equilibreurs de charge : les équilibreurs de charge gèrent une adresse IP virtuelle pour l'application qu'ils prennent en charge. Tout le trafic routé vers cette adresse IP virtuelle est dirigé vers l'application active qui peut le recevoir.
• Serveurs de connexion ThingWorx : ces composants reçoivent le trafic de sockets Web des actifs et le routent vers ThingWorx Platform. Les serveurs de connexion peuvent fonctionner dans une configuration de cluster. Une fois dirigé vers un serveur de connexion spécifique, un actif doit toujours l'utiliser. Si ce serveur se déconnecte, l'actif doit être redirigé vers un autre serveur de connexion disponible.
• ThingWorx Foundation : reçoit l'ensemble du trafic des utilisateurs et des actifs.
• Référentiels ThingWorx : il s'agit des emplacements de stockage requis tels que ThingworxPlatform, ThingworxStorage et ThingworxBackupStorage, ainsi que des autres emplacements de stockage ajoutés pour la prise en charge de votre implémentation. Dans le cas d'un environnement de cluster, les dossiers de stockage doivent se trouver dans un emplacement de stockage commun auquel tous les serveurs ThingWorx ont accès.
• Apache ZooKeeper : ZooKeeper est un service de coordination centralisé utilisé par le serveur de connexion ThingWorx et Ignite pour la découverte de services, l'élection du singleton et la coordination distribuée.
• Apache Ignite : Ignite fournit un cache mémoire distribué pour partager l'état entre les serveurs du cluster.
• PostgreSQL : dans une configuration haute disponibilité, PostgreSQL fonctionne via au moins deux noeuds de serveur dans une configuration de serveur de secours (Hot Standby). Un noeud reçoit tout le trafic d'écriture et l'un des autres noeuds peut recevoir tout le trafic de lecture. La réplication en streaming est activée entre tous les noeuds pour que chaque noeud reste à jour.
• Pgpool-II : utilisé uniquement dans les configurations de PostgreSQL haute disponibilité. Les noeuds Pgpool-II reçoivent les requêtes ThingWorx (lecture et écriture) et les dirigent vers le noeud PostgreSQL approprié. Il contrôle également l'intégrité de chaque noeud PostgreSQL et peut lancer le basculement et le reciblage des tâches lorsque l'un des noeuds se déconnecte.
• Microsoft SQL Server (non illustré) : le basculement Microsoft est utilisé pour s'assurer qu'au moins un serveur MS SQL est en ligne et disponible.
• InfluxDB : une implémentation InfluxDB n'est pas requise pour une configuration de cluster ThingWorx. S'il est nécessaire de respecter les exigences d'ingestion de l'implémentation, assurez-vous qu'elle est configurée pour un environnement HA.