Crawler de contenu
Un objet crawler de contenu est utilisé pour appeler un service sur une autre entité. Il permet de récupérer des données et de les stocker dans la table de données de l'objet crawler de contenu.
Sur une entité distincte de l'objet crawler de contenu, vous devez définir un service qui extrait les données et renvoie au crawler de contenu une table d'informations de ces données. Le crawler de contenu mappe ensuite les champs entrants et les tags avec les champs utilisés dans sa forme de données. Chaque ligne est ajoutée en tant que nouvelle entrée à la table de données sur l'objet crawler de contenu. Le fonctionnement de l'index de la table de données du crawler de contenu est similaire à celui d'une entité table de données classique.
Création d'un crawler de contenu
Pour récupérer les données de la table de données d'une entité et les intégrer dans celle de l'objet crawler de contenu, procédez comme suit :
1. Créez une forme de données et définissez les champs à utiliser dans une table de données. Pour créer une forme de données dans Composer, choisissez > , puis cliquez sur le bouton Nouveau.
a. Entrez un nom et une description.
b. Dans la zone Définitions de champ, cliquez sur le bouton Ajouter.
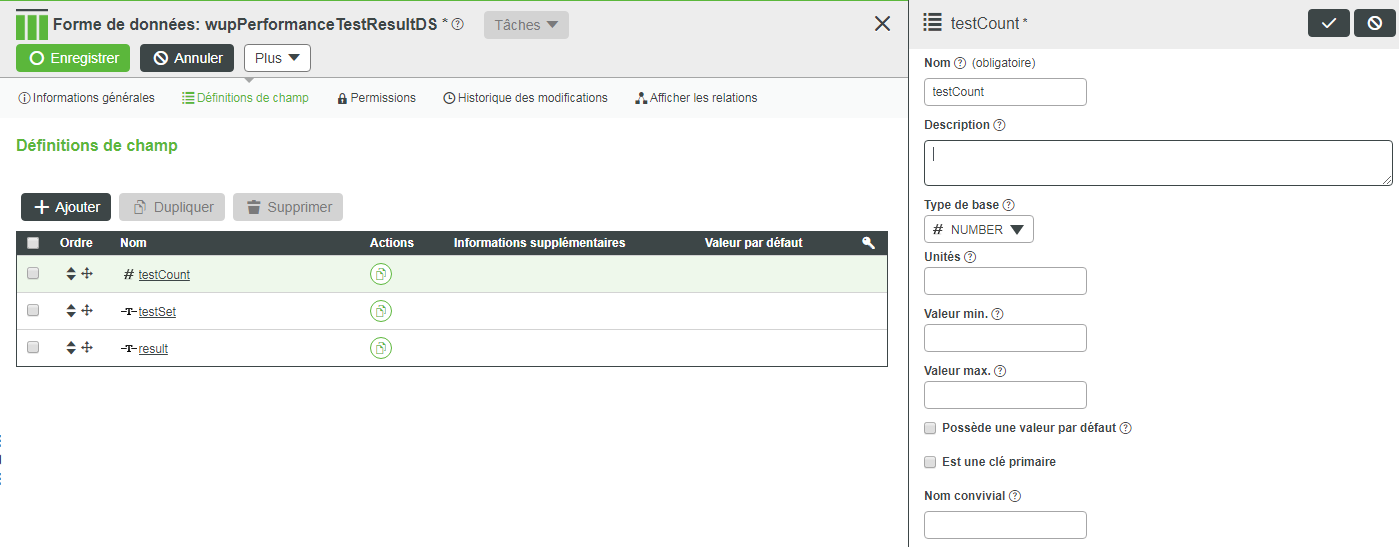
c. Dans le panneau de la nouvelle définition de champ, entrez les informations appropriées, puis cliquez sur  .
.
.2. Créez une table de données avec la forme de données créée à l'étape précédente. Pour créer une table de données dans Composer, choisissez > , puis cliquez sur le bouton Nouveau.
a. Sélectionnez un modèle de table de données, puis cliquez sur OK.
b. Entrez le nom et la description, puis sélectionnez la Forme de données que vous avez créée à l'étape précédente.
c. Dans la zone Services, créez un service personnalisé en cliquant sur Ajouter.
d. Dans la zone Sortie, sélectionnez INFOTABLE dans la liste déroulante.
e. Sélectionnez la Forme de données créée à l'étape précédente.
f. Définissez le Type de table d'informations sur Est une entrée de Crawler de contenu, puis cliquez sur Terminé.
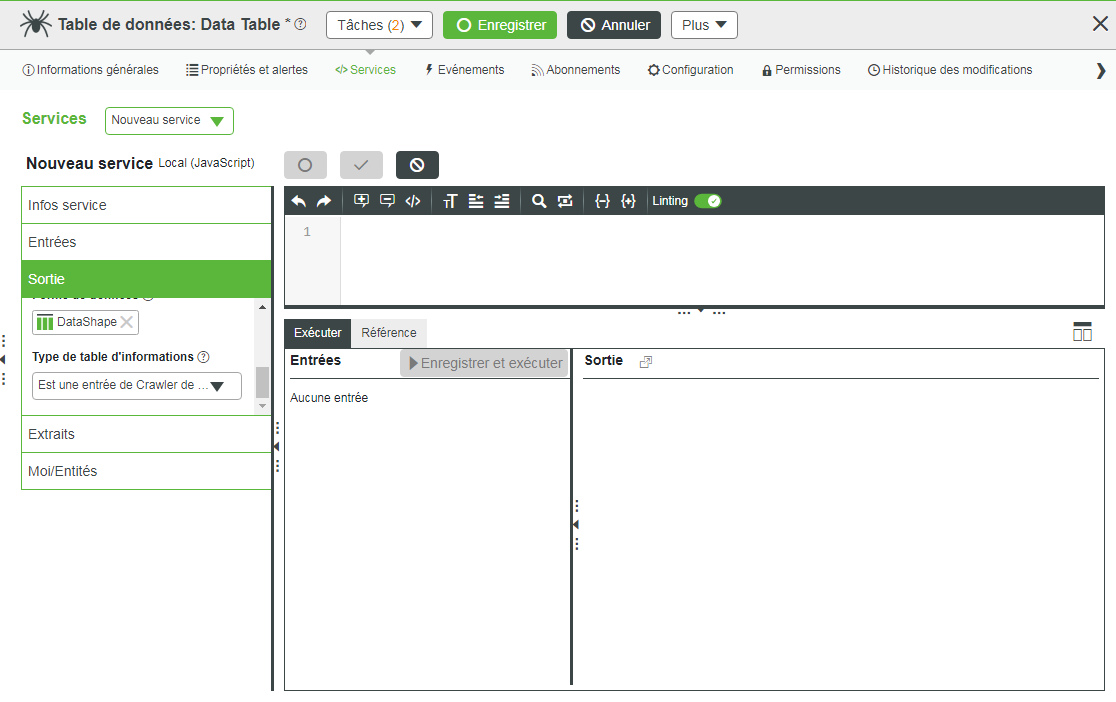
3. Créez une nouvelle forme de données pour l'objet crawler de contenu.
Vous pouvez créer une nouvelle forme de données spécifique au crawler de contenu ou utiliser la forme de données utilisée pour la table de données créée à l'étape 1. Bien que cette étape soit facultative, nous utiliserons dans cet exemple une nouvelle forme de données pour l'objet crawler de contenu. |
a. Créez un nouvel objet crawler de contenu :
i. Dans Composer, choisissez > , puis cliquez sur le bouton Nouveau.
ii. Entrez un nom, puis, dans le champ Modèle d'objet de base, sélectionnez Crawler de contenu.
iii. Dans le champ Forme de données, sélectionnez la forme de données que vous avez créée à l'étape précédente, puis cliquez sur Enregistrer.
Configuration du crawler de contenu
La zone Configuration de l'objet crawler de contenu contient des tables de configuration qui vous permettent de mapper les champs des données récupérées.
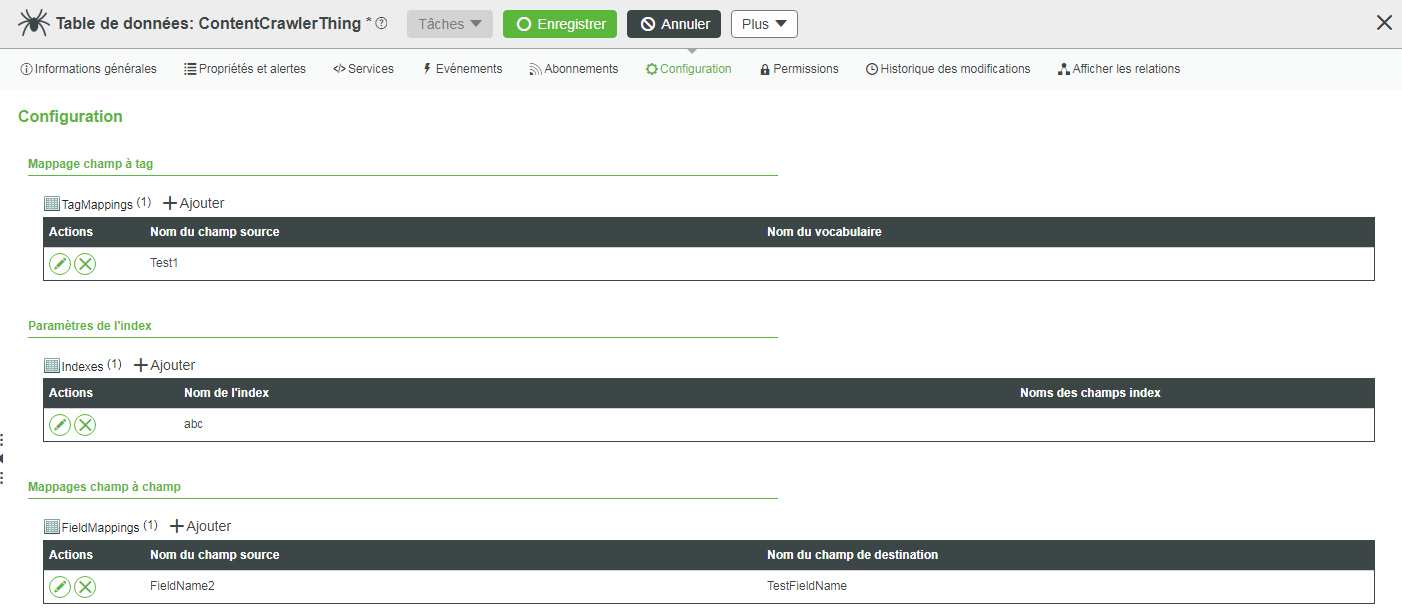
• La table de configuration Mappage champ à tag mappe les valeurs d'un champ avec les tags d'un vocabulaire de tags de données.
◦ Lorsque le vocabulaire de tags de données est dynamique, un terme est automatiquement entré dans le vocabulaire pour toute valeur mappée à partir des données.
◦ Lorsqu'il n'est pas dynamique, toute valeur mappée à partir des données dispose d'un terme prédéfini représentant la valeur à mapper correctement.
◦ Par exemple : TestingVocab:false;TestingVocab:iAmAString. La première partie est la valeur boolProp et la seconde partie est la valeur stringProp.
• La configuration Paramètres de l'index d'une table de données vous permet de définir des index de table supplémentaires. Cela s'apparente à une table de base de données relationnelle où, en plus de la clé primaire (la clé primaire est définie dans la forme de données), vous devez interroger la table selon d'autres champs. Il convient de créer un index pour chaque jeu de critères de filtrage couramment utilisés. Cette approche a une incidence significative sur les performances des requêtes.
• La table de configuration Mappages champ à champ mappe les champs des données récupérées avec ceux définis sur la forme de données de l'objet crawler de contenu.
Si la même forme de données est utilisée sur l'objet crawler de contenu et pour la table d'informations renvoyée par le service de crawler de contenu, le mappage des champs n'est pas nécessaire, celui-ci étant géré automatiquement. |
Services de crawler de contenu
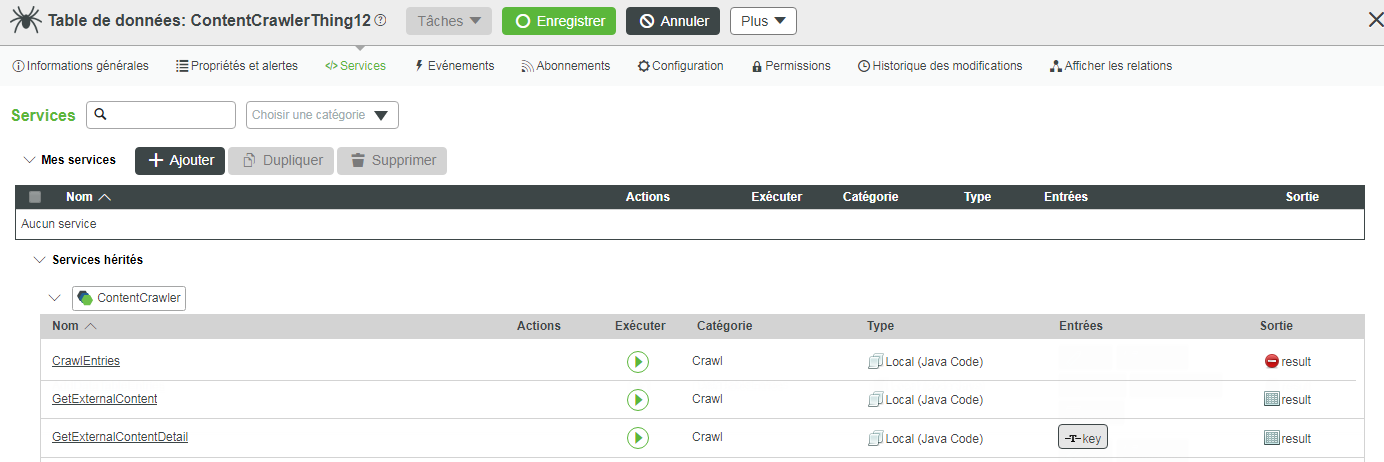
Les services suivants sont spécifiques à l'objet crawler de contenu :
• CrawlEntries : purge toutes les entrées de la table de données pour le crawler de contenu, puis exécute GetExternalContent.
• GetExternalContent : exécute le service défini dans la zone Informations générales de l'objet crawler de contenu. Une table d'informations de valeurs récupérées est renvoyée par le service. La table de données du crawler de contenu n'est pas modifiée.
• GetExternalContentDetail : récupère un élément de contenu spécifique par clé.